
Real-Time Latent Consistency Model (LCM)から掘り下げる最近の画像生成AIの高速化研究

今週世間を賑わせている画像生成AIの話題で一番インパクトのある話題が
「Real-Time Latent Consistency Model」、通称「RT-LCM」だと思います。
"RT-LCM"
— AICU Inc. (@AICUai) November 1, 2023
Real-Time-Latent-Consistency-Model
リアルタイムで潜在空間が一貫して動きます
CUDAとPython、またはM1/M2/M3チップを搭載したMacでも動くようです
HuggingFaceSpacesでのデモもありますhttps://t.co/T7AmuKNzTC pic.twitter.com/U0l2WX7u6p
このLCM関係の論文を調査していたらけっこう勉強になったので簡単に紹介しておきたいとおもいます。
この数日で、既にいろんなデモが出ているのですが、いちばん有名と思われるのがRadames@HugginFaceのデモで、SpacesでWebカメラを使って遊べたりします(混んでます)。
https://huggingface.co/spaces/radames/Real-Time-Latent-Consistency-Model
リアルタイムでStable Diffusionのimg2imgが動いているように見えます。
このソースはこちらで、ローカルでも動くようです。CUDA とPythonかM1/M2/M3 chip 搭載Macがあれば動くそうです。TinyVAEを使っているようです。
混んでいて見れない場合はHugginFaceの@radamarさんのツイートから
Thanks to the Latent Consistency Model (LCM), we're nearing real-time image diffusion. I've made a simple MJPEG server for generation stream using diffusers img2img pipeline. It's really fun to play with it. Can't wait for the ControlNet version.
— Radamés Ajna (@radamar) October 30, 2023
try it: https://t.co/Hf47hV4fl4 pic.twitter.com/0RGhaSA2g1
後で解説しますがこの技術は Stable Diffusion(安定拡散)ではありません、Latent Consistency Model(潜在的一貫性モデル)「LCM」もしくは、総称して 「Consistency Models」(一貫性モデル)CMと呼ぶべきかな。
後に紹介するSimian Luoさんによると
LCMs: The next generation of generative models after Latent Diffusion Models (LDMs).
LCM: 潜在拡散モデル(LDM)に続く次世代の生成モデル
teftefさんの解説が論文もあって一番短い時間で理解できます
そこで引用されている なんか さんの解説(2023年4月)がとても良い。
あらゆる時刻からの原点へのマッピングを学習することによって、スコアベース生成モデルで1stepもしくは数stepでの画像生成が可能になった。性能は当然既存の重い拡散モデルに劣るが、高速化は著しい
・Consistency Modelの学習手法には既存の拡散モデルからの蒸留(Consistency Distillation)とゼロからの学習(Consistency Training)の2つがある
・推論ステップ数と品質はトレードオフの関係にあり、推論時にどちらを優先するか選択することができる
・L2距離以外にも、L1距離やLPIPSのような様々な差異の評価関数を使用して学習を試みている
時間方向の学習をしていることもあり、動画フレーム間の安定が期待できそう。
"一貫性モデル" (Consistency Models)の歴史
"一貫性モデル" (Consistency Models)
[投稿日: 2023年3月2日 (v1)、最終改訂日: 2023年5月31日 (本バージョン、v2)].
