
音声研究用語「Real Time Factor」で振り返る「つくる人をつくる」の強さ。

昨日「Cotomoがすごい!!」という話を書いたんだけど、
▶AITuberのブレイクスルーは音声雑談から始まった #Cotomo
Cotomoへの感想で気になったやつ
— Dr.(Shirai)Hakase しらいはかせ (@o_ob) February 26, 2024
・ChatGPTなのにすごい→使えないので独自LLMにしたと公式がPRTIMESに書いてる
・知能が云々でつまらない
それは自分にブーメランなやつだ
そろそろ
パケットキャプチャぐらいはしたい気がする#Cotomo @o_ob #note https://t.co/xKnVFF1VZU
パケットキャプチャはリバース・エンジニアリングに近い行為なので、(セキュリティホールを探すとかいう目的でもなければ)自分はそこまでやる必要はないかなと思っていて、まずは『RTFが1.0を切るかどうか』について考えてみればいいかなと思います。
音声研究用語「Real Time Factor」とは
処理対象の音源の再生時間に対する処理に要した時間の割合です。1秒の音源の処理に1秒要した場合、RTF = 1.0です。RTF < 1.0 のとき実時間処理が可能であることを示しています。
音声分野においてリアルタイム性を検証する際に用いられる指標です。
( Real Time Computing - Wikipedia ともいうらしい)
今日の話は前職のインターンの堀部さんが取り組んでくれた研究の回想録です。
▶メタバース企業のインターンが転生したら最強音声研究学生になっていた件。
とりあえず上のブログを読んできてください。話はそれからだ!
要は(スマホアプリでのボイスチェンジャーを作ろうと思ったんだけど、実際のサービスの設計やらUXやらを大きく変えるわけはいかんので)、WebAudioによるサーバ変換型のボイスチェンジャーを作って、その周辺にあるUX関係の問題やら技術課題やらを丁寧に実装レベルからコンピュータ・サイエンス的なアプローチからUX評価レベルまで垂直に研究したんだよ、という話。
さらにつよつよなIntel Xion搭載AWSサーバと、手のひらに乗るスーパーコンピューター「iPhone」シリーズでのベンチマークも実施しています。
▶ボイチェンのFFTをさらに高速化してサーバとiPhoneで比較した話
そしてラボでは「転生こえうらない」でのGCPサーバ版とは別に、iOS実装を開発してあります。ただ作るだけでは実用にはなりませんのでAccelerate FrameworkとWORLDで使用されている大浦FFTのFFT速度比較に関するベンチマークの計測を行いました。社内勉強会でiOS版(WORLDのC++をラップする形のSwift実装)でのベンチマーク結果を共有していたところ、普段AIやデータ分析などを担当するグリーグループの開発本部の橋本さんが「おもしろいね!ちょうどFFTの演算環境があるのですが」と興味をもっていただけたので、つよつよ演算環境である Intel XeonプロセッサAVX-512環境 等とも比較することになりました。いわゆるスパコンなどに使われるベクトル演算おばけですね。いまの「転生こえうらない」も十分高速なのですが、もっと高速になればいろんな表現ができるようになるかもしれません。
当時のiOSテスト環境であった iPhoneXS Max(A12 Bionic)に加え、Intel Xion搭載AWSサーバ、Core i7プロセッサ搭載PCといった環境下において FFTW3 と Math Kernel Library (以下、MKL) に置き換えた場合についても同様にベンチマークを計測しました。またコンパイラとコンパイラオプションの違いによる速度比較も行いました。並列化については比較するためにあえてコードベースでは実施しません(コンパイラの能力だけで比較)。
スパコン用のAPIとスマホアプリ用のAPIを比較するってどういうことや!
という話なんですが、これって実際のアプリ開発、例えばChatGPTとかStable Diffusionのような生成AIアプリだと、Pythonでツルッと作ってしまったりすると思うんですよ。
(1) 某有名API使って作りました!
(2) PoC使ってUX評価しました!
(3) 開発チーム内で評価してみたけどUX良さそうです!やったね!
(4) リリースしてみた!
(5) めっちゃユーザ増えたら大変なことになった!
(6) しかもユーザ増えたら増えただけ、会社が貧乏に!!
みたいな流れになっちゃうんですよね…。
もちろん (4)リリースしてみた!の前に気づけよ!! ってことなんですが。
この研究では、Pythonの下回りのコードをC++に移植した上で、あえてそれを運用コストかかってしょうがないであろうAWSのスパコン環境と、実装コスト大変そうなiOSの低いレベルのFFT実装(自家実装)と、PCでの実装を比較して評価しています。たいへんだ。
iOS AccelerateでのFFT実装についてはこちらにまとめておきました。
▶iOS Accelerateでボイチェン高速化に挑戦したインターン学生の話
2021年のドキュメントか…かなり勉強になる実装なので、Swift勉強とかFFT勉強とか英語のコンピュータサイエンスの勉強したい人にはめちゃオススメです。地獄の一丁目へようこそ!
※Accelerate Frameworkでは独自のデータパッキングを行なっています。基本的なアプローチとしてアプリ開発者側によるデータパッキングが高速化に寄与していると考えられます。
実験結果(抜粋再掲)
こちらは、PC, サーバでの結果にiOSデバイス環境(この実験ではiPhoneXS Maxを使用)での結果(水色)をプロットしたグラフです。ふつうの研究は自分が自慢したい最も高速な環境をそれぞれ可視化するものなので、なかなかサーバとフロントエンドを比較する機会はないと思います。そういう意味では貴重なグラフです。簡単に表現すると「水色の線よりも下側にある部分がiPhone XS Max (A12 Bionic)よりも速いサーバ環境」と読んでいただければだいたい理解としてあっています。
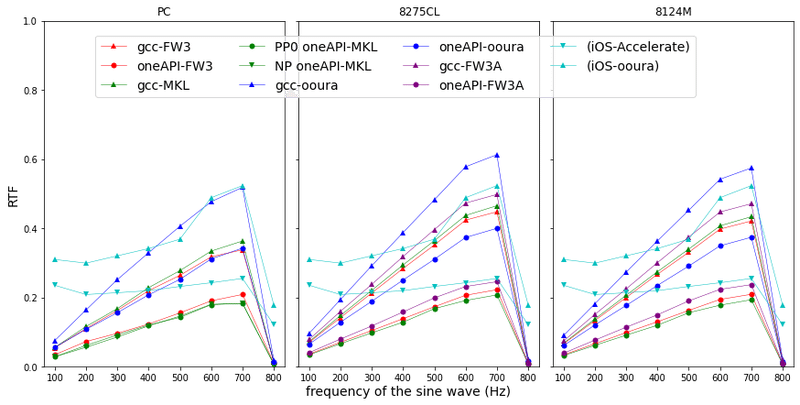
結論から表現すると「Core i7環境下でoneAPI-MKLでビルドすると最速」。
一言でいえば「自分たちが頑張って作ったiOS版がある条件では負けてしまった!」ということなのでややショックですが、よく見ると周波数によって依存がありますし、高価な数理解析用サーバとiPhoneXS Maxが互角の戦いをしているという意味でも興味深いデータになっています。
というか冷静に考えて、その後のApple Siliconの進化などを考えると、AVX-512 にこだわる必要なんてあるんか?と思うかたもいらっしゃるとおもいますが、実はその後AVX2に逆戻りしたり、Linusに嫌われたりして512bit使われていないって問題があったりして256bitになったりとかここ数年、迷走しまくりなんですよね。両方経験しておいてよかった…。
さてRTF。

