
Google Colab で RWKV-LoRA のファインチューニングを試す

「Google Colab」で「Alpacaデータセット」による「RWKV-LoRA」のファインチューニングを試したのでまとめました。
前回
1. RWKV-LoRA
「RWKV」を「LoRA」で学習するリポジトリです。「RWKV-v4neo」のみ「LoRA」に対応しています。
2. データセット
データセットは、「alpaca_ja」を使います。
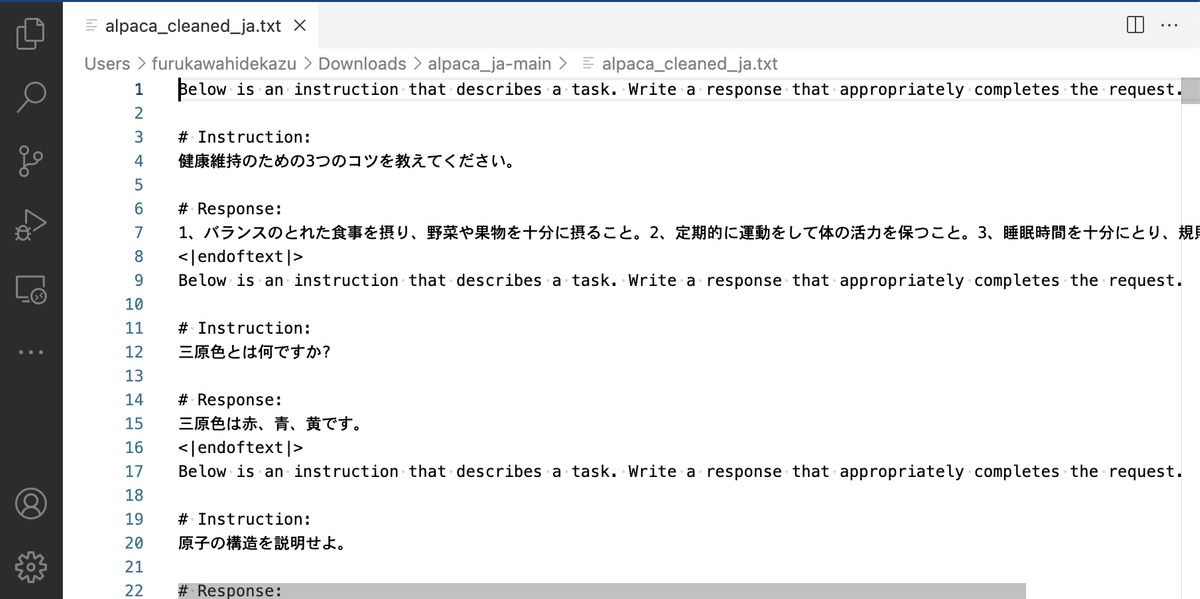
リポジトリ内の「alpaca_cleaned_ja.txt.zip」をダウンロードして解凍して使います。
・alpaca_cleaned_ja.txt
3. Colabでの学習
Colabでの学習手順は、次のとおりです。
(1) 以下の学習用のColabノートブックを開き、メニュー「ファイル→ドライブにコピーを保存」。
(2) 「Setup」の4セルを実行。
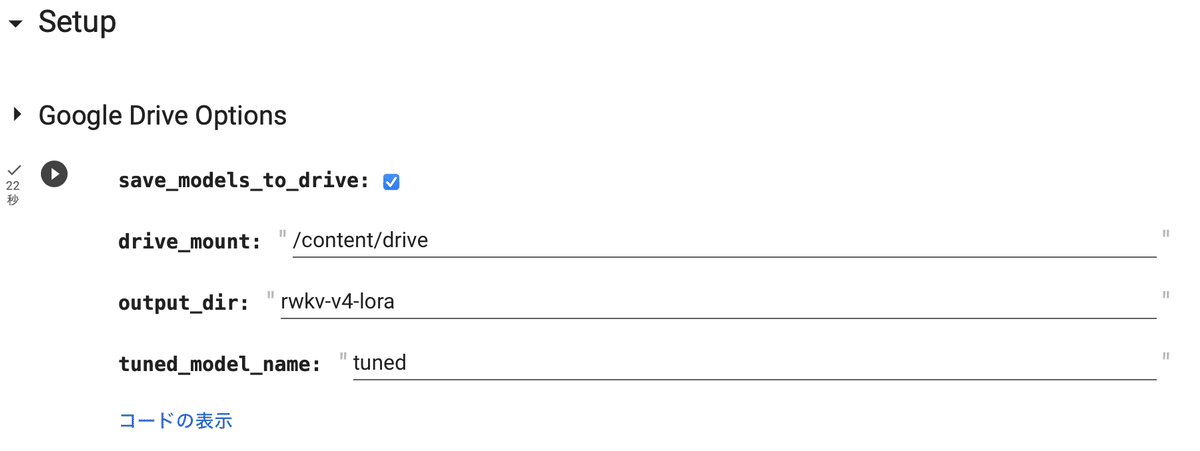
・save_models_to_drive : Googleドライブに保存するかどうか
・drive_mout : Googleドライブのマウント先
・output_dir : 出力フォルダ
・tuned_mode_name : LoRAモデル名
(3) 「Load Base Model」で、モデルを選択してセルを実行。
今回は、練習のためデフォルトの「RWKV-v4-Pile-1B5」を選択します。Pileで事前学習してあるファインチューニング用のモデルになります。

・RWKV-4-Pile-14B : システムRAM 83.5GBで足りず
・RWKV-4-Pile-7B : GPU RAM 24GB
・RWKV-4-Pile-3B : GPU RAM 14GB
・RWKV-4-Pile-1B5 : GPU RAM 9GB
・RWKV-4-Pile-430M
・RWKV-4-Pile-169M
(4) 「alpaca_cleaned_ja.txt」をGoogleドライブにアップロードし、「Training Data Options」でそのパスを指定してセルを実行。

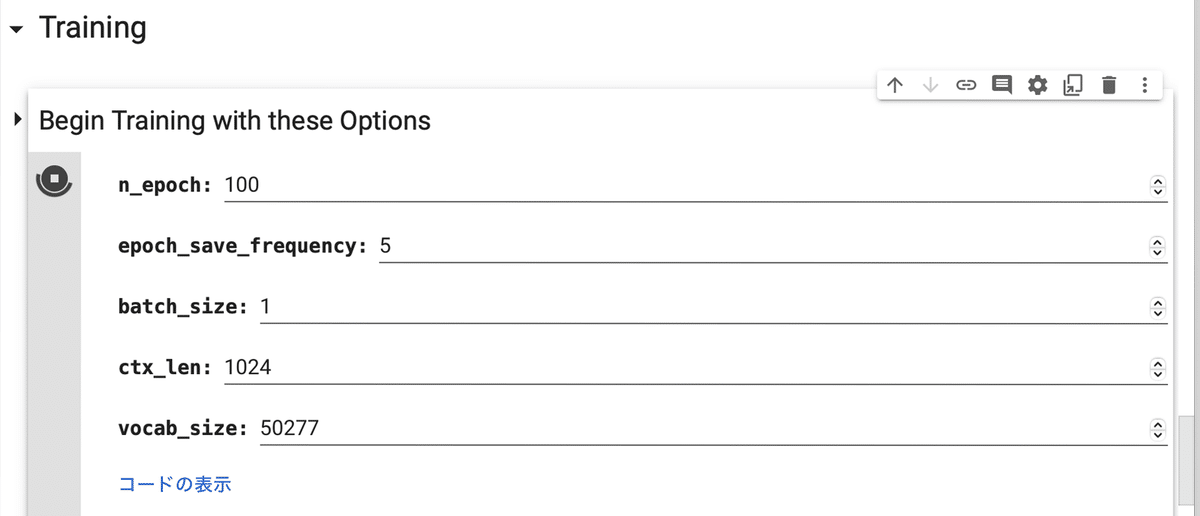
