Google Colab で SmolLM2 を試す

「Google Colab」で「SmolLM2」を試したのでまとめました。
1. SmolLM2
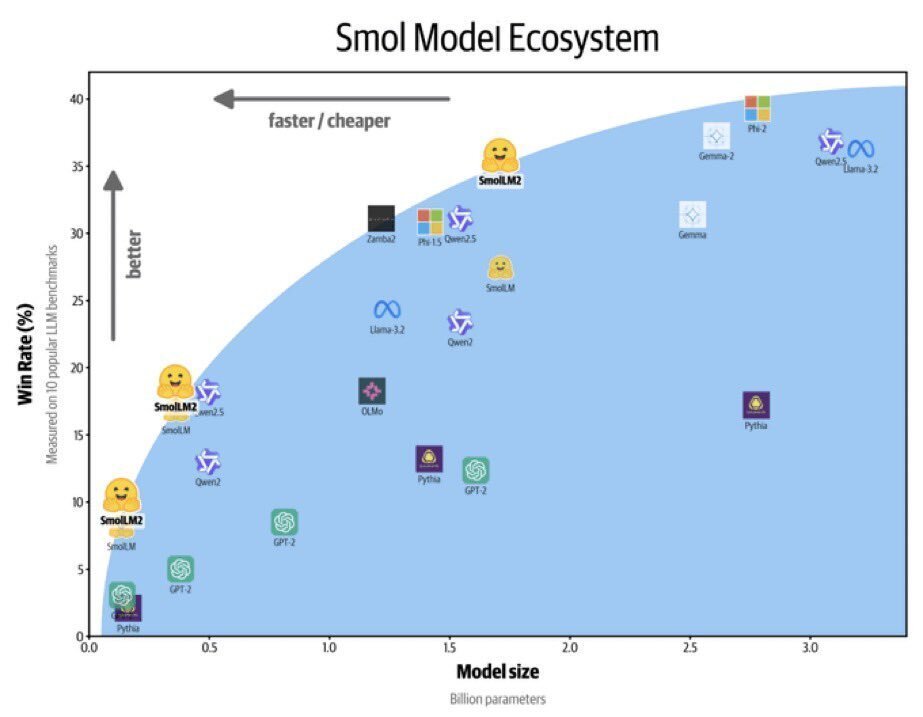
「SmolLM2」は、135M、360M、1.7Bの3つのサイズで利用できるコンパクトな言語モデルのファミリーです。デバイス上で実行できるほど軽量でありながら、幅広いタスクを解決できます。
1.7Bは、特に指示に従うこと、知識、推論、数学において、前身の「SmolLM1-1.7B」と比べて大幅な進歩を示しています。このモデルは「FineWeb-Edu」「DCLM」「The Stack」などの多様なデータセットの組み合わせと、私たちがキュレートして近日中にリリースする予定の新しい数学およびコーディングデータセットを使用して、11兆のトークンで学習しました。公開データセットと独自にキュレートしたデータセットの組み合わせを使用して、SFTを通じてInstruct版を開発しました。次に、「UltraFeedback」を使用してDPOを適用しました。
指示モデルは、Argillaが開発した「Synth-APIGen-v0.1」などのデータセットのおかげで、テキストの書き換え、要約、関数の呼び出しなどのタスクもサポートします。
2. Colabでの実行
Google Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install transformers(2) トークナイザーとモデルの準備。
今回は、「HuggingFaceTB/SmolLM2-1.7B-Instruct」を使いました。
from transformers import AutoModelForCausalLM, AutoTokenizer
# トークナイザーとモデルの準備
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(
"HuggingFaceTB/SmolLM2-1.7B-Instruct"
)
model = AutoModelForCausalLM.from_pretrained(
"HuggingFaceTB/SmolLM2-1.7B-Instruct"
).to("cuda")(3) 推論の実行。
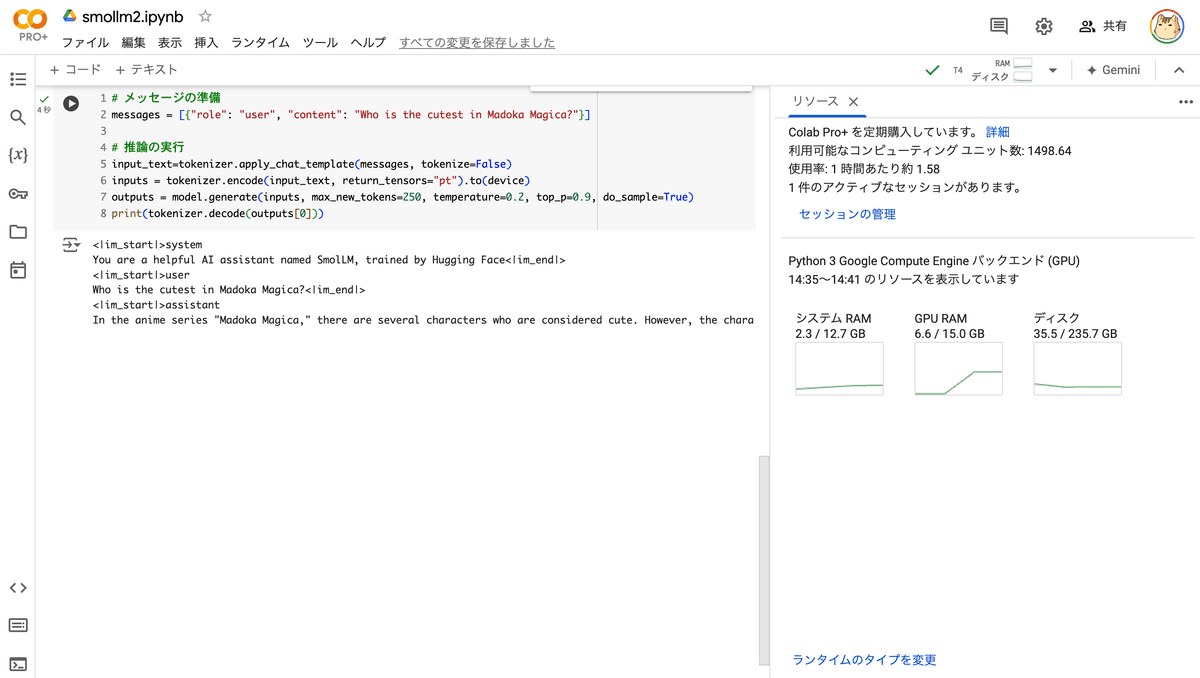
