
コスト安で話者分離を実現する

無限もじおこしでは、Geminiを使って文字起こしをしています。
ただ現在は「何を話したか」の文字起こしは精度高く実現ができているのですが、「誰が話したか」を識別可能な形で文字起こしをすることがまだできていません。
話者を識別可能な形で文字起こしをすることを「話者分離」といったりしますが、こちらは技術的難易度が一段上がり、かつコストもかかるので時間がかかっております…!
今回は、コスト制約下の中で行う話者分離方法について、これまで検証してきた内容についてまとめていこうかなと思っています!
この内容は2024年12月19日に開催された「API Night #1 〜AI/LLM × API 生成AIをサービスに組み込む〜」で登壇した内容をもとにした記事となります。
話者分離の課題
話者分離は一般的には「まとまった発言が分割されていて」「話者が紐づいており」「開始時刻と終了時刻」がセットになって文字起こしされたものです。

これを実現するにあたって、一般的な文字起こしには存在しない新しいタスクが出てきます。
発言を良い感じに分割するか
分割された発言部分に対して、正確にタイムスタンプを紐づける
話者を一貫性を持たせた形で紐づける
これらが、まあ難しいんです。。
Gemini プロンプトでゴリ押し作戦
「Geminiでプロンプトを頑張ればいけるでしょ!」と思いきや、そんな甘い話ではありませんでした🥲
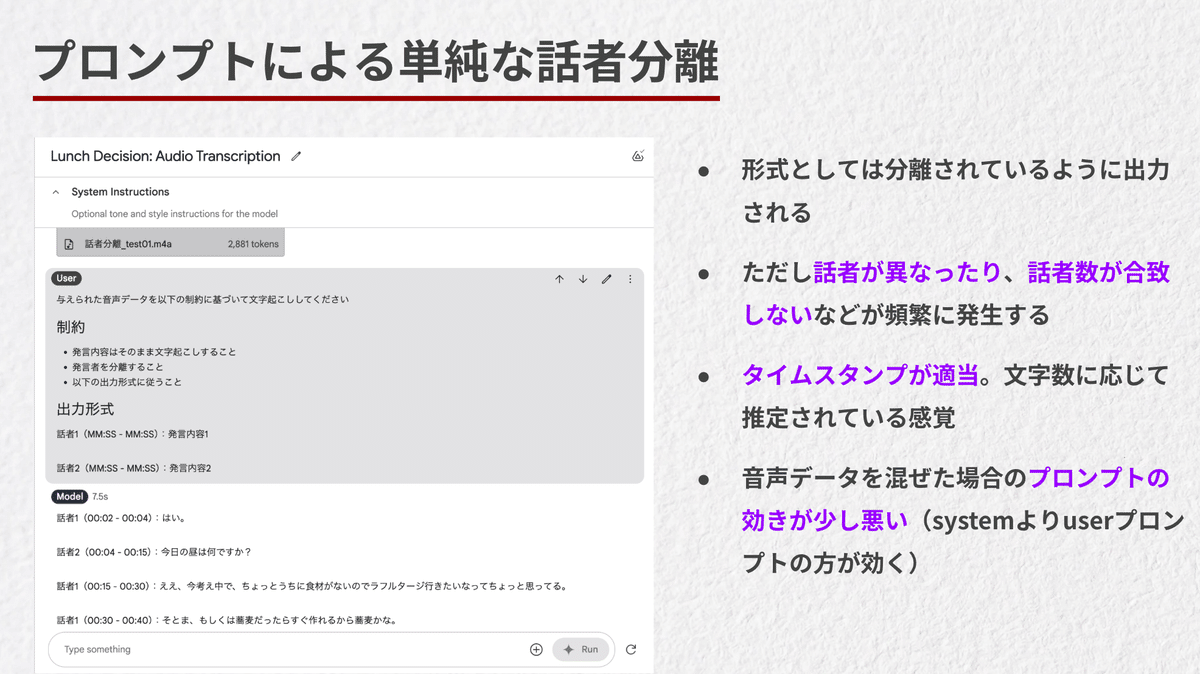
まず話者の紐付けですが、一見出力形式ではできてそうに見えるのですが、話者に一貫性はなく、また入れ替わりも往々にしてあります。
そして音声データを混ぜた場合なのですが、プロンプトの効きが悪くなります。Geminiの場合ですと、音声データがあるときは、system promptに記述するよりも直前のuser promptに記述する方が指示が効く感覚があります。
ただ全体的に安定感が失われている感覚もあり、複雑なタスクを一発で行うのはやや不安だなと感じています。
また、Geminiが書き出すタイムスタンプは適当です(※後述で補足)。発言した文字数に応じて、雰囲気でタイムスタンプが紐づけられます笑

