
人工知能とともに絵を描くという行為が人類にどんな影響を与えているか(1)

[2022/8/31追記] note運営よりご指摘があり非公開設定になっていましたが問題個所を修正し再公開しました。技術的続編はこちら、パート(2)はこちら。全編は技術書典13にて9/10公開予定です。
#技術書典 技術書典13ひとまず脱稿しました!
— Dr.(Shirai)Hakase/Metaverse UX Dev/R&D (@o_ob) August 30, 2022
グリー技術書典部誌 2022秋号
「AIとコラボして人気絵師になる」
30ページぐらいあります#技術書典13 #stablediffusion https://t.co/vNFB7YUAAO pic.twitter.com/MfSQn0Laqq
AIで描いた絵が観たい
みなさん「有名AIが描いたクオリティの高い絵を見たい」のではないでしょうか?少なくとも私はこんな未来を感じました。
人間の絵師が「私は有名AIです」といってPixivやBoothで有名になるという未来です。もう来月ぐらいには一般的になるんじゃないかなと。
「例のAIが描いた絵です、プロンプトは秘密です!」
— Dr.(Shirai)Hakase/Metaverse UX Dev/R&D (@o_ob) August 24, 2022
っていって人間の絵師が自分で描いた絵をBoothで売り始める未来までは見えた…
「例のAIが描いた絵です、プロンプトは秘密です!」
っていって人間の絵師が自分で描いた絵をBoothで売り始める未来までは見えた…って、いうつぶやきのその後の話になります。
前提として、私自身、人間が描く行為は大好きです。
人間の手で描くイラストレーションを愛しています。
「AIで描けるなら人間は絵を描かなくていい」みたいな話ではありません。
自身もマンガを描いてました。
過去形でなく、作品を作るうえではスケッチやキャラクターデザイン、指示書など、公開しないけどマンガは描きます。
ドラムを叩いているDamivoちゃんは、設定では「小学校時代に鼓笛隊をやっていたのでドラムロールは叩けるが、ドラムセットは初めてでバスドラやハイハットの踏み方を知らない(裏設定)」という細かい設定が…https://t.co/4Bc5myNNEA #GREEVRStudio pic.twitter.com/vTClP4pDfA
— Dr.(Shirai)Hakase/Metaverse UX Dev/R&D (@o_ob) April 26, 2022
(ダミボちゃんの活躍についてはまたの機会に)
とおりすがりのメタバース研究者です AIを使って絵を描いていますhttps://t.co/mVjmkCWnQz
— Dr.(Shirai)Hakase/Metaverse UX Dev/R&D (@o_ob) August 24, 2022
問題は「上手い」とか「下手」とか、人間は美醜に対して真剣になればなるほど「美しさに対して不寛容である」という点です。ソロで描いているだけであれば、描いている本人がよければそれでいいのですが、SNS時代においては、
(1) 本人が好きで描いているのであればそれでいい
↓
(2)上手い人が視界に入る
↓
(3) 自分の絵が恥ずかしくなる
といったサイクルに常に晒されます。
これは実はSNS時代に限ったことではなく、同人誌時代も同じことですし、昭和の時代の漫画家であれば、雑誌や投稿の上で戦っていました。
このステップには続きがあります。
(1) 本人が好きで描いているのであればそれでいい
(2)上手い人が視界に入る
(3) 自分の絵が恥ずかしくなる
↓ (ここで折れてしまう人もいるのですが)
(4) うまい人の絵をみて学ぶ
というスイッチが重要かもしれません。
この人うまい!と思うだけならいくらでもいるのですが、ああ!こういう表現があったか、こういう構図、こういうシチュエーション、こういう描線…この瞳はどうやって描いているのだろう…?といった探求心と向上心がジェラシーよりも上回ることが大切だと思います。
単に上手な絵を蒐集している人と、手を動かして描いている人の違いはそこにあるかもしれませんし、その2者の違いはとても大きいです。
人工知能で絵を描くための前提知識と用語
さて本題に入ります。
「最近は人工知能で絵を描くことができます」というこの1行のために、何本かの論文を読む必要があります。このnoteでは最終的に、Stable Diffusionを使っていい感じの萌え絵を描かせるためのプロンプト(呪文)に至るまでのテクニックを紹介していきたいと思います。その過程でDALL-EやmidJourney、Stable Diffusionの背景に使われている技術の面白さを誰でもわかるような日本語でわかりやすく解説しつつ、「人類にとってどういう意味があるか?」を空想してみたいと思います。
まあ鉛筆を削ってデッサンを学ぶのに比べれば、大したことはないです。
「人工知能で絵を描く」と一言で表現しても、いろいろな要素が出てきました。例えばPhotoshopなどを長年開発しているAdobe社にはAdobe Researchという研究グループがあります。彼らは画像を直感的な作業で改善するというシンプルな出発点から、写真のフィルタリング技術、背景の除去などを長年開発してきました。最近では、動画の音声を文字起こししてくれたり、簡単なレイアウトを描くだけで神々しい背景画像を作り出してくれたり…となかなか便利そうな技術が学会やデモとして発表されています。