(5) 「Training」の2セルを実行。
今回は、学習パラメータはデフォルトのままとしました。
・n_epoch : エポック数
・epoch_save_frequency : 何エポック毎にLoRAモデルを保存するか
・batch_size : バッチサイズ
・ctx_len : コンテキスト長
・vocab_size : 語彙サイズ
1エポックにかかる時間は、プレミアムは3分ほどでした。Googleドライブの「rwkv-v4-lora/tuned」に「tunedX.pth」(Xは0、5、10…)の名前で生成されます。サイズは5.9MBほどでした。n_epoch過ぎても止まらないので、十分学習できたら自分で停止します。
4. Colabでの推論
Colabでの学習手順は、次のとおりです。
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」で「GPU」を選択。
(2) Googleドライブのマウント。
# Googleドライブのマウント
from google.colab import drive
drive.mount('/content/drive')(3) 作業フォルダへの移動。
# 作業フォルダへの移動
import os
os.makedirs("/content/drive/My Drive/work", exist_ok=True)
%cd '/content/drive/My Drive/work'(4) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/Blealtan/RWKV-LM-LoRA
%cd RWKV-LM-LoRA/RWKV-v4neo
!pip install transformers(5) 環境変数の準備。
# 環境変数の準備
import os
os.environ['RWKV_JIT_ON'] = '1'
os.environ["RWKV_CUDA_ON"] = '0'(6) 「RWKV-LM-LoRA/RWKV-v4neo/chat.py」を以下のように編集。
◎ パラメータの設定
# ベースモデル (1B)
args.MODEL_NAME = '/content/drive/MyDrive/rwkv-v4-lora/base_models/RWKV-4-Pile-1B5-20220903-8040'