# メッセージの準備
messages = [{"role": "user", "content": "Who is the cutest in Madoka Magica?"}]
# 推論の実行
input_text=tokenizer.apply_chat_template(messages, tokenize=False)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(inputs, max_new_tokens=250, temperature=0.2, top_p=0.9, do_sample=True)
print(tokenizer.decode(outputs[0]))<|im_start|>system
You are a helpful AI assistant named SmolLM, trained by Hugging Face<|im_end|>
<|im_start|>user
Who is the cutest in Madoka Magica?<|im_end|>
<|im_start|>assistant
In the anime series "Madoka Magica," there are several characters who are considered cute. However, the character that is often cited as the cutest is Madoka Kaname. She is a kind and gentle protagonist who is initially unaware of the supernatural world she is entering. Her innocence and purity make her a very endearing character.<|im_end|>
【日本語訳】
Q. まどか☆マギカでは誰が一番かわいい?
A. アニメシリーズ「まどか☆マギカ」には、かわいいとされるキャラクターが何人かいます。しかし、最もかわいいとよく言われるキャラクターは、鹿目まどかです。彼女は、最初は自分が入り込んでいる超自然的な世界に気づいていない、優しくて穏やかな主人公です。彼女の無邪気さと純粋さは、彼女をとても愛らしいキャラクターにしています。