標本化周波数 48kHzのとき、大浦FFTのRTFが1.0を超え、RTF が Accelerate < 大浦FFT であることから,Accelerate を使用することで 48 kHz においても iOSデバイス上でリアルタイム処理が可能であることがわかりました。さきほどのRTF水色折れ線グラフでもいえることですが、Accelerate は、音源が持つ周波数の変化に応じたRTF の変化が小さいことから、安定な声質変換処理が期待できるといえます。
そう。RTF<1.0超えを音声アプリで作りたければ、Accelerateを使え…!
そしてこのアプローチは「Androidでは動きませんねぇ・・・」と言われて爆死するので、けっこう限られた市場の使い道しか無いかも知れないからよくよく認識しておいてほしい!
「Android端末におけるGPUを利用した 複数音源分離の比較検討」
電通大 CS 鳴海研究室 杉田さんの修士論文 研究(2019)
https://narumi.cs.uec.ac.jp/research/images/2019/sugita_2019_resume.pdf
PyTorch LiteでU-Netか、熱いな!
以下ヒントをいくつか…

AndroidのローレベルライブラリだとVisualizer。
https://developer.android.com/reference/android/media/audiofx/Visualizer
…なんだが、互換性を考えるとUnity の IL2CPPで実装したほうがいいかもだお…
というのもこの研究は、明治大学 森勢研究室の堀部さんの後輩・中野さんのリップシンクの研究に繋がっています。
▶AITuberでも使える!リップシンクから学ぶ音声信号処理とアバター研究
まずはデモからどうぞ。
▶声にならない声で自然にエモートを起動する研究
https://www.youtube.com/watch?v=pSyb-JeqBR4
長編もおもしろいよ
Unityの株価がどんなに下がってもいいけど、MonoやBurstの成果は守り続けてほしいよ…(自分はU.のホルダーです。最近C#案件ないけど!)
https://blog.unity.com/ja/engine-platform/unity-and-net-whats-next
uLipSync v.3.0.0からそろそろ1年…最近はWebGLがサポートされました
凹みさん、素晴らしいですね!!
謝辞と論文リスト
懐かしい方々、お元気でしょうか。ありがとうございました。
Takuma Kato, Tomosuke Nakano, Takanori Horibe, Miku Takemasa, Yusuke Yamazaki, Akihiko Shirai, “Cross-platforming “School life metaverse” user experience”, SIGGRAPH Asia 2022 Posters.
Yusuke Yamazaki, Takanori Horibe, Akihiko Shirai, “Evaluation of Time-Shifted Emotion Through Shared Emoji Reactions in a Video Watching Experience”, 2022 International Conference on Cyberworlds. Best Short Paper Award
堀部貴紀, 橋本順之, 白井暁彦, 森勢将雅,「FFTライブラリを対象とした実時間Vocoderの速度比較」, 日本音響学会2021年秋季研究発表会
堀部貴紀, 白井暁彦, 森勢将雅,「『転声こえうらない』を通したボイスチェンジャー品質改善のための定性分析と考察」, 日本音響学会2021年春季研究発表会
堀部貴紀, 石原達馬, 白井暁彦, 森勢将雅,「『転声こえうらない』利用者の基本周波数分析」, 情報処理学会音楽情報科学研究会. 音学シンポジウム学生優秀発表賞
堀部さん、ご卒業おめでとうございます!!
(森勢先生、熱心なご指導ありがとうございます!)
で、最近もAICU AIDX Labでは、プロい学生を育てています。
弊社はこういう協働研究開発案件のご相談も歓迎です!
いいなと思ったら応援しよう!