ヤン・ソン, プラフルラ・ダリワル, マーク・チェン, イリヤ・スーツキーヴァー
拡散モデルは画像、音声、映像生成の分野を大きく発展させたが、生成に時間がかかる反復サンプリング処理に依存している。この制限を克服するために、我々は、ノイズをデータに直接マッピングすることによって高品質のサンプルを生成する新しいモデル群である一貫性モデルを提案する。
このモデルは、設計上、高速な1ステップ生成をサポートする一方で、多段階サンプリングにより、サンプルの品質と引き換えに計算を行うことができる。また、画像のインペインティング、カラー化、超解像などのゼロショットデータ編集をサポートし、これらのタスクに関する明示的なトレーニングを必要としません。一貫性モデルは、事前に訓練された拡散モデルを蒸留することによって訓練することも、独立した生成モデルとして訓練することもできる。
広範な実験を通して、我々は、1ステップ及び数ステップのサンプリングにおいて、拡散モデルのための既存の蒸留技術を凌駕することを実証し、1ステップの生成において、CIFAR-10で3.55、ImageNet 64x64で6.20という最新のFIDを達成した。単独で訓練した場合、一貫性モデルは、CIFAR-10、ImageNet 64x64、LSUN 256x256などの標準的なベンチマークにおいて、既存のワンステップの非逆説的生成モデルを凌駕することができる新しい生成モデルファミリーとなる。
さらに最近の論文がこれです。
潜在的一貫性モデル.数ステップの推論による高解像度画像の合成
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao
[投稿日: 2023年10月6日]
潜在拡散モデル(LDM)は、高解像度画像の合成において目覚ましい成果を上げている。しかし、反復サンプリングプロセスは計算量が多く、生成に時間がかかる。Consistency Models (song et al.)に触発され、我々はLatent Consistency Models (LCMs)を提案し、Stable Diffusion (rombach et al.)を含む事前に訓練されたLDMsに対して、最小限のステップで迅速な推論を可能にする。LCMは、ガイドされた逆拡散プロセスを拡張確率流ODE(PF-ODE)を解くと見なし、潜在空間におけるそのようなODEの解を直接予測するように設計されており、多数の反復の必要性を軽減し、迅速で忠実度の高いサンプリングを可能にする。事前に訓練された分類器なしのガイド拡散モデルから効率的に抽出された高品質の768 x 768 2~4ステップのLCMは、学習にわずか32 A100 GPU時間しかかかりません。さらに、LCF(Latent Consistency Fine-tuning)を紹介します。LCFは、カスタマイズされた画像データセット上でLCMを微調整するための新しい手法です。LAION-5B-Aestheticsデータセットでの評価により、LCMは少ない推論ステップで最先端のテキストから画像への生成性能を達成することが実証された。
https://doi.org/10.48550/arXiv.2310.04378
Simian Luoさんは清華大学の学生さんで、モデルを遊べる状態で公開してくれています。
https://replicate.com/luosiallen/latent-consistency-model
これGPU料金けっこうかかりそうなんですが、Replicateというサービスで、意外と安いかも…。A100が1時間で5.04USDか… A40もあるぞ。
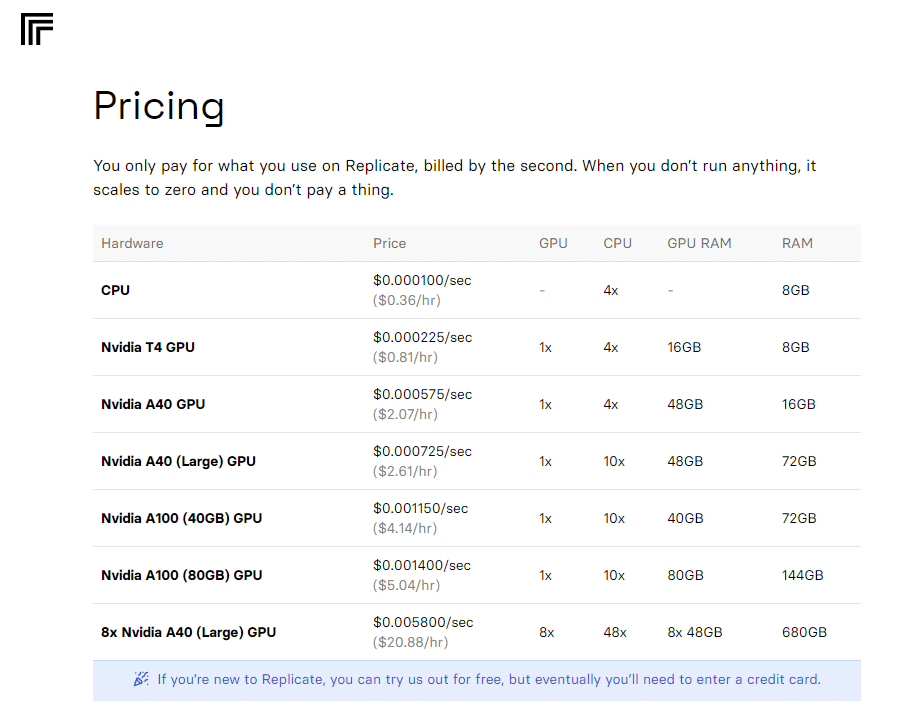
ReplicateだけでなくHugginFaceにもリポジトリがあります
彼はLCMのコミュまで作っていたのでつい参加しちゃいました
https://huggingface.co/latent-consistency-model

ダウンロードしてお手元のStable Diffusion WebUI AUTOMATIC1111で動かしてみました。情報の多くは彼のGitHubにあります。
次にモデルをダウンロードしましょう。
LCM_Dreamshaper_v7_4k.safetensors(3.44GB)
https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7/tree/main
LCM_Dreamshaper_v7_4k.safetensors [84feab3a32]
