
Quanto と Diffusers による Diffusion Transformers のメモリ削減

以下の記事が面白かったので、簡単にまとめました。
・Memory-efficient Diffusion Transformers with Quanto and Diffusers
1. はじめに
ここ数か月間、高解像度のText-to-Image (T2I) にTransformerベースのdiffusionバックボーンが使用されるようになりました。これらのモデルは、初期のdiffusionモデルの多くで普及していたUNetアーキテクチャではなく、diffusionプロセスの構成要素としてTransformerアーキテクチャを使用します。Transformerの性質により、これらのバックボーンは0.6Bから8Bパラメータを持つモデルで優れたスケーラビリティを示します。
モデルが大きくなるにつれて、メモリ要件が増加します。diffusionパイプラインは通常、テキストエンコーダー、diffusionバックボーン、画像デコーダーという複数のコンポーネントで構成されるため、問題は深刻化します。さらに、最新のdiffusionパイプラインでは複数のテキストエンコーダーが使用されます。たとえば、「Stable Diffusion 3」の場合は3つあります。FP16精度を使用してSD3の推論を実行するには、18.765 GBのGPUメモリが必要になります。
これらの高いメモリ要件により、これらのモデルをコンシューマーGPU で使用することが困難になり、採用が遅れ、実験が困難になる可能性があります。この記事では、QuantoとDiffusersを活用して、Transformerベースのdiffusionパイプラインの消費メモリを削減する方法を示します。
2. 実験の準備
「Quanto」の詳細については、この記事を参照してください。「Quanto」は PyTorch上に構築された量子化ツールキットです。これは、ハードウェア最適化のためのツール セットである「HuggingFace Optimum」の一部になります。
モデル量子化は LLM実践者の間では人気のツールですが、diffusionモデルではそれほど人気がありません。「Quanto」は、このギャップを埋め、品質の低下をほとんどまたはまったく伴わずにメモリを節約するのに役立ちます。
ベンチマークの目的で、次の環境で「H100 GPU」を使用します。
・CUDA 12.2
・PyTorch 2.4.0
・Diffusers (this commit)
・Quanto (this commit)
特に指定がない限り、FP16で計算を実行するのがデフォルトです。数値の不安定性の問題を防ぐため、VAEを量子化しないことを選択しました。ベンチマーク コードはここにあります。
この記事の執筆時点での、Diffusersでテキストから画像を生成するための Transformerベースのdiffusionパイプラインは、次のとおりです。
・PixArt-Alpha・PixArt-Sigma
・Stable Diffusion 3
・Hunyuan DiT
・Lumina
・Aura Flow
また、TransformerベースのText-to-Videoパイプラインである「Latte」もあります。
簡潔にするために、調査は「PixArt-Sigma」「Stable Diffusion 3」「Aura Flow」の3つに限定しています。以下の表は、それらの「diffusionバックボーン」のパラメータ数を示しています。

3. Quanto を使用した DiffusionPipeline の量子化
「Quanto」を使用したモデルの量子化は簡単です。
from optimum.quanto import freeze, qfloat8, quantize
from diffusers import PixArtSigmaPipeline
import torch
pipeline = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", torch_dtype=torch.float16
).to("cuda")
quantize(pipeline.transformer, weights=qfloat8)
freeze(pipeline.transformer)量子化したいものを指定して、量子化するモジュールで quantize() を呼び出します。上記のケースでは、パラメータのみを量子化し、アクティベーションはそのままにします。FP8データ型に量子化します。最後に、freeze() を呼び出して、元のパラメータを量子化されたパラメータに置き換えます。
その後、このパイプラインを通常どおりに呼び出すことができます。
image = pipeline("ghibli style, a fantasy landscape with castles").images[0]
FP8を使用すると、レイテンシがわずかに高くなるものの、品質の低下はほとんどなく、次のメモリ節約が実現します。

同じ方法で「テキストエンコーダー」を量子化できます。
quantize(pipeline.text_encoder, weights=qfloat8)
freeze(pipeline.text_encoder)「テキストエンコーダー」もTransformerモデルであり、量子化することができます。「テキストエンコーダー」と「diffusionバックボーン」の両方を量子化すると、メモリが大幅に改善されます。

「テキストエンコーダー」を量子化すると、前の場合と非常によく似た結果が生成されます。

4. 観察の一般性
「テキストエンコーダー」を「diffusionバックボーン」と一緒に量子化すると、試したモデルでは一般的に機能します。「Stable Diffusion 3」は、3つの異なる「テキスト エンコーダー」を使用するため、特殊なケースです。2番目の「テキスト エンコーダー」を量子化してもうまく機能しないことが判明したため、次の代替案をお勧めします。
・最初のテキストエンコーダー (CLIPTextModelWithProjection) のみ量子化
・3番目のテキスト エンコーダー (T5EncoderModel) のみ量子化
・最初と3番目のテキスト エンコーダーを量子化
以下の表は、さまざまな「テキストエンコーダー」の量子化の組み合わせで予想されるメモリ節約を示しています (diffusion transformerはすべてのケースで量子化)。