公式ドキュメントによるとGemini 1.5 シリーズでは、音声データのタイムスタンプ生成は正確性に欠けるという記述がありました。どうやら動画データだと正確に生成できるとのことですが、コストが8倍になるため断念してます。。
ただしGemini 2.0シリーズから、タイムスタンプの正確性が上がっていることは確認しており、Geminiでタイムスタンプを考慮したタスクを行いたい場合は2.0シリーズを使いましょう!
(2025/1/25時点では、まだGemini 2.0 Flashは実験版のみなので注意)
Azure Speech と Geminiの併用
そこでGeminiにこだわらず、Azure Speechにある話者分離サービスを使って、うまくできないかなと思いました。

Azure Speechは話者分離の正確性が結構高いなと思っています。つまり話者の一貫性と、タイムスタンプの正確性が良い感じです。
一方で、文字起こしの品質はそこまで高くない感覚があります。そこでGeminiで通常の文字起こしを行い、並行してAzure Speechを用いて話者分離を行う。
最後に2つの文字起こし結果を、Geminiで組み合わせて最終的な「話者分離された高品質な文字起こし」を生成するというアプローチです。
これ結構うまくいって「よし!」となったんですが、冷静にコストを考えると通常の文字起こしの30倍の価格(1時間30円)となり、無限もじおこしの有料プランで利用するには、ちょっときついなーと感じました。
faster-whisper と Gemini の併用
もう少しコスト感が現実的で、かつ精度も担保できる方法を探るべく、検証を重ねました。そこで出てきたのがこちらのアプローチ!

文字起こし業界では「Whisper」という音声認識モデルがよく知られており、こちらの文字起こし精度は結構高いです。タイムスタンプも正確に紐づけてくれます。
一方で話者を紐付ける機能はありません。ただ裏仕様として、話者が変わったタイミングでハイフンを追加してくれる仕様があります。

これをうまく使うと、どこで話者の発言が分割されているかが分かるので、この発言は誰が話したのかをGeminiに推定してもらうというアプローチができます。
このWhisperはOpenAIもAPIとして提供しており、1時間の文字起こしで50円ほどかかります。この金額感では到底サービス提供ができないので、RunPodというサービスを利用して、サーバレスな形でfaster-whisperをデプロイすることで、1時間5円程度にまで抑えられます。
トータル10円くらいにはなりそうですが、先ほどの30円よりもコスト削減ができたので、現時点での有力候補です!
今後の可能性
こんな発言をした手前、そろそろ検討を終えて実装に取り組んでいこうと思っています!
覚悟決めて話者分離の実装進めるか!コストが怖いがなんとかするぞ!
— にょす@無限もじおこし開発者 (@nyosubro0706) January 20, 2025
現在多くの人に精度面とコストの安さで評価をいただいているので、それを裏切ることなく、まずは回数制限のあるベータ版として導入をしていければなと考えています。
また上記の話者分離の方法は、あくまで2024年時点のもの。今年はマルチモーダルがさらに発展していく年だと思っており、話者分離がGeminiで完結する可能性は十分あると思っています。
そうなった時に、迅速に高品質な文字起こしを提供していけるよう引き続きアンテナを張って、キャッチアップもしていこうかなと思ってます💪
おわりに
このマガジンでは、僕が運営している「無限もじおこし」に関する運営の裏側や、個人開発から得られた学びやアイデアなどを、週1回くらいのペースでゆるりと発信していこうと思っています!
マガジン自体は有料に設定していますが、記事はすべて無料で読めるようにしているので、気軽に楽しんでもらえたら嬉しいです。もし記事を読んで「応援したい!」と思っていただけたら、SNSでシェアしてもらったり、マガジンを購読していただけると、めちゃくちゃ励みになります!
それから、もし「無限もじおこし」をインタビューやメディアで取り上げていただける機会がありましたら、ぜひお気軽にお声がけください!いつでもお話お待ちしております!
ここから先は

生成AIアプリ個人開発者の頭の中
「無限もじおこし」「ねらーAI」「シャベマル」など、生成AIを駆使したアプリを作っている個人開発者が日々考えていることを発信していきます。
この記事が気に入ったらチップで応援してみませんか?