ダウンロードしたら、WebUIの Models\StableDiffusion ディレクトリに置きます。
Stability Matrixなら
\StabilityMatrix-win-x64\Data\Models\StableDiffusion
といったディレクトリです。
続いて、extentionsディレクトリで
git clone https://github.com/0xbitches/sd-webui-lcmとすればセットアップは終わりです。
初回はローディングに10秒ぐらいかかりましたが、だいたい体感で3-4秒で生成されているようです(RTX4050 Laptop VRAM6GB, CPU i7 12650H, RAM32GB )。
試しにプロンプト「1girl」として100枚生成してみたところ、所要時間はちょうど7分、4.2秒/生成といった能力です。これは素晴らしい。
生成された結果も美しい。さすが Dreamshaper。

速度感がイメージできないかもしれないですが、生成された画像のタイムスタンプが証拠になると思いますので是非見て。
4秒/生成、つまり1分間に15枚ぐらい生成されちゃう速度です!

ちなみに中国にはHugginFaceにかわってOpenX Labというサービスがあるようです、これも勉強になった。
https://openxlab.org.cn/apps/detail/Latent-Consistency-Model/Latent-Consistency-Model
技術の進化はさらに加速する
さらにYang Song先生らの最新の論文を見つけました
一貫性モデルの学習手法の改善
ヤン・ソン、プラフルラ・ダリワル [投稿日:2023年10月22日]
一貫性モデルは、敵対的な学習を必要とせず、高品質なデータをワンステップでサンプリングできる生成モデルの新ファミリーである。現在の一貫性モデルは、事前に訓練された拡散モデルから蒸留し、LPIPSのような学習されたメトリクスを採用することで、最適なサンプル品質を達成している。しかし、蒸留は一貫性モデルの品質を事前に訓練された拡散モデルの品質に制限し、LPIPSは評価に望ましくないバイアスを引き起こす。これらの課題に対処するために、我々は一貫性学習における改良された技術を提示する。一貫性学習の背後にある理論を掘り下げ、教師一貫性モデルから指数移動平均を排除することで、これまで見過ごされていた欠陥を特定する。LPIPSのような学習されたメトリクスを置き換えるために、ロバスト統計からPseudo-Huber損失を採用する。さらに、一貫性訓練目的に対して対数正規雑音スケジュールを導入し、設定された訓練反復回数ごとに、離散化ステップの合計を2倍にすることを提案する。より良いハイパーパラメータのチューニングと組み合わせることで、一貫性モデルはCIFAR-10とImageNet 64×64において、1回のサンプリングステップでそれぞれ2.51と3.25のFIDスコアを達成する。これらのスコアは、以前の一貫性学習アプローチと比較して、3.5倍と4倍の改善となる。2段階のサンプリングにより、これらの2つのデータセットにおけるFIDスコアは2.24と2.77に減少し、1段階と2段階の両方の設定において蒸留により得られたスコアを上回った。
そんなわけでものすごい速さで高速化研究が報告されているし、LCMはDiffusionモデルに対して一貫性に優れたモデルなので動画向き。
おそらく画像生成AIで実時間処理を超えるリアルタイム動画、たとえば1秒間に60フレーム以上の処理ができるテキスト画像生成なんかも出てくる日は近いかなと思いました。
そういう意味で冒頭のデモにあったWebカメラからのImage2Imageは様々な応用がありそうですね。少なくともリアルタイムで美少女になるぐらいのことはできそうだ…。
おまけ資料:YangLing0818さんの論文
https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy
このリポジトリは、ジャーナルACM Computing Surveysに受理された調査論文「Diffusion Models: A Comprehensive Survey of Methods and Applications」に従って、拡散モデルに関する論文を収集および分類するために構築されています。この分野の急速な発展を考慮して、私たちはarxiv 論文とこのリポジトリの両方を更新し続けます。
歴史も更新されていく、Latent Consistencyは現時点ではまだ入っていないが、こういうのを残しておくのとっても大事ですね!