さらに2015年にテスラ社のイーロン・マスクを始めとする実業家・投資家によって設立された人工知能 研究機関”OpenAI”が、DALL-Eという「文字列から(意味を解釈して)画像を生成する」人工知能とそのデモとなるインターフェースを公開しました。文字列から画像を生成するだけであれば、その他にもいくつかの人工知能や類似のシステムは存在しましたが、その改善版「DALL·E 2」においては、自然言語による記述からリアルな画像やアートを作成できる新しいAIシステムとなりました。
2022年4月に書かれた論文「Hierarchical Text-Conditional Image Generation with CLIP Latents」を平易な日本語で概要解説すると、以下のようになります。
(CLIPのような既存手法では)セマンティクス(≒意味、この場合は画像の領域に描かれた意味)とスタイルの両方を捉えた頑健な画像表現を学習します。これらの表現を画像生成に活用することを考えて、2段階のモデルとして、キャプション(注釈として与える文字列)を指定してCLIP画像への埋め込みを生成する事前のモデルと、画像埋め込みを条件として画像を生成するデコーダーの2段階を提案しています。つまり画像の表現スタイルを明示的に指定すれば、フォトリアリズムな表現とキャプションで指定された意味の類似性における差を最小限に抑えて、画像の多様性を向上させられるということです。さらに、CLIPに結合された埋め込みされた意味空間は、ゼロショットで(つまり事前の知識やゴールの設定なく)言語誘導的な画像操作を可能にします。デコーダには拡散モデル(Diffusion Model)を用い、事前分布には自己回帰モデルと拡散モデルの両方を用いて実験し、後者の方が計算効率が良く、より高品質なサンプルを生成できることを見出しました。
Diffusionとは何なのか
専門用語がいくつか出てきましたが、このあとの急速な進化が予感される「AIで絵を描く技術」で覚えておきたい用語は「CLIP」と「Diffusionモデル」でしょうか。
CLIPは4億のテキストと画像のペアを対象学習(Contrastive Learning/コントラスト学習)で学習させたモデルで、「画像とテキストの関係、類似度を測ることができる」と覚えておけばいいでしょう(CLIPもunCLIPなど複数の改善バージョンが存在しています)。
「Diffusionモデル」は生成手法の一種で、DALL-E2ではGLIDEというDiffusionモデルによるText-to-Image生成モデルが使われています。ノイズ除去拡散確率モデル(DDPM: denoising diffusion probabilistic models)というモデルです。マルコフ過程(=未来の挙動が現在の値だけで決定され、過去の挙動と無関係であるという性質を持つ確率過程)により各ステップごとに画像データにノイズを加えていき、ノイズから実データを復元するようにモデルを学習させます。2015年ぐらいから研究されている超解像の技術です。画像に微小なノイズを足していく過程はマルコフ過程として表現できます。ノイズはガウス分布という一般的な発生の確率に沿わせます。そして、その逆工程もマルコフ過程として表現できる、これを学習させることで、ガウス分布ノイズの塊から画像を復元できる学習を獲得させようという手法です。
動画やブログでの解説があるので興味がある人はどうぞ。
35億パラメータの拡散モデルを学習し、もともとの画像は64x64ピクセルのジグソーパズルのようなピースでのセマンティック(この場合は、デコードするといい感じの画像を生成する潜在変数)でも、超解像と組み合わせることで最終的にフォトリアルな画像256x256ピクセルで画像が生成できる。複雑になるとうまく生成できない問題は領域を指定することで人間がさらに補っていくことで完成させる、という手法です。GLIDEでは画像の一部を塗りつぶしてテキスト入力すると、その箇所だけテキスト通りに描き加えることができます。しかも、描き加えたその箇所は、周囲の文脈のスタイルや照明に応じた影や反射を含み、周囲と調和した画像が合成されて生成されます。
Stable Diffusionは64x64のガウスノイズのシード(Latent Seed)を与えてノイズ除去超解像化を行う過程に、ユーザの与えたプロンプトをCLIPを通して生成したテキスト埋め込み(77x768)潜在変数に沿うように誘導するという手法を使っています。簡単に表現すると、人間が言語で与えた意味(セマンティック)を77x768の次元の単語→ベクトルに変換する辞書に渡して、その辞書に近いベクトルに沿わせながらノイズ→512x512画像にノイズ除去しながら超解像化しているとあのような画像が生成される…という魔法になります。
日本語でわかりやすい解説動画があったので、システム構築についても興味がある人はどうぞ。
midJourneyを使ってみる
さて技術は使ってみなければその本質はわかりません。
まずは midJouneryを使って試してみました。
ちょうど仕事でコンセプト画を描かなくてはならないので、
"high school girl in metaverse"
などをプロンプトにしています。


