Firestore の ベクトル検索を試す

「Firestore」の「ベクトル検索」を試したので、まとめました。
1. Firestore の ベクトル検索
「Firestore」にプレビュー版ですが、「ベクトル検索」の機能が付きました。
2. ベクトルインデックスの作成と削除
2-1. ベクトルインデックスの作成
(1) ローカルマシンで「gcloud CLU」をセットアップ。
(2) 以下のコマンドを実行。
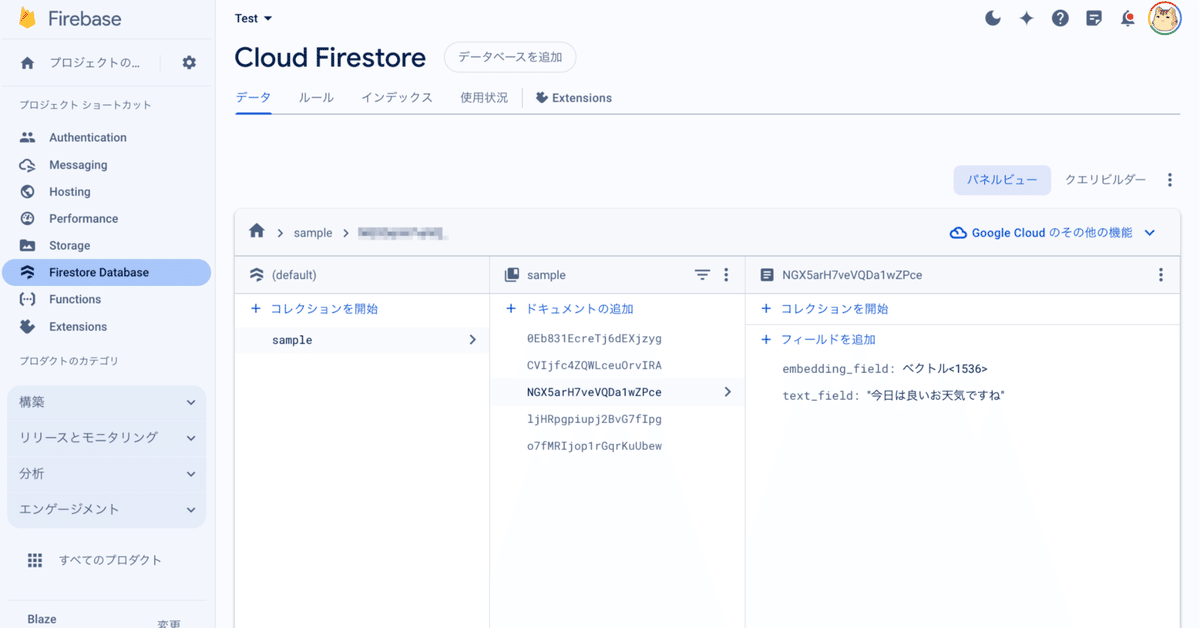
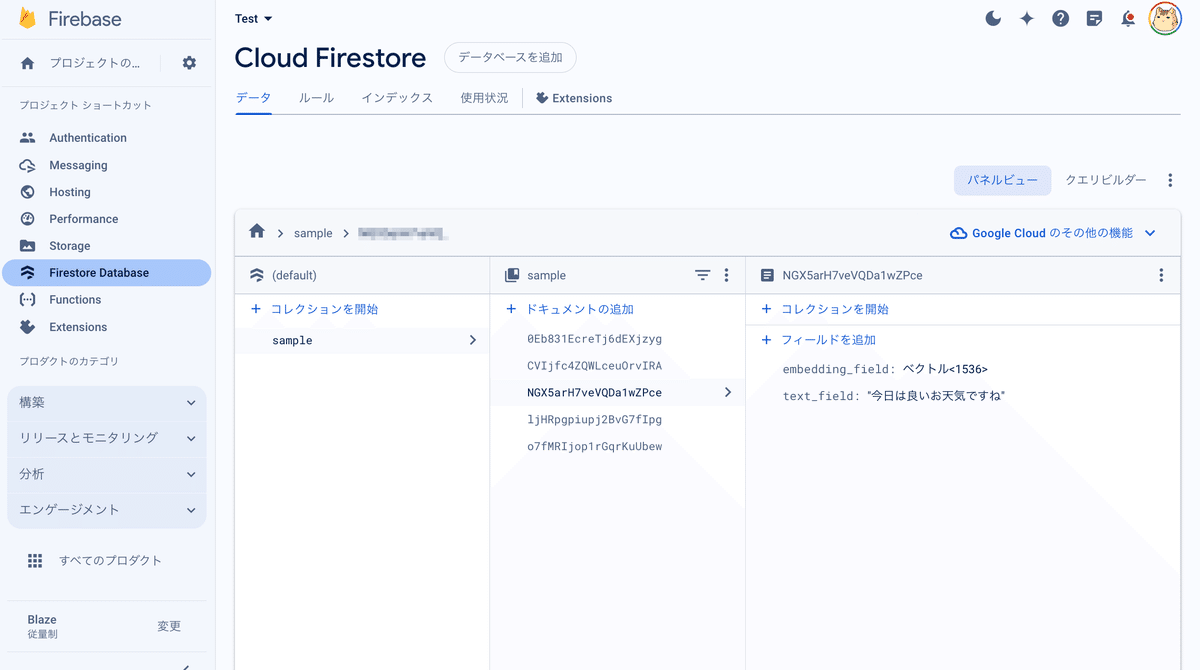
コレクショングループを「sample」、埋め込みの次元を「1536」(OpenAIの埋め込みの次元数)、データベースIDを「(default)」としています。
$ gcloud alpha firestore indexes composite create \
--collection-group=sample \
--query-scope=COLLECTION \
--field-config field-path=embedding_field,vector-config='{"dimension":"1536", "flat": "{}"}' \
--database="(default)"2-2. ベクトルインデックスの一覧の表示
(1) 以下のコマンドを実行。
プロジェクトIDとデータベースIDを確認します。
$ gcloud alpha firestore indexes composite list --database="(default)"---
fields:
- fieldPath: __name__
order: ASCENDING
- fieldPath: embedding_field
vectorConfig:
dimension: 1536
flat: {}
name: projects/<プロジェクトID>/databases/(default)/collectionGroups/sample/indexes/<インデックスID>
queryScope: COLLECTION
state: READY2-3. ベクトルインデックスの削除
$ gcloud alpha firestore indexes composite delete <インデックスID> --database="(default)"今回はベクトルインデックスを使うので、削除は使用後にします。
3. ベクトルインデックスへのデータ追加
(1) 「Firebase」のコンソールで「サービスアカウントキー」(serviceAccountKey.json)を取得。
(2) 以下のコードを作成して実行。
<OpenAI_APIキー>には自分のAPIキーを入力してください。
import os
import firebase_admin
from openai import OpenAI
from firebase_admin import credentials, firestore
from google.cloud.firestore_v1.vector import Vector
# ====================
# OpenAIの前準備
# ====================
# 環境変数の準備
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIキー>"
# クライアントの準備
client = OpenAI()
# 埋め込み関数の準備
def embedding(texts):
response = client.embeddings.create(
input=texts,
model="text-embedding-3-small"
)
return [d.embedding for d in response.data]
# ====================
# Firestoreの前準備
# ====================
# Firestoreの前準備
cred = credentials.Certificate("serviceAccountKey.json")
default_app = firebase_admin.initialize_app(cred)
firestore_client = firestore.client()
collection = firestore_client.collection("sample")
# ====================
# ベクトルインデックスへのデータ追加
# ====================
# 対象テキスト
target_texts = [
"好きな食べ物は何ですか?",
"どこにお住まいですか?",
