
24GB GPU で 20B LLM の RLHF ファインチューニング

以下の記事が面白かったので、軽くまとめました。
1. LLM と RLHF
「RLHF」と組み合わせた「LLM」は、ChatGPTなどの非常に強力なAIシステムを構築するための次のアプローチです。「RLHF」でLLMを学習するには、通常、次の3つのステップが必要です。
(1) 事前学習モデルを教師あり学習でファインチューニング。
(2) 報酬モデルの学習。
(3) 教師あり学習でファインチューニングしたモデルを、強化学習でさらにファインチューニング。

2. TRL
「trl」は、LLMを誰でも簡単に強化学習でファインチューニングできることを目的としたライブラリです。これを使用して、映画の肯定的なレビューを生成するように調整したり、より毒性がないものに調整したりすることができます。
強化学習によるLLMのファインチューニングは、次のような手順で行います。アクティブなモデルが元の挙動や分布から大きく外れるのを避けるため、最適化ステップごとに参照モデルのロジットを計算する必要があります。このため、最適化プロセスには、GPUデバイスごとに少なくとも2つのモデルのコピーが必要であり、厳しい制約が加わります。モデルのサイズが大きくなると、1つのGPUにセットアップするのはますます難しくなります。

3. 大規模なモデルの学習
大規模なモデルの学習は困難です。最初の課題は、モデルとそのオプティマイザの状態を、利用可能なGPUデバイスに適合させることです。1つのパラメータが必要とするGPUメモリの量は、その「精度」(dtype) に依存します。最も一般的な dtype は float32、float16、bfloat16です。最近では、int8のような精度が、学習や推論のためにサポートされています。GPUデバイスにモデルをロードするために、10億パラメータごとに、float32で4GB、float16で2GB、int8で1GBのコストがかかります。
このような課題に大規模に取り組むために、多くの技術が採用されてきました。最も身近なパラダイムは、「Pipeline Parallelism」「Tensor Parallelism」「Data Parallelism」です。

「Data Parallelism」では、同じモデルが複数のマシンで並列にホストされ、各インスタンスに異なるデータバッチが供給されます。これは、シングルGPUのケースを本質的に再現する最も単純な並列化戦略であり、「trl」ですでにサポートされています。「Pipeline Parallelism」「Tensor Parallelism」では、モデル自体がマシン間で分散されます。「Pipeline Parallelism」ではモデルはレイヤーごとに分割され、「Tensor Parallelism」ではテンソル演算がGPU間で分割されます。これらのモデル並列化戦略では、モデルの重みを多くのデバイスに分散させる必要があり、プロセス間でアクティブとグラジエントの通信プロトコルを定義する必要があります。これは実装が容易ではなく、「Megatron-DeepSpeed」「Nemo」のようなフレームワークを採用する必要があるかもしれません。
4. 8-bit matrix multiplication
「8-bit matrix multiplication」は、論文 LLM.int8() で初めて紹介された手法で、大規模モデルの量子化時の性能劣化の問題を解決することを目的としています。提案手法は、Linearレイヤーのアンダーグラウンドで適用される行列乗算を、float16で実行される外れ値の隠れ状態部分とint8で実行される「非外れ値」部分の2段階に分解しています。