細かい造作を入れていきたいので、「REALITY manga style smiling avatar female with wings and cat ears」など探索してみます。

そもそもREALITYが何のことなのか、知っているのかどうか、これは難しいワードだと思います。結果としては雰囲気はないこともない(実験したのは2022/8/4ごろです、今後変わる可能性もあります)。

いろいろ試してみるとVTuberについての知識はありそうなので、今度はスタイルの指定に使ってみます
「vtuber style female avatar singing」


でき上った画像から良さそうなものを選んで、それをシードにしてさらに画像を探求していく…という工程をDiscordのチャットを使って超高速に進めていきます。

他の人が打ち込んでいるプロンプトが見えている中で、エッチな画像をひたすら作り出そうと頑張っている人もいて、それが参考になったりもして、何というか「何でも描いてくれる絵師さんにひたすら性癖をこすりつけているキモい空間」でもありますが、一方では、目的の絵を生成させるプロンプトを見つけ出すプロンプトエンジニアリングも視界に入ってきます。そもそも英語の prompt はラテン語の promptus(前へ取り出した)という語で、語源としてはラテン語 promo(前へ取り出す)⇒ ラテン語 pro-(~の前へ)+emo(取る)が語源。つまり即座に emptus(手に入れる)という意味で、人類が神様にこの神絵師にうまく絵を描いてもらえる詔(ミコトノリ)ではあるけれど、その神主になって即座に入手する技術も「誰にでもできる技術」ではなくなっていくことが何となく感じられます。
MidJourney創設者のインタビューもありますので紹介しておきます。
David Holz は Leap Motionの創設者でもあるし、AI生成画像の権利関係、日本と米国の考え方の違いも気になります。
いずれにせよ、MidJourneyはエンタメ体験として成立します。GPUやdiscordを使った処理の速さも重要で、お金払う価値はあるかも、という体感があります。
攻略したいゲーマーにとってお絵描きAIは何者なのか
攻略したいゲーマー(人類)にとってお絵描きAIは何者なのでしょうか。
少なくとも、デジタルイラストレーションの世界で勝ち負けで勝負をする相手としてみると、「勝敗をつけるよう場所で戦ってはいけない相手」ではないでしょうか。
「そもそもアートに勝敗はありませんよね」という立場を守るのが人類にとって幸せな選択になるでしょう。
さてDALL-2Eでは修正して「一緒に絵を描く」という貢献が求められましたが、midJourneyではAI神絵師に呪文を唱えるゲーム的な体感があります。これは反応速度が高いGPUが搭載された演算が必要そうですし、コストを払ってゲーム的に楽しみたい人もいそうです。
また攻略性だけでなく、癒しにもなります。例えば「今まで見たことがない癒し猫画像で癒されたい…」といった需要があると思いますが、現実空間で撮影された画像には限界があります。「どこか遠い宇宙を背景にしたファンタジーイラストで、癒される猫の画像を見たい…」という要求に対して、midJourneyが生成する画風やモチーフはフォトリアルやスーパーレアリズムとしては印象的ですが、多様性には限界がある感じがします。
Stable Diffusionで絵を描くテクニック
さて次は、Stable Diffusionを使って絵を描いてみます。
スマホを見て笑う少女シリーズ他https://t.co/mVjmkDdqSz pic.twitter.com/g1a6i9RJVF
— Dr.(Shirai)Hakase/Metaverse UX Dev/R&D (@o_ob) August 24, 2022
ここから先はちょっと真面目に「良い生成結果」を残していく意味もあって、pixivのほうに画像を置いてあります。
使い手の進化の過程がわかるのですが、単純に「美しい絵だけ見たい」という人にはこちらをフォローしていただくのが良いかなと思います。

