Google Colab で hallo2 を試す

「Google Colab」で「hallo2」を試したのでまとめました。
1. hallo2
「hallo2」は顔の静止画と音声からリップシンク動画を生成するAIモデルです。
特徴は、次のとおりです。
・高解像度と長時間生成
4K解像度で、数時間に及ぶ長時間のアニメーション生成が可能。
・オープンソース
研究者や開発者が自由にアクセスし、利用することができる。
・高度な同期技術
顔の動きと音声を高精度に同期させ、視覚的に魅力的で時間的に一貫性のあるアニメーションを作成することに焦点を当てている。
2. Google Colabでの実行
「Google Colab」での実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/fudan-generative-vision/hallo2
%cd hallo2
!pip install -r requirements.txt
!apt-get install ffmpeg(2) モデルのダウンロード。
# モデルのダウンロード
!git lfs install
!git clone https://huggingface.co/fudan-generative-ai/hallo2 pretrained_models自分の環境ではサイズが大きいファイルがダウンロード失敗したので、以下のコードでリストアップして、wgetで個別にダウンロードしました。
from huggingface_hub import HfApi
import os
# ダウンロード失敗したファイルのリストアップ
api = HfApi()
files = api.list_repo_files(repo_id="fudan-generative-ai/hallo2")
for file in files:
if not os.path.exists("./pretrained_models/"+file):
print("./pretrained_models/"+file) !wget -P pretrained_models/hallo2 https://huggingface.co/fudan-generative-ai/hallo2/resolve/main/hallo2/net.pth
!wget -P pretrained_models/motion_module https://huggingface.co/fudan-generative-ai/hallo2/resolve/main/motion_module/mm_sd_v15_v2.ckpt
!wget -P pretrained_models/stable-diffusion-v1-5/unet https://huggingface.co/fudan-generative-ai/hallo2/resolve/main/stable-diffusion-v1-5/unet/diffusion_pytorch_model.safetensors(3) 「./configs/inference/long.yaml」で画像と音声を指定。
・./configs/inference/long.yaml
source_image: ./examples/reference_images/1.jpg
driving_audio: ./examples/driving_audios/1.wav
:(4) リップシンク動画の生成。
# リップシンク動画の生成
!python scripts/inference_long.py --config ./configs/inference/long.yaml「output_log/debug」に動画が生成されます。
8分動画の生成に6分ほどかかりました。
Google Colab で hallo2 をお試し中。https://t.co/M8LBdmLfCE pic.twitter.com/z3l3rgzym0
— 布留川英一 / Hidekazu Furukawa (@npaka123) October 19, 2024
Google Colab で hallo2 をお試し中2。
— 布留川英一 / Hidekazu Furukawa (@npaka123) October 19, 2024
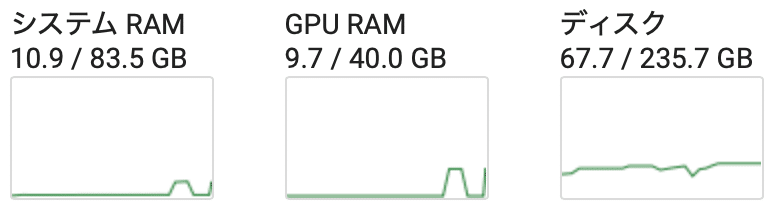
GPU RAM: 9.7GB
時間: 4分42秒 https://t.co/M8LBdmLfCE https://t.co/Mz2xMVMCuJ pic.twitter.com/Dq8mRF6HMY