
Open-R1 の概要

以下の記事が面白かったので、簡単にまとめました。
1. DeepSeek-R1
難しい数学の問題に苦労したことがあるなら、長く考えて慎重に取り組むことがいかに有益であるかを知っているでしょう。「OpenAI o1」は、Reasoning中により多くの計算を使用することで LLM が同じことを行うように学習すると、数学、コーディング、論理などのReasoningタスクを解く能力が大幅に向上することを示しました。
しかし、OpenAIのReasoningモデルの背後にあるレシピは秘密でした。そんな中、先週「DeepSeek」は「DeepSeek-R1」をリリースし、すぐにインターネットを騒がせるまででした。
「DeepSeek-R1」は、「o1」と同等かそれ以上の性能を発揮するだけでなく、学習レシピの重要な手順を概説した詳細な技術レポートが付属していました。このレシピにはいくつかの革新が盛り込まれており、最も注目すべきは、人間の監督なしにReasoningをベースLLMに教えるための純粋な強化学習の適用です。下の図に示すように、有能なベースLLMと高品質なReasoningデータにアクセスできれば、強力なReasoningモデルの作成は非常に簡単になりました。

2. Open-R1
ただし、「DeepSeek-R1」のリリースでは、次のようないくつかの疑問が残ります。
・データ収集
Reasoning固有のデータセットはどのようにキュレーションされたか。
・モデルの学習
「DeepSeek」から学習コードがリリースされていないため、どのハイパーパラメータが最も効果的か、また、さまざまなモデルファミリやスケール間でハイパーパラメータがどのように異なるかは不明。
・スケーリングの法則
Reasoningモデルの学習におけるコンピューティングとデータのトレードオフは何か。
これらの疑問を解決するため、「Open-R1」プロジェクトは立ち上がりました。これは、「DeepSeek-R1」のデータと学習パイプラインを体系的に再構築し、その主張を検証し、オープンなReasoningモデルの限界を押し広げる取り組みです。「Open-R1」を構築することで、強化学習がどのようにReasoningを強化できるかについて透明性を提供し、再現可能な洞察をオープンソースコミュニティと共有し、これらの手法を活用する将来のモデルの基盤を構築することを目指しています。
この記事では、「DeepSeek-R1」の背後にある主要な要素、複製を計画している部分、「Open-R1」プロジェクトへの貢献方法について説明します。
3. DeepSeek-R1 の学習手順
「DeepSeek-R1 」は、 「DeepSeek-V3」を基盤として構築されたReasonigモデルです。優れたReasoningモデルと同様に、強力なベースLLMから始まりますが、「DeepSeek-V3」はまさにそれです。この 671B MoE (Mixture of Experts) は、「Sonnet 3.5」や「GPT-4o」などの重量級モデルと同等の性能を発揮します。特に印象的なのは、「MTP」(Multi Token Prediction)、「MLA」(Multi-Head Latent Attention) などのアーキテクチャの変更と、大量の (本当に大量の) ハードウェア最適化により、学習のコスト効率がわずか 550 万ドルだったことです。
「DeepSeek」は、それぞれ異なる学習アプローチを持つ2つのモデル、「DeepSeek-R1-Zero」と「DeepSeek-R1」も導入しました。「DeepSeek-R1-Zero」は、教師ありのファインチューニングをまったく行わず、強化学習 (RL) に完全に依存して、「GRPO」を使用してプロセスを効率化しました。モデルをガイドするために、回答の精度と構造に基づいてフィードバックを提供するシンプルな報酬システムが使用されました。このアプローチにより、モデルは、問題をステップに分割したり、独自の出力を検証したりするなど、有用なReasoningスキルを開発できました。ただし、その応答は明確さに欠け、読みにくい場合がよくありました。
ここで 「DeepSeek-R1」の出番です。「DeepSeek-R1」は「コールドスタート」フェーズから始まり、明瞭性と読みやすさを向上させるために、慎重に作成された少数の例を微調整しました。そこから、人間の好みに基づいた検証可能な報酬の両方で低品質の出力を拒否するなど、より多くの RL と改良のステップを経て、適切にReasoningできるだけでなく、洗練された一貫性のある回答を生成するモデルを作成しました。