5. その他の調査結果
5-1. bfloat16
「H100」「4090」など「bfloat16」がサポートされているGPUは、「Precision」で「bfloat16」を使用した方が高速です。以下の表は、「H100」リファレンス ハードウェアで測定された「PixArt」の数値を示しています。

5-2. qint8
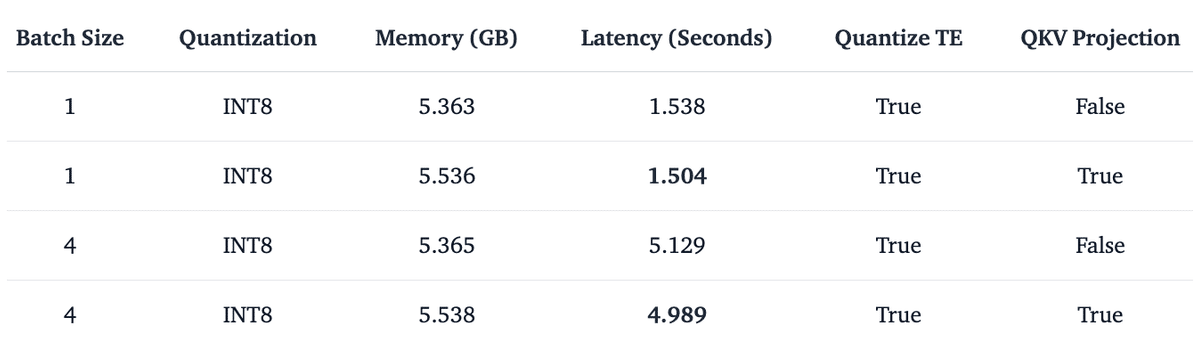
「Quantization」で「qfloat8」より「qint8」を使用した方が一般的に推論が高速です。この効果は、アテンションQKV Projectionを水平方向に融合すると (Diffusers で fuse_qkv_projections() を呼び出す)、より顕著になり、int8 カーネルの次元が厚くなり、計算が高速化されます。「PixArt」の証拠を以下に示します。
5-3. qint4
さらに、「bfloat16」を使用する際に「Quantization」で「qint4」を試しました。これは、他の構成がまだサポートされていないため、「H100」の 「bfloat16」にのみ適用されます。「qint4」を使用すると、推論のレイテンシが増加するという代償を払って、メモリ消費のさらなる改善が期待できます。「int4」の計算にはネイティブハードウェアサポートがないため、レイテンシの増加が予想されます。重みは4bitを使用して転送されますが、計算は依然として「bfloat16」で行われます。以下の表は、「PixArt-Sigma」の結果を示しています。

ただし、「INT4」の積極的な離散化により、最終結果が影響を受ける可能性があることに注意してください。これが、Transformerベースのモデル全般で、最終投影レイヤーを量子化から除外する理由です。「Quanto」では、次の方法でこれを行います。
quantize(pipeline.transformer, weights=qint4, exclude="proj_out")
freeze(pipeline.transformer)「proj_out」は、pipeline.transformer の最終レイヤーに対応します。以下の表は、さまざまな設定の結果を示しています。

失われた画像品質を回復するには、「Quanto」でもサポートされている量子化を考慮した学習を実行するのが一般的です。
この記事の実験結果はすべて、こちらでご覧いただけます。
【おまけ】 Quantoでのdiffusersモデルの読み込みと保存
Quantoでのdiffusersモデルの読み込みと保存の手順は、次のとおりです。
from diffusers import PixArtTransformer2DModel
from optimum.quanto import QuantizedPixArtTransformer2DModel, qfloat8
model = PixArtTransformer2DModel.from_pretrained("PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", subfolder="transformer")
qmodel = QuantizedPixArtTransformer2DModel.quantize(model, weights=qfloat8)
qmodel.save_pretrained("pixart-sigma-fp8")結果のチェックポイントのサイズは、元の 2.44 GB ではなく 587 MB になります。これをロードできます。
from optimum.quanto import QuantizedPixArtTransformer2DModel
import torch
transformer = QuantizedPixArtTransformer2DModel.from_pretrained("pixart-sigma-fp8")
transformer.to(device="cuda", dtype=torch.float16)これを DiffusionPipelineで使用します。
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
transformer=None,
torch_dtype=torch.float16,
).to("cuda")
pipe.transformer = transformer
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe(prompt).images[0]将来的には、パイプラインを初期化するときにtransformerを直接渡して、これが機能することが期待できます。
pipe = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
- transformer=None,
+ transformer=transformer,
torch_dtype=torch.float16,
).to("cuda")QuantizedPixArtTransformer2DModel の実装は、こちらで参照できます。
【おまけ】 Tips
・要件に応じて、異なるパイプラインモジュールに異なるタイプの量子化を適用したい場合があります。たとえば、「テキストエンコーダー」にはFP8を使用し、diffusion transformerには INT8 を使用できます。Diffusers と Quanto の柔軟性により、これはシームレスに実行できます。
・ユースケースを最適化するために、enable_model_cpu_offload() などのdiffusersの他のメモリ最適化手法と量子化を組み合わせることもできます。
この記事が気に入ったらサポートをしてみませんか?