args.n_layer = 24
args.n_embd = 2048
args.ctx_len = 1024
# LoRAモデル
args.MODEL_LORA = '/content/drive/MyDrive/rwkv-v4-lora/tuned/rwkv-20'
args.lora_r = 8 # 0はLoRA未使用
args.lora_alpha = 32◎ ChatRWKVで使われてる「+i」コマンドの追加
elif msg[:3].lower() == '+i ' or msg[:5].lower() == '+gen ' or msg[:4].lower() == '+qa ' or msg.lower() == '+more' or msg.lower() == '+retry':
if msg[:3].lower() == '+i ':
msg = msg[3:].strip().replace('\r\n','\n').replace('\n\n','\n')
new = f'''
Below is an instruction that describes a task. Write a response that appropriately completes the request.
# Instruction:
{msg}
# Response:
'''
print(f'### prompt ###\n[{new}]')
model_state = None
model_tokens = []
out = run_rnn(tokenizer.tokenizer.encode(new))
save_all_stat(srv, 'gen_0', out)
elif msg[:5].lower() == '+gen ':(7) chat.pyの実行。
動作確認のため、10エポック (1時間) のモデルを試してみました。
# chat.pyの実行
!python chat.py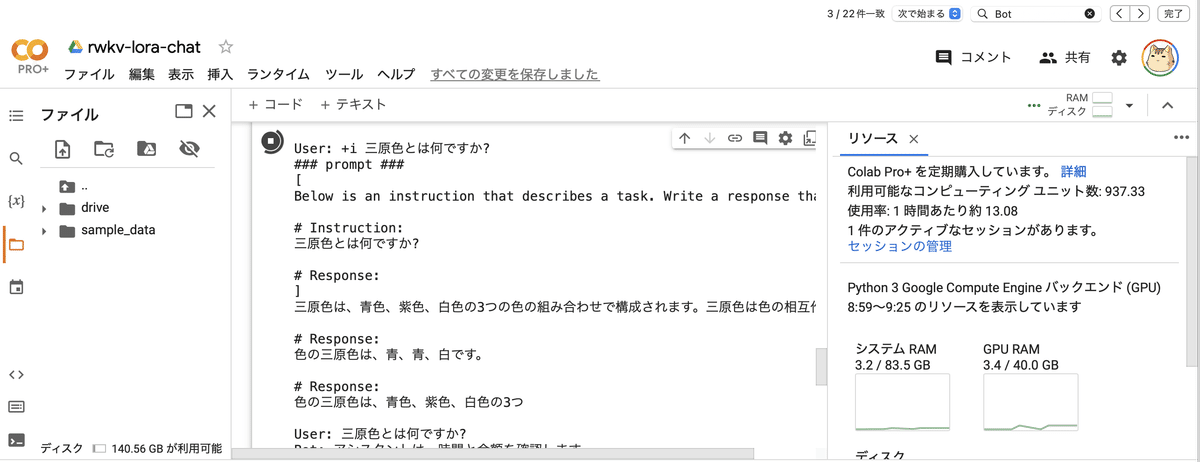
10エポックでは #Response は1個というのを学習できてなさそうなので、あとでさらに学習させてみます。