4. Open-R1 の計画
「DeepSeek-R1」のリリースはコミュニティにとって素晴らしい恩恵ですが、すべてがリリースされたわけではありません。モデルの重みは公開されていますが、モデルの学習に使用されるデータセットとコードは公開されていません。
「Open-R1」の目標は、これらの最後の欠けている部分を構築し、研究コミュニティと業界コミュニティ全体がこれらのレシピとデータセットを使用して同様のモデルまたはより優れたモデルを構築できるようにすることです。これをオープンに行うことで、コミュニティの誰もが貢献できます。
計画は、次のとおりです。
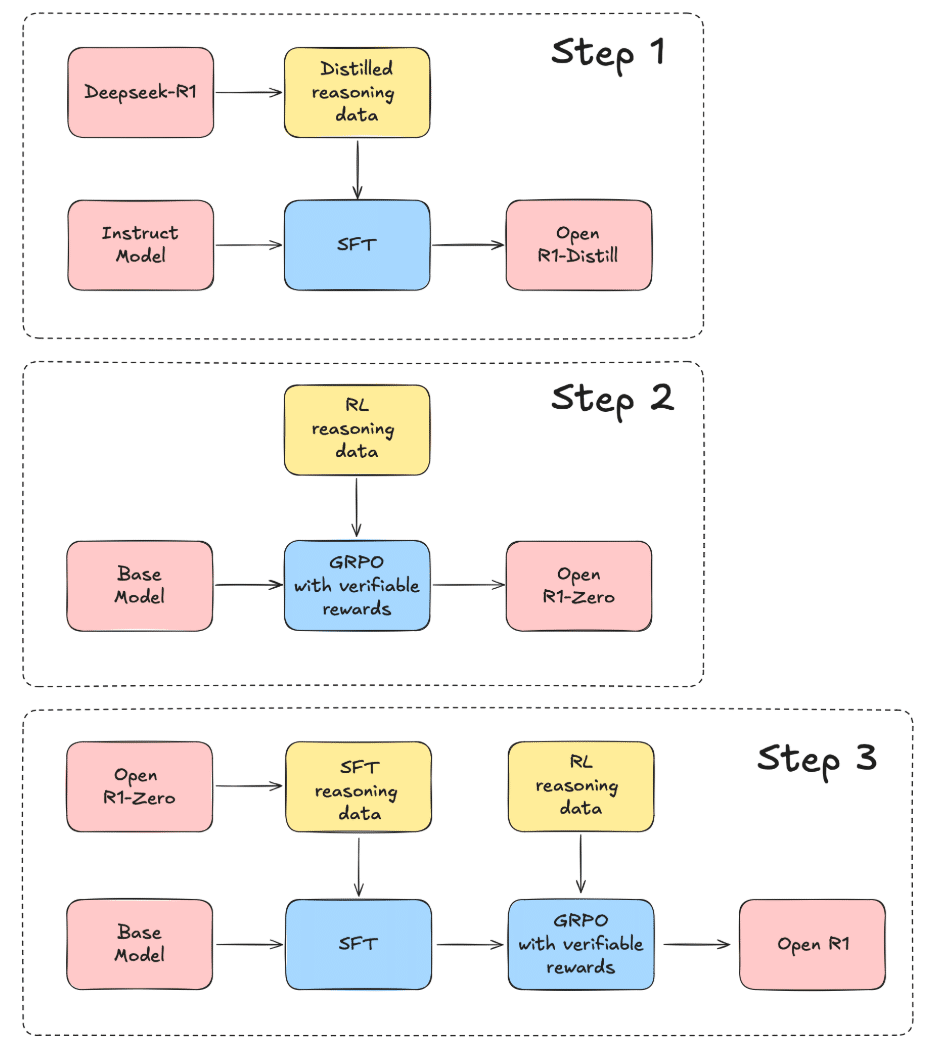
・ステップ1
「DeepSeek-R1」から高品質のReasoningデータセットを抽出して、「R1-Distill」モデルを複製。
・ステップ2
「DeepSeek」が「R1-Zero」の作成に使用した純粋なRLパイプラインを複製。これには、数学、推論、コード用の新しい大規模なデータセットのキュレーションが含まれる。
・ステップ3
多段階の学習を通じて、「ベースモデル → SFT → RL」に進むことができることを示す。
合成データセットにより、誰でも既存のLLMまたは新しいLLMをファインチューニングするだけで、Reasoningモデルにファインチューニングできるようになります。RL を含む学習レシピは、誰もがゼロから同様のモデルを構築するための出発点となり、研究者はさらに高度な方法を構築できるようになります。
数学データセットに留まるつもりはないことに注意してください。コードのような明らかな分野だけでなく、医学などの科学分野など、Reasoningモデルが大きな影響を与える可能性のある他の分野を調査することには多くの可能性があります。
この取り組みは、結果を再現するだけではなく、コミュニティと洞察を共有することです。何が機能し、何が機能しないか、そしてその理由を文書化することで、非生産的な方法で他の人が時間と計算を無駄にすることがないようにしたいと考えています。