
diffusers0.25.0で実装された「3倍高速なSDXL」について調べていた

昨日のGoogle Colabで動くソースはこちら。これはT4 GPU以上で動きました。
https://github.com/aicuai/GenAI-Steam/blob/main/20231228_diffusers0_25_0.ipynb
※ここから先の実験は、80GBのA100が必要です。手元のColabですら試せていませんが以下、HuggingFace公式ドキュメントより。
TextToImage へのDiffusion モデルの推論を高速化
Stability AIの SDXL Turbo で提案されている ADDとも違う手法。
TextToImage の拡散モデルの推論レイテンシーを高速化するために使用できる一連の最適化手法を紹介します。これらはすべて、追加の C++ コードを必要とせずにネイティブ PyTorch で実行できます。これらのテクニックは Stable Diffusion XL (SDXL) に固有のものではなく、他のテキストから画像への拡散モデルを改善するためにも使用できます。 以下に提供される詳細なドキュメントを確認することをお勧めします。
Docs: https://huggingface.co/docs/diffusers/main/en/tutorials/fast_diffusion

Diffusion モデルは、反復的かつ逐次的な逆拡散プロセスのため、GANよりも遅いことが知られています。最近の研究では
・プログレッシブタイムステップ蒸留(LCM LoRAなど)
・モデルの圧縮(SSD-1Bなど)
・ノイズ除去器の隣接する特徴の再利用(DeepCacheなど)
このチュートリアルでは、テキストから画像への拡散パイプラインの推論レイテンシを高速化するためにPyTorch 2のパワーを活用することに焦点を当てます。ケーススタディとしてStable Diffusion XL (SDXL)を使用しますが、これから説明するテクニックは他のテキストから画像への拡散パイプラインにも拡張できるはずです。
セットアップ:diffusersが最新バージョン(>=0.25.0)であることを確認してください。他の必要なライブラリもアップグレードします。
pip install -U diffusers
pip install -U transformers accelerate peft
最速カーネルの恩恵を受けるには、PyTorch nightly を使ってください。インストール手順はここにあります。https://pytorch.org/
以下に示す数字を報告するために、クロックレートを最大に設定した 80GB 400W A100 を使用しました。
このチュートリアルではベンチマークコードを紹介せず、最適化の実行方法に焦点を当てます。完全なベンチマークコードについては、https://github.com/huggingface/diffusion-fast を参照してください。
ベースライン
ベースラインから始めましょう。縮小精度とscaled_dot_product_attentionの使用を無効にします:
from diffusers import StableDiffusionXLPipeline
# Load the pipeline in full-precision and place its model components on CUDA.
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0"
).to("cuda")
# Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]これには7.36秒かかります

bfloat16での推論の実行
最初の最適化を有効にします:推論を実行するために精度を下げます。
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]bfloat16はレイテンシを7.36秒から4.63秒に短縮します

