Google Colab で Tanuki-8x8B を試す

「Google Colab」で「Tanuki-8x8B」を試したのでまとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. Tanuki-8x8B
「Tanuki-8x8B」は、経産省及びNEDOが進める日本国内の生成AI基盤モデル開発を推進する「GENIAC」プロジェクトにおいて、松尾・岩澤研究室が開発・公開した日本語LLMです。
フルスクラッチで開発されたモデルで、Apache License 2.0に基づき、研究および商業目的での自由な利用が可能です。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
推論方法はいくつかありますが、最推奨のvLLMはビルドに時間がかかるので、推奨のTransformersかつ少メモリでうごくAWQを使います。
# パッケージのインストール
!pip install -U transformers accelerate bitsandbytes
!pip install flash_attn --no-build-isolation
!pip install autoawq(2) バージョンを整える。
Colabでは上記コマンドのみでは実行時にエラーになったので、バージョンを整えます。
# バージョンを整える
!pip install pyarrow==14.0.1
!pip install torch==2.4.0 torchvision==0.19.0+cu121 torchaudio==2.4.0+cu121(3) メニュー「ランタイム→セッションを再起動」で再起動。
(4) モデルとトークナイザーとストリーマーの準備。
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
# モデルとトークナイザーとストリーマーの準備
model_name = "team-hatakeyama-phase2/Tanuki-8x8B-dpo-v1.0-AWQ"
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(
model_name
)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)(5) 推論の実行。