8bitの行列乗算を使えば、全精密モデルで4倍 (半精密モデルで2倍) サイズを小さくできるのです。
5. LoRA
2021年、論文「LoRA: Low-Rank Adaption of Large Language Models」が、大規模言語モデルのファインチューニングを、事前学習した重みを凍結し、query層とvalue層のattention行列の低ランクバージョンを作成することで実行できることを示しました。これらの低ランクの行列は、元のモデルよりもはるかに少ないパラメータを持ち、はるかに少ないGPUメモリでファインチューニングを行うことができます。著者らは、LoRAをファインチューニングすることで、事前学習済みのフルモデルをファインチューニングするのと同等の結果が得られることを実証しています。
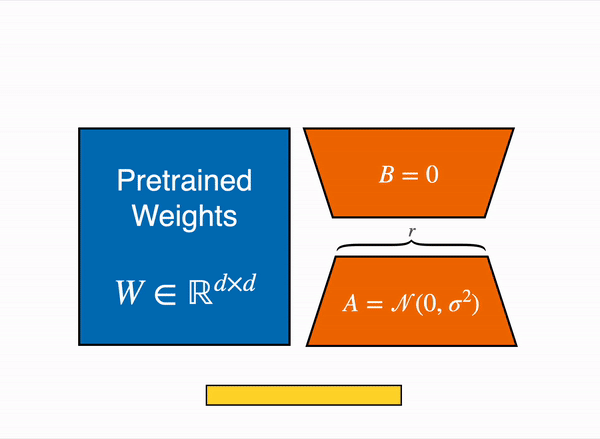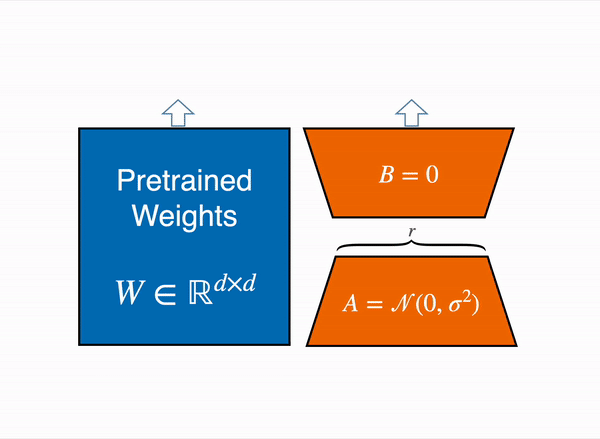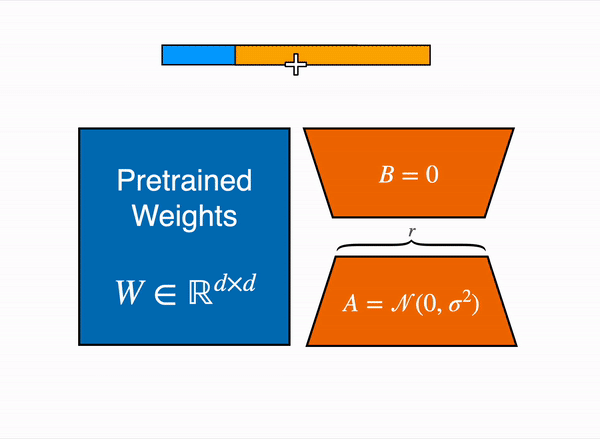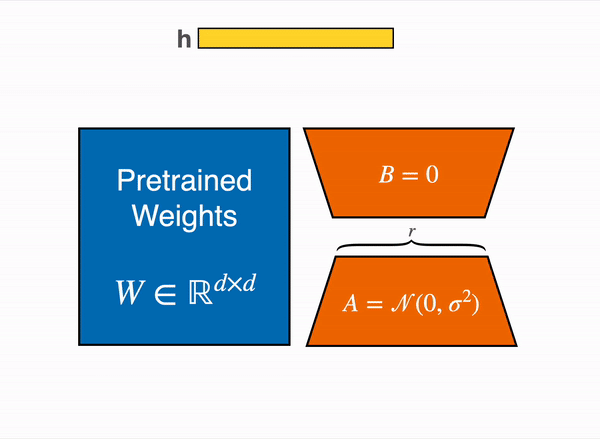
この手法により、必要なメモリの数分の1でLLMをファインチューニングすることができます。しかし、いくつかの欠点もあります。アダプター層で行列の乗算を追加するため、フォワードパスとバックワードパスは約2倍の速度がかかります。
6. PEFT
「PEFT」は、LLM上のアダプターレイヤーの作成とファインチューニングをサポートするために作成されたHuggingFaceライブラリです。「PEFT」は、「DeepSpeed」と「Big Model Inference」を活用した大規模なモデル向けに「Accelerate」とシームレスに統合されています。
・因果関係言語モデリング
・条件付き生成
・画像分類
・8-bit int8学習
・DreamboothモデルのLoRA
・セマンティックセグメンテーション
・シークエンス分類
・トークン分類
7. LoRAによる20Bモデルのファインチューニング
24GBのGPU1台で、上記のツールを使って、強化学習で20BパラメータのLLMをファインチューニングする方法を図で説明します。
7.1 8-bitのアクティブモデルを読み込む

LLM.int8で説明されている方法を使用して、8-bitでモデルをロードすることで、LLMのメモリ削減を行います。これは、from_pretrained()を呼び出す際にload_in_8bit=Trueというフラグを追加するだけで実行できます。
7-2. PEFTを使った学習可能なアダプタの追加

モデル内部にアダプタを搭載し、これらのアダプタを学習可能な状態にします。これにより、アクティブモデルに必要な学習可能な重みの数を劇的に減らすことができます。このステップは「PEFT」を活用し、数行のコードで実行することができます。
7.3 参照ロジットとアクティブロジットを取得するために同じモデルを使用

アダプタは非アクティブ化できるので、同じモデルのコピーを2つ作成しなくても、PPOの参照ロジットとアクティブロジットを取得するために、同じモデルを使用することができます。これは、「PEFT」の機能であるdisable_adaptersコンテキストマネージャを利用したものです。
7.4 学習スクリプトの概要
「Transformer」「PEFT」「trl」を使用して、20B gpt-neoxモデルを学習させた方法を説明します。この例の最終目標は、メモリに制約のある環境で、映画の好意的なレビューを生成するためにLLMをファインチューニングすることです。同様の手順は、対話モデルなど、他のタスクにも適用できます。
3つのステップと学習スクリプトがあります。
(1) clm_finetune_peft_imdb.py : imdbによるLoRAをファインチューニング
(2) merge_peft_adapter.py : アダプタのレイヤーをベースモデルにマージしてHubに保存。
(3) gpt-neo-20b_sentiment_peft.py : imdbの感情分類によるLoRAファインチューニング。
学習の最初のステップは、事前学習モデルのファインチューニングです。通常、この作業には80GBのA100GPUが数台必要になるため、LoRAによる学習を行いました。imdbで1エポックの学習を行いました。

適応したモデルを強化学習でさらにファインチューニングを行うには、まず適応した重みを組み合わせる必要があります。これは16-bit浮動小数点で事前学習したモデルとアダプタを読み込み、重み行列(適切なスケーリングを適用)でサマリーを読み込むことで実現しました。
最後に、凍結したimdb-finetunedモデルの上に、別のLoRAでファインチューニングすることができます。強化学習で報酬を与えるために、imdbの感情分類を使用しました。
