
Transformers でサポートされている量子化 bitsandbytes と auto-gptq の比較

以下の記事が面白かったので、かるくまとめました。
・Overview of natively supported quantization schemes in 🤗 Transformers
1. はじめに
この記事は、「Transformers」でサポートされている量子化 「bitsandbytes」と「auto-gptq」を比較し、どちらをを選択すべきかを決定できるようにすることを目的としています。
量子化は、主に次の2つの目的のために利用されます。
・小型デバイス上で大規模なモデルの推論の実行
・量子化されたモデルをベースにアダプターをファインチューニング
2. bitsandbytes の利点
2-1. 簡単
「bitsandbytes」は、量子化されたモデルを入力データで調整する必要がないため (Zero-Shot量子化とも呼ばれる)、あらゆるモデルを量子化する最も簡単な方法です。torch.nn.Linear モジュールが含まれている限り、任意のモデルをそのまま量子化できます。新しいアーキテクチャがTransformersに追加されるたびに、アクセラレータの device_map="auto" でロードできる限り、ユーザーはパフォーマンスの低下を最小限に抑えながら、すぐにbitsandbytes量子化の恩恵を受けることができます。量子化はモデルのロード時に実行されるため、後処理や準備ステップを実行する必要はありません。
2-2. クロスモダリティの相互運用性
モデルを量子化する唯一の条件は、torch.nn.Linearレイヤーを含むことであるため、量子化はどのようなモダリティでもすぐに機能し、Whisper、ViT、Blip2などのモデルを8bitまたは4bitですぐに読み込むことができます。
2-3. アダプターを結合する際のパフォーマンスの低下なし
量子化された基本モデル上でアダプターを学習する場合、推論パフォーマンスを低下させることなく、アダプターをデプロイメント用の基本モデル上にマージできます。 逆量子化されたモデルの上にアダプターをマージすることもできます。これは、GPTQではサポートされていません。
3. auto-gptq の利点
3-1. テキスト生成が高速
GPTQ量子化モデルは、bitsandbytes量子化モデルと比較してテキスト生成が高速です。
3-2. n-bit サポート
GPTQアルゴリズムにより、モデルを最大2bitまで量子化できます。ただし、これには重大な品質の低下が伴う可能性があります。推奨されるbit数は4ですが、現時点ではこれが GPTQ にとって大きなトレードオフであると思われます。
3-3. 簡単にシリアル化可能
GPTQモデルは、任意の数のbitのシリアル化をサポートします。TheBloke で公開されているGPTQモデルをそのまま利用できます。bitsandbytesは8bitシリアル化をサポートしていますが、現時点では4bitシリアル化をサポートしていません。
3-4. AMD サポート
AMD GPU も、そのままで機能する予定です。
4. bitsandbytes の欠点
4-1. テキスト生成ではGPTQよりも遅い
bitsandbytesの4bitモデルは、テキスト生成を使用するとGPTQに比べて遅くなります。
4-2. 4bitシリアル化ができない (現時点)
現在、4bitモデルはシリアル化できません。これはコミュニティから頻繁に寄せられるリクエストであり、bitsandbytesのロードマップに含まれています。
5. auto-gptq の欠点
5-1. キャリブレーションデータセットが必要
キャリブレーションデータセットの必要性により、一部のユーザーはGPTQを利用するのを思いとどまる可能性があります。さらに、モデルの量子化には数時間かかる場合があります。
5-2. 言語モデル以外では利用できない (現時点)
現在、「auto-gptq」を使用してモデルを量子化するAPIは、言語モデルのみをサポートしています。GPTQ アルゴリズムを使用して言語モデル以外も量子化できるはずですが、そのプロセスは元の論文や auto-gptqリポジトリでは詳しく説明されていません。
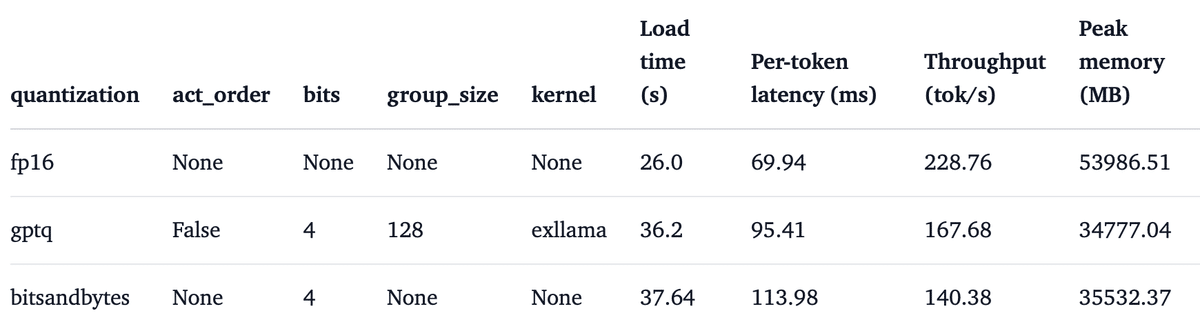
6. 速度ベンチマーク
6-1. 推論速度の比較
・プロンプト長 512
・A100
・metal-llama/Llama-2-13b-hf
・batch size = 1

