Stable Dreamfusion によるテキストからの3D生成を試す

「Stable Dreamfusion」によるテキストからの3D生成を試したので、まとめてみました。
1. DreamFusion
「DreamFusion」は、Google ResearchとUC Berkeleyの研究チームが発表した、テキストから3Dを生成する手法です。事前学習したtext-to-2Dの拡散モデルを使って、text-to-3Dを実現します。
2. Stable Dreamfusion
「Stable Dreamfusion」は、「DreamFusion」の論文を元に作られた、Stable Diffusionモデルを使った「DreamFusion」のPytorch実装です。
まだ多くの機能は実装中のため、元の論文の結果に匹敵するものではありませんが、テキストからの3Dオブジェクトの生成をいち早く体験できます。
(うまく生成できるプロンプトはまだ少ないみたい)
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) 以下のColabノートブックを開く。
(2) 「Check the machine」のセルを実行してGPUを確認。
T4で1エポック1分、V100で1エポック30秒、A100で1エポック16秒ほどでした。

(3) 「install dependencies」のセルを実行して、依存関係をインストール。
(4) 「login to huggingface to download stable diffusion」のセルを実行して、HuggingFaceにログイン。
リンク先のHuggingFaceのトークンをコピーして、テキストボックスに入力して、Loginボタンを押します。
(5) 「Training Settings:」のセルで各種設定を行い、セルを実行。
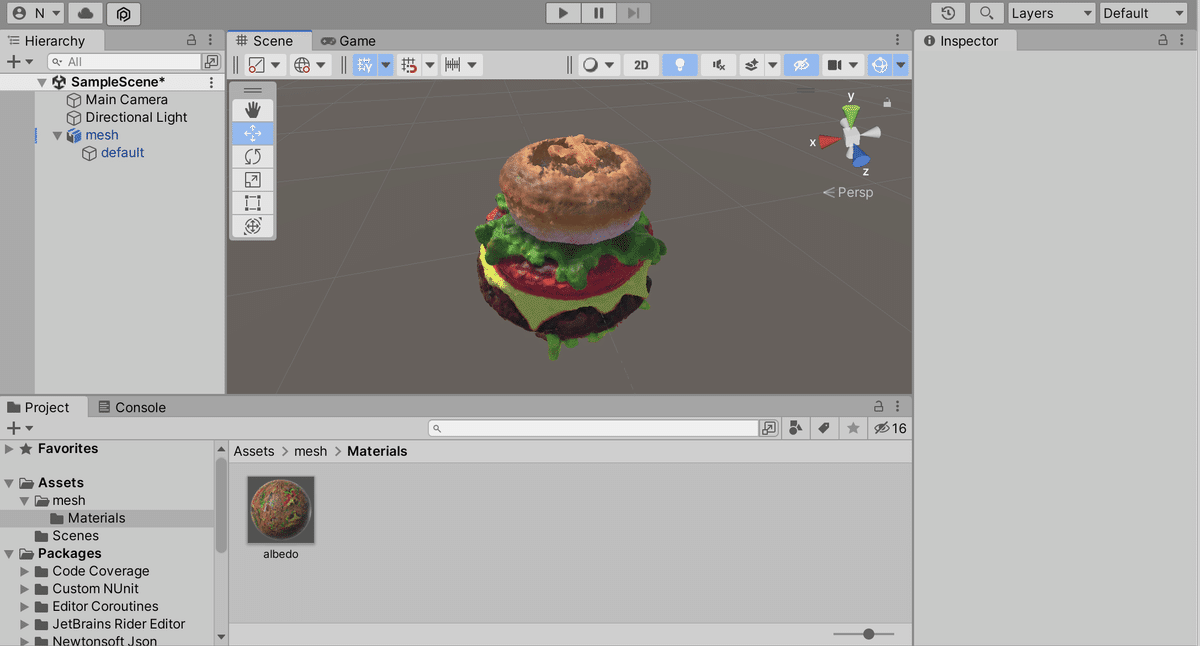
Prompt_textに「a hamburger」、Training_itersに15000 (結果早く知りたい人は5000でOK)を指定しました。

・Prompt_text : 生成する3Dオブジェクトを説明するテキスト
・Training_iters : 学習ステップ数
・Learning_rate : 学習率
・Training_nerf_resolution : NERF解像度
大きくするとレンダリング品質も向上しますが、GPUメモリが必要になる
・Seed : 乱数シード
・Lambda_entropy : Labmdaエントロピー
NeRF が何も学習できなかった (空になる) 場合 に減らすと良い
・Workspace : 出力先フォルダ名
学習終了時の処理には、動画とメッシュ出力が含まれています。学習中断時は、手動テストが必要になります。
(6) 「start training」のセルを実行して、学習開始。
V100で15000ステップ (150エポック) で1時間30分ほどかかりました。
(7) 左端のフォルダアイコンでファイル一覧を表示し、動画ファイルとメッシュファイルをダウンロード。
・stable-dreamfusion
・trial (出力フォルダ名)
・results (動画ファイル: mp4)
・mesh (メッシュファイル: obj / mtl/ png)

Stable-DreamFusionを試してみた。150エポック、2時間ほど。https://t.co/BMiI8wtczq pic.twitter.com/BiTAGLjfQs
— 布留川英一 / Hidekazu Furukawa (@npaka123) October 7, 2022
メッシュファイルは、Unityでも読み込めます。