なぜbfloat16?
・(float16やbfloat16のような)精度を下げて推論を実行することは、生成品質に影響を与えませんが、レイテンシを大幅に改善します。
・float16 と比較して bfloat16 の数値精度を使用する利点はハードウェアに依存します。最新世代のGPUはbfloat16を好む傾向があります。
・さらに、私たちの実験では、float16と比較して量子化で使用した場合、bfloat16の方がはるかに耐性があります。 精度を下げて推論を実行するための専用のガイドがあります。
https://huggingface.co/docs/diffusers/main/en/optimization/fp16.md
アテンションの効率的な実行
アテンションブロックの実行には負荷がかかります。しかし、PyTorchのscaled_dot_product_attentionを使えば効率的に実行できます。
https://huggingface.co/docs/diffusers/main/en/optimization/torch2.0.md
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]scaled_dot_product_attentionは待ち時間を4.63秒から3.31秒に改善します。
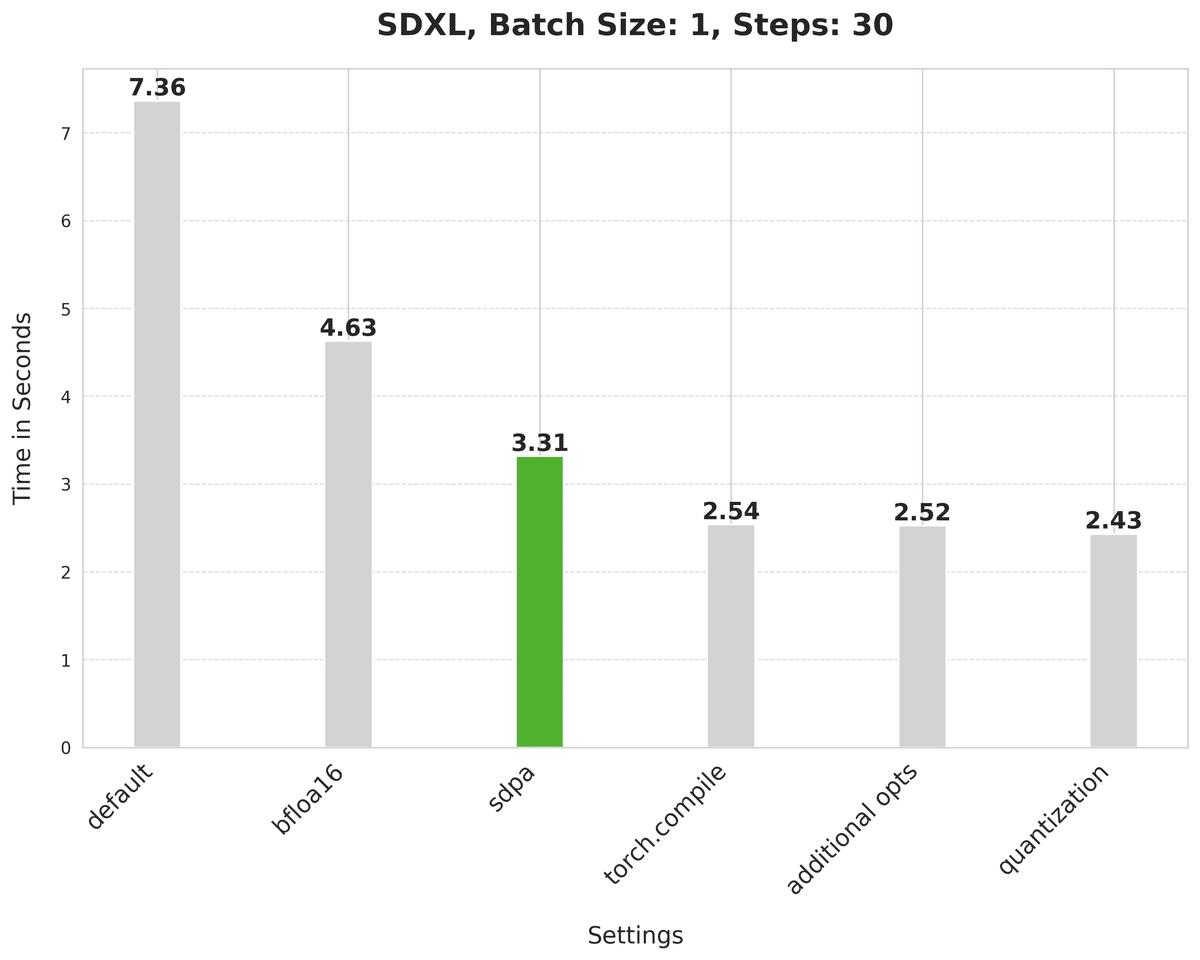
このドキュメントはまだ続く
Use faster kernels with torch.compile
torch.compileで高速カーネルを使用
Combine the projection matrices of attention
アテンションの射影行列の結合
Dynamic quantization
動的量子化

この記事が気に入ったらサポートをしてみませんか?