プロンプトについてはnoteの上でも有料設定とさせていただきます。
特に商品性が高い「萌え絵」になると、「誰でも描ける」ということを売りにすることが自分の技術や時間投資に対する冒涜になる感じがしてきます。
AI萌え絵の詠唱法をマスターしました
— Dr.(Shirai)Hakase/Metaverse UX Dev/R&D (@o_ob) August 26, 2022
フォローお願いしますhttps://t.co/KScAtC9NsH #pixiv #StableDiffusion pic.twitter.com/xAdkF5I6VO
また「思い通りの絵を一通り描けるようになる」をマスターすると、 次は「Pixivが #StableDiffusion を禁止タグに設定する未来」が見えてきました。

えっちな画像を安易に大量生成して、性癖丸出しのタイトルとともに、比較的クオリティの高い絵をpixivのタイムラインに乗せる人が大量に出てくる未来がみえてきます。
そもそもpixivでは「オリジナル画像」というチェックボックスがあるのですが、Stable Diffusionを使って書いた絵が「オリジナルではない」という主張をするのは難しいと思います。そもそも「二次創作である」とすると、「○○の二次創作です」という主張をすることで「○○が好きな人」に刺さるという構造がありますが、「二次創作ではない、これは(○○がいいな!と思って)インスピレーションを受けたが、オリジナルを目指している」という「オリジナル」はいくらでもあるし、Stable Diffusionにおいては潜在変数の組み合わせでしかないでしょう。簡単に表現すれば「人類の美学とモラルが問われているよ?」という1行でしかないのですが。
その潜在変数の組み合わせをどのように詠唱させたか?という点では、実際の絵のデッサンでいえば、エンピツの削り方、その鉛筆を制御する筋肉の鍛え方、光の捉え方、面や空間の捉え方…そしてデジタルイラストレーションでいえば、構図、彩色、表情などに現れてきます。
どれだけ多くのスタイルを知っているか?これは美術史なり、美術書なりを読んでいる人のほうが有利です。日本語ではなく英語で指定したほうが良いですし、ベクトル空間として表現可能な画風を英語で指定できさえすればよいので(具体的なキーワード例は後に紹介します)、有効なキーワードを知っていることが大事です。むしろここを人間と対話的に学習させるインタフェースなども需要が出てきそうです。
つまり「AIが美しい絵を描くなら人類は絵を学ばなくていいか」という命題は、「学ぶ必要がある」ということであり、「描かなくていいか」は実際の絵の具やデジタルイラストレーションの過程と同じように「必要があれば道具として使ったり学んだりすればいい」という事になるかと思います。
またメディア芸術史的な視点でStableDiffusionを観察すると、日本のマンガ、アニメーションやゲームイラストに出てくるようなモチーフは、比較的記号化が進んでしまう要素であるという危惧もあります。
具体的には表情演技です。でもこれは解決する気もします。
Stable Diffusionによる作例
皆さんお待ちかね、Stable Diffusionによる作例です。
自分は Dream StudioというUIを使っています。




ちょっとこわいけど怖くない妙な表情が出せたのでうれしい。
一方では腕がとんでもないことになっているので怖い。







「萌え絵を書いてください」というお願いの今後
「萌え絵を書いてください」というお願いは比較的短期間に獲得可能であり、猥褻図画もしくはそれに準じる画像をひたすら蒐集・消費したいという目的のサイクルは確実な需要がある一方で、ある程度分離、カテゴライズ、カーテンなりR-18なりで別けることで双方に健全な進化成長を促すことができるようにも思います。
レタッチはしたほうが良いと思います
いくつかの作例とともにレタッチの重要性を語っておきます。

ぼかしていますが、そこにはヤバい指がいます

ガンダムfeat.初音ミクというポップアートの権化みたいなプラモを作ってみました。
自分がそのプラモを撮影するならこういう効果を入れるだろうなあと

意外と西洋美術が好きそうな宗教画とかのスタイルはたくさんあるので、和洋折衷で新しい表現演出を開拓するにはいいかもしれないですね。
レタッチしないけど味わいある作品・使い方