・batch size = 16
6-2. テキスト生成速度の比較
・プロンプト長 30
・A100
・出力トークン数 30
・metal-llama/Llama-2-7b-hf
・use_cache=True

・use_cache=False

予想通り、アテンションキャッシュを使用すると生成が高速になりました。use_cache はより多くのメモリを消費することに注意が必要です。
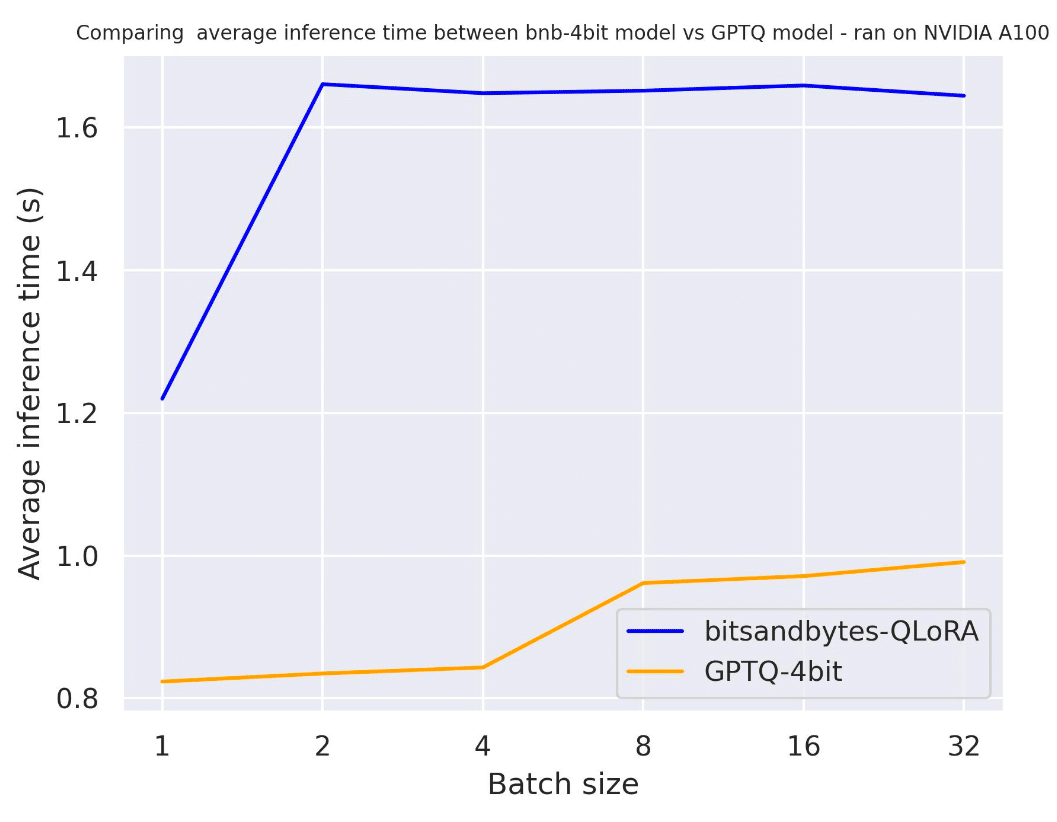
6-3. ハードウェア別のテキスト生成速度の比較
・プロンプトの長さ 30
・出力トークン数 30
・metal-llama/Llama-2-7b-hf
・NVIDIA A100
・NVIDIA T4
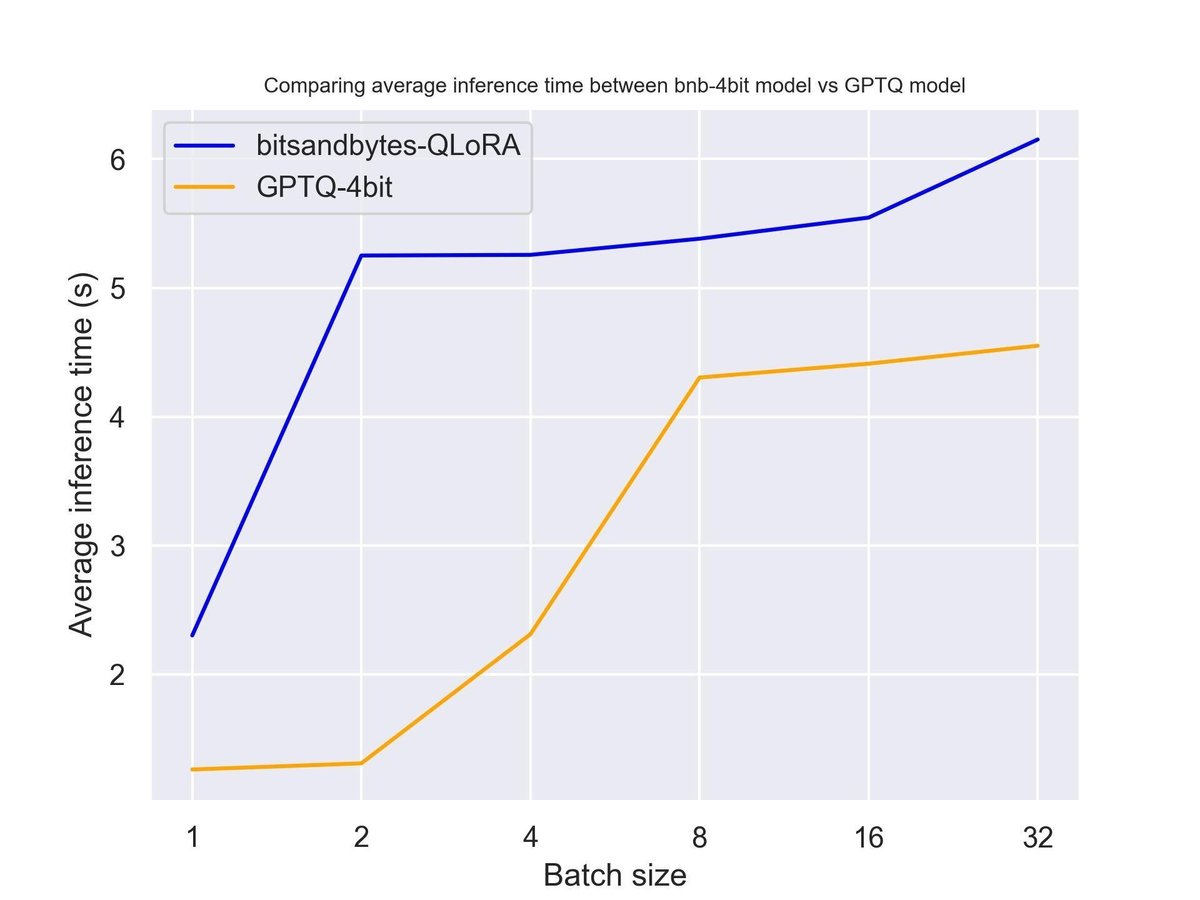
・Titan RTX