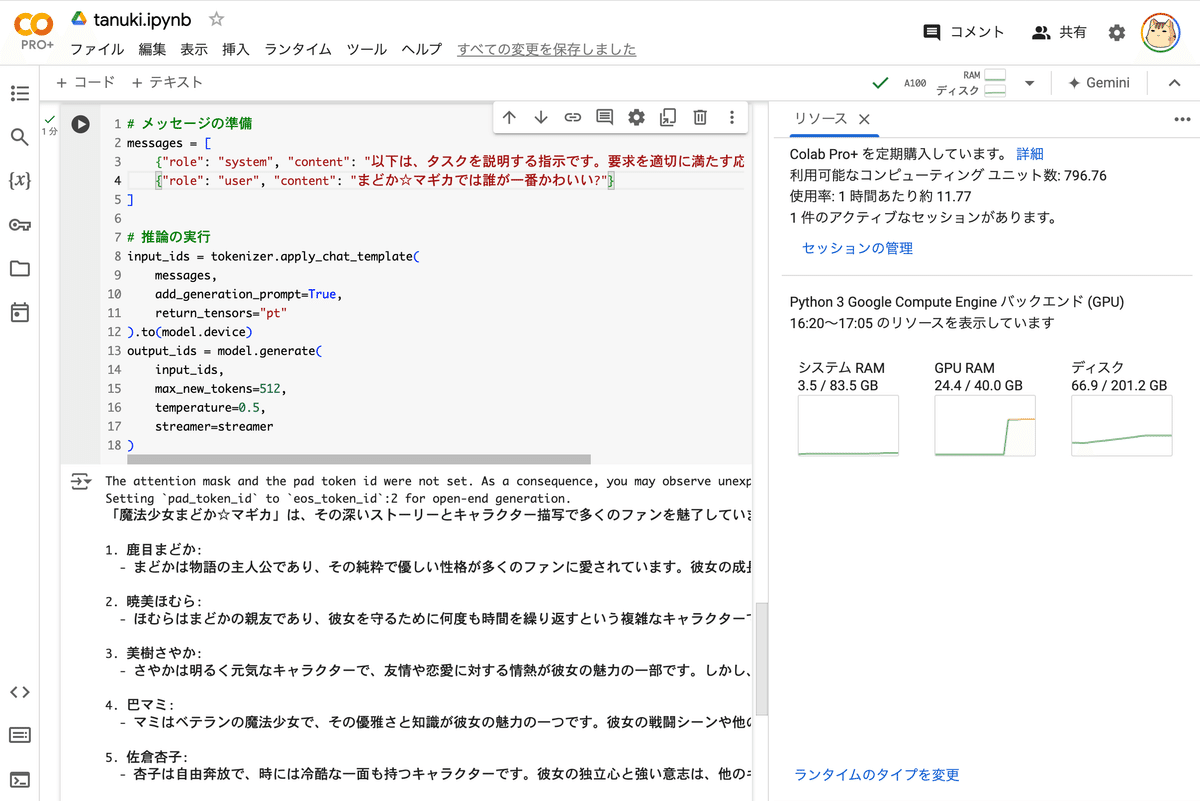
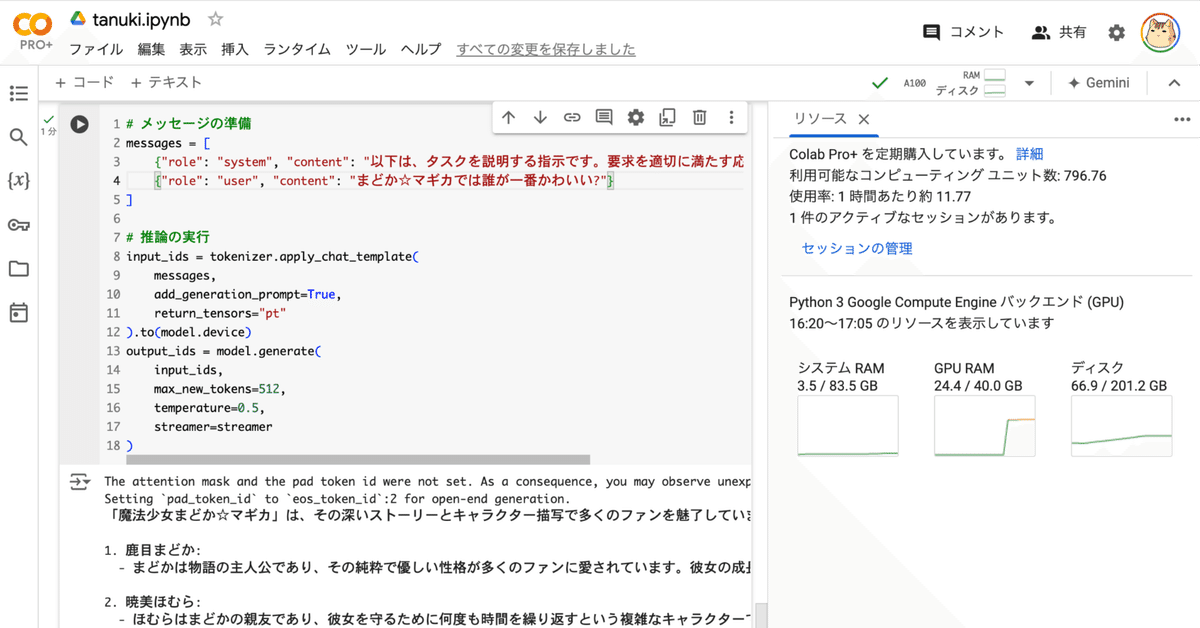
# メッセージの準備
messages = [
{"role": "system", "content": "以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。"},
{"role": "user", "content": "まどか☆マギカでは誰が一番かわいい?"}
]
# 推論の実行
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
output_ids = model.generate(
input_ids,
max_new_tokens=512,
temperature=0.5,
streamer=streamer
)「魔法少女まどか☆マギカ」は、その深いストーリーとキャラクター描写で多くのファンを魅了しています。
この作品には多くの魅力的なキャラクターがいますが、誰が一番かわいいかという質問は主観的なものであり、人それぞれの好みによって異なるでしょう。以下にいくつかのキャラクターを紹介します:
1. 鹿目まどか:
- まどかは物語の主人公であり、その純粋で優しい性格が多くのファンに愛されています。彼女の成長と自己犠牲の精神は、多くの人々の心を打ちます。
2. 暁美ほむら:
- ほむらはまどかの親友であり、彼女を守るために何度も時間を繰り返すという複雑なキャラクターです。彼女の強さと決意、そして時折見せる優しさが魅力的です。
3. 美樹さやか:
- さやかは明るく元気なキャラクターで、友情や恋愛に対する情熱が彼女の魅力の一部です。しかし、彼女の行動には悲劇的な側面もあり、それがさらに彼女の魅力を引き立てています。
4. 巴マミ:
- マミはベテランの魔法少女で、その優雅さと知識が彼女の魅力の一つです。彼女の戦闘シーンや他のキャラクターとの関係性も注目に値します。
5. 佐倉杏子:
- 杏子は自由奔放で、時には冷酷な一面も持つキャラクターです。彼女の独立心と強い意志は、他のキャラクターとは異なる魅力を持っています。
どのキャラクターが「一番かわいい」かは、あなた自身の価値観や好みによるものです。それぞれのキャラクターが持つ独自の魅力を楽しんでください。