"朝の電車は混みますね",
"今日は良いお天気ですね",
"最近景気悪いですね"
]
# 埋め込みベクトルの生成
target_embeds = embedding(target_texts)
# ベクトルインデックスへのデータ追加
for i in range(len(target_texts)):
doc = {
"text_field": target_texts[i],
"embedding_field": Vector(target_embeds[i]),
}
collection.add(doc)(3) Firestoreコンソールでデータ追加を確認。
4. ベクトル検索
(2) 以下のコードを作成して実行。
<OpenAI_APIキー>には自分のAPIキーを入力してください。
import os
import firebase_admin
from openai import OpenAI
from firebase_admin import credentials, firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
# ====================
# OpenAIの前準備
# ====================
# 環境変数の準備
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIキー>"
# クライアントの準備
client = OpenAI()
# 埋め込み関数の準備
def embedding(texts):
response = client.embeddings.create(
input=texts,
model="text-embedding-3-small"
)
return [d.embedding for d in response.data]
# ====================
# Firestoreの前準備
# ====================
# Firestoreの前準備
cred = credentials.Certificate("serviceAccountKey.json")
default_app = firebase_admin.initialize_app(cred)
firestore_client = firestore.client()
collection = firestore_client.collection("sample")
# ====================
# ベクトル検索
# ====================
# 入力テキスト
in_texts = [
"今日は雨振らなくてよかった"
]
# 埋め込みベクトルの生成
in_embeds = embedding(in_texts)
# ベクトル検索
snapshot = collection.find_nearest(
vector_field="embedding_field",
query_vector=Vector(in_embeds[0]),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=1).get()
# 検索結果の確認
for doc in snapshot:
print(f"id: {doc.id}")
print(f"text_field: {doc.get('text_field')}")
print("---")id: NGX5arH7veVQDa1wZPce
text_field: 今日は良いお天気ですね近傍検索は、collection.find_nearest()で行います。
・vector_field : 埋め込みベクトルを持つフィールド
・query_vector : クエリベクトル (Vector)
・distance_measure : ベクトル距離のオプション (EUCLIDEAN、COSINE、DOT_PRODUCT)
・limit : 検索数
ベクトル距離のオプションは、次のとおりです。
・EUCLIDEAN : ベクトル間の EUCLIDEAN 距離を測定。
詳しくはユークリッドを参照してください。
・COSINE : ベクトル間の角度に基づいてベクトルを比較。
ベクトルの大きさに基づかない類似度を測定できます。COSINE 距離ではなく、単位正規化されたベクトルで DOT_PRODUCT を使用することをおすすめします。これは数学的に同等であるため、性能が向上します。詳細しくはコサイン類似度を参照してください。
・DOT_PRODUCT : COSINEに似ていまるが、ベクトルの大きさの影響を受ける。
詳しくはドット積を参照してください。
「今日は雨振らなくてよかった」に一番近い言葉は「今日は良いお天気ですね」であることがわかりました。