6-3. 出力トークン数別のテキスト生成速度の比較
・プロンプト長 30
・A100
・llama/Llama-2-7b-hf
・出力トークン数 30

・出力トークン数 512

6-4. アダプターのファインチューニング速度の比較
・NVIDIA A100
・metal-llama/Llama-2-7b-hf
GPTQ モデルの場合、exllama はファインチューニングでサポートされていないため、exllama カーネルを無効にする必要があります。
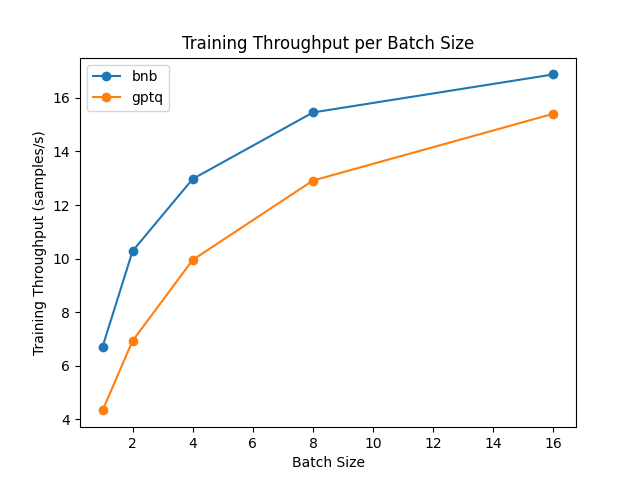
結果から、ファインチューニングに関しては「bitsandbytes」の方が「auto-gptq」よりも高速であることがわかります。
6-5. 量子化によるパフォーマンス低下の比較
量子化はメモリ消費量を削減するのに最適です。 ただし、パフォーマンスの低下が伴います。 Open-LLM リーダーボードを使用してパフォーマンスを比較してみます。
・7bモデル
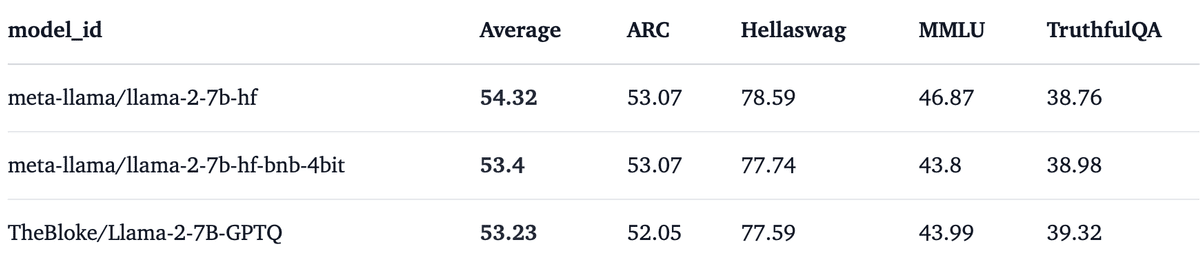
・13bモデル

より大きなモデルでは劣化が少ないとがわかります。