指が微妙ですが雰囲気はいい

スタイルだけが作品になる

花を描くのが大変なのですが、AI画像生成は得意ですよね。

こちらも 金曜ロードショー「耳をすませば」放映記念。
赤いドットと背景のライティングはPhotoShopでのレタッチです。

マンガ描線についてはこれだけで語りたい要素がありますが比較的うまくいった事例
筆をおく前に
描き手、クリエイターとしての感覚として、自分の画力や筋力(気合の入った絵を何時間も高速に描き続けるには筋力が必要です)に関係なく、上手な出力ができるようになると脳が発火していくことを感じます。つまり人間の脳は絵を描きたい。表現したい、表現を探求したい。これは単体の脳でも感じます。それを脳の外に画像として放出することで、他者の評価や需要を満たす、そしてもっと上手にAIを使いこなす人々にジェラシーを描いたり、その技術を獲得するためにお金を払ったりする人も出てくると思います。つまり冒頭に書いた
(1) 本人が好きで描いているのであればそれでいい
(2)上手い人が視界に入る
(3) 自分の絵が恥ずかしくなる
↓ (ここで折れてしまう人もいるのですが)
(4) うまい人の絵をみて学ぶ
このサイクルであることは全く否定できません。
もちろんこのサイクルにStableDiffusionというアルゴリズムや関連のサービスが入ってきました。技術の思想はDALL-Eを産んだOpenAIが「企業の独占ではなく」という立ち位置で生まれていることからも、単一企業の独占ではありませんが、賢い投資家たちは「人類が脳汁を発したり、お金を出してでも手に入れたいと思うもの」に対して投資行動をしていくと思います。
規模の大小はわかりませんが、これからもAI画像生成技術には一定の注目があると思います。
一方で、このSF小説(としておきます)をここまで読んだ人はお気づきだと思いますが、StableDiffusionにはDALL-E2にあったような「任意の場所を描きなおす」というプロセスはないようです。実際に、これらの絵作り工程では、ポージングやレイアウトを直接指定したいことはたくさんありますし、いちばん難しいところは「指と顔の表情」の指定です。顔は記号的な表現でよければワードで指定できるとは思います。でも絵画で表現したいような複雑な表情は難しいですし、これを言語で表せるならそれこそ絵画の終わりを感じる気もします。またアニメーションで表現したい動的な表情変化、表演技に特化した対話的なUIなどもあるかなと思います。この辺はCGxAI分野の研究者のネタでしかないので、学会などでお話しできればなと思います。
人工知能とともに絵を描くという行為が人類にどんな影響を与えているか
ここまで、人工知能とともに絵を描くという行為が人類にどんな影響を与えているか?という視点で技術解説スタイルで作文をしてきました。
絵を描く必要があるかどうか?学ぶ必要があるかどうか?については実際に体験して本気で画像を作ってみるとわかることがあると思います。そこには明確な技量が必要であり、若い人や経験がある人にとっても、一度は体験しておくべき衝撃があると思います。そしてそれは、「エンピツをもって絵を描くことの意味」とほぼ同意ではないでしょうか。つまり「その技法で頑張ること」の意味を自分が理解すれば、それにこだわる必要はないが、やったことがない状態で良し悪しを判断するのは野蛮なことである、というぐらいの話でしょうか。もちろん「苦労したほうが良いものが描ける」という視点もあると思いますが、技法としての苦労と、表現としての苦労、表現者の表現したい画風とはそれぞれ異なってよいという見方ができるかどうかです。
単体の脳にとって、美的な何かを探求する、自らのモチベーションと向き合う、という行為は大変刺激のある行為であり、数億~数十億といった、現在の地球人類の個体数の総和に匹敵する数のスタイルを学習したAIと対話することの意味は、まさに人類がいままで描き残してきた画像メディアの歴史的集約との対話を行っていることに他ありません。
神絵師との対話は「こういう画像を得たい」という人間のモチベーションと向き合うことに他ありません。むしろ人類が「画像などいらぬ」という存在であれば、AIアルゴリズムやそれを開発する企業、新しいスタイルを収集して学習させるオペレーターは不要です。人間の欲望、無垢な想像力と向き合っていく必要があります。
例えば日本語入力IMEのような、予測変換やUI技術を駆使した日本語文字入力技術がなければ、我々日本人はまともに文章を書くことすら難しいでしょう。そのような技術をなくして、小中高校のような鉛筆がなければ書けない日本語のみを「日本語」とすることはとても乱暴で、それすらも「鉛筆やノートという工業製品がなければ成立していません。
そして人工知能で絵を描く以外にも、作文を書くツールなども生まれています。この原稿も、ツールで書いているかもしれません。

初音ミクが鹿や牛と一緒に銀河系で踊っているイラストの茶色と黒、「ラスコー洞窟」による先史時代の壁画で、黄色、茶色、黒の強い絵筆を使用。
さいごに。人類最初期の壁画であるラスコー洞窟に初音ミクを描いてみる挑戦をしました。







