
HuggingFace の Gemma 統合

以下の記事が面白かったので、簡単にまとめました。
1. Gemma
1-1. Gemma
「Gemma」は、「Gemini」をベースとしたGoogleの4つの新しいLLMモデルのファミリーです。2Bと7Bの2つのサイズがあり、それぞれにベースモデルと指示モデルがあります。すべてのバリアントは、量子化なしでもさまざまなタイプのコンシューマ ハードウェアで実行でき、コンテキスト長は8Kトークンです。
・google/gemma-7b : ベースモデル
・google/gemma-7b-it : 指示モデル
・google/gemma-2b : ベースモデル
・google/gemma-2b-it : 指示モデル

以下は、ベースモデルの概要と、LLM Leaderboard の他のオープンモデルと比較したパフォーマンスです (スコアが高いほど優れています)。
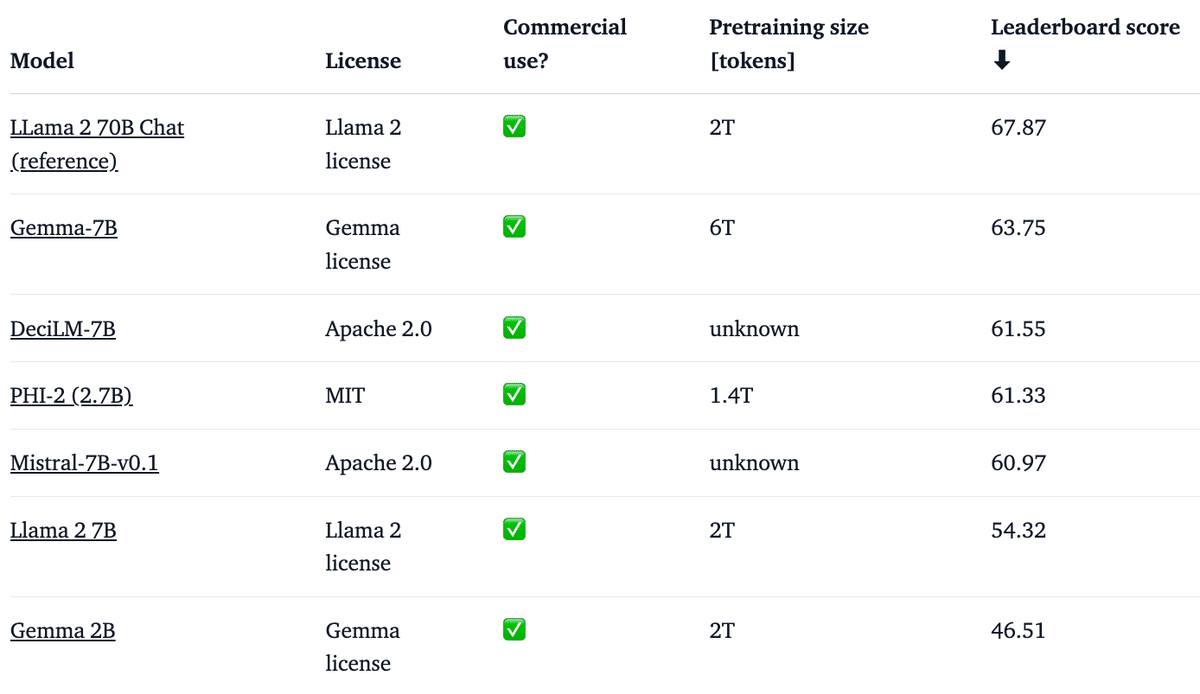
「Gemma 7B」は非常に強力なモデルであり、「Mistral 7B」を含む 7Bの最高のモデルに匹敵するパフォーマンスを備えています。「Gemma 2B」は、そのサイズの点で興味深いモデルですが、「Phi 2」などの同様のサイズの最高の機能を持つモデルほど高いスコアを獲得していません。
1-2. プロンプトフォーマット
ベースモデルにはプロンプト書式はありません。他のベースモデルと同様に、入力シーケンスを妥当な継続で継続したり、Zero-Shot / Few-Shot推論に使用したりできます。 また、独自のユースケースに合わせてファインチューニングするための優れたベースとしても機能します。
指示モデルの会話構造は非常に単純です。
<start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
LaMDA<end_of_turn>
<start_of_turn>model
LaMDA who?<end_of_turn>
1-3. 未知の世界の探索
技術レポートには、ベースモデルの学習と評価のプロセスに関する情報が含まれていますが、データセットの構成と前処理に関する広範な詳細はありません。さまざまなソース (主に Web ドキュメント、コード、数学的テキスト) からのデータを使用して学習されており、データはフィルタリングされ、CSAM コンテンツと PII、およびライセンス チェックが削除されました。
同様に、指示モデルについては、「SFT」および「RLHF」に関連するファインチューニングデータセットやハイパーパラメーターに関する詳細は共有されていません。
2. デモ
2-1. Hugging Chat
「Hugging Chat」で「Gemma」の指示モデルとチャットできます。
2-2. Transformers
Transformers v4.38 では、「Gemma」でHuggingFaceエコシステム内のすべてのツールを活用できます。
・学習および推論のスクリプトとサンプル
・safetensors
・bitsandbytes (4bit量子化)、PEFT、Flash Attendant 2 など
・モデルを使用して生成を実行するためのユーティリティとヘルパー
・