どんなプロンプトを与えられるかについては、考古学的知識が必要ですし、やはり生み出されたノイズ画像から、目的の画像をゴールとして取り出すのは、我々人類なのです。そしてそれが本当なのかどうか、真偽性はともかく、人々にとってどんな魅力や意味を持つのか…我々人類は、メディアと芸術に対して、より真剣に考えていく機会を得たことになります。
おまけ:法的な視点で解説してくれる人がいた(8/31追記)
(ちょうどMIMICというサービスがこのブログを書いているところで人気になって炎上したのですが)
Midjourney、Stable Diffusion、mimicなどの画像自動生成AIと著作権
柿沼太一弁護士(2022/8/31)
https://storialaw.jp/blog/8820
すごいいい記事だった。まとめると
前提:まずは日本リージョンでサービス展開する場合は収集側が例外的に有利(著作権法30条4)
(1)「AI利用禁止」表明は意味なし(契約相手不在)
(2)呪文は営業秘密で守るのが正当
生成・提供行為が著作権侵害につながる危険性は相当に低いが「ほぼ複製」なら危険…ということになりますね。
おまけ:StableDiffusionでのプロンプトキーワード例と便利なツール解説・資料
SF小説としてはここで終わりです。
以下は有料とします。たいした情報はないと思いますが、今まで出てきた画像を「私も作りたい」と思う人には有益な情報を載せておきます。
ツール紹介
今回生成した画像の多くはDream Studioで生成しています。
Stable Diffusionを使ったUIを提供しており有料サービスです。
生成された画像は CC0 1.0 Universal Public Domain Dedication です。
また今後、動画版なども登場することが記されています。
Promptジェネレータ
だいぶ経ってからこのツールを発見したのですが、自分が知らないスタイルをいくつか発見してくれています。
サルバドール・ダリのように(in Salvador Dali style) パブロ・ピカソのように(in Pablo Picasso style) ルネ・マグリットのように(in Rene Magritte style) スタジオ・ジブリのように(in Studio Ghibli style) 京都アニメーションのように(in Kyoto Animation style) A-1 Picturesのように(in A-1 Pictures style) 東洲斎写楽のように(in Toshusai Sharaku style) 葛飾北斎のように(in Katsushika Hokusai style) 岡本太郎のように(in Okamoto Taro style) 村田蓮爾のように(in Murata Renzi style)
こういったスタイル指定をできるワードがとても重要なので、今後の成長を期待して紹介しておきます。実際には村田蓮爾やA-1 Picturesのようなスタイルはまだないように思います(意味空間的に近いものはあるかもしれない)。「Studio Ghibli」は自分でも使っていますが、そこそこに獲得されているようです。
実用プロンプト例
先述の通り、乱数のシード値によるところがありますので気長にガチャを回してみてください。生成画像の数を増やすことで時短できます。
いくつか見ると、コツがつかめると思います。人間ってすごい。
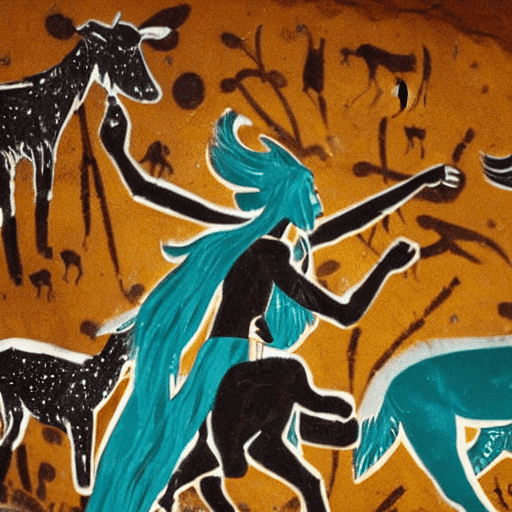
Illustrated brown black Hatsune Miku is dancing with deer and ox in galaxy by Grotte de Lascaux, aged prehistoric wall painting strong paint brush yellow brown black trending on national geo graphics
練習:ウマ娘を描かせる
なかなかいい練習になります
「アイドル風_馬の耳と尻尾の女子高生_馬のレース場で走っている」




画風を指定するテクニック
いきなり上級者向けテクニックを紹介します。その後、基本テクニックを紹介します。
ここから先は
¥ 1,000
Amazonギフトカード5,000円分が当たる
チップとデール!チップがデール!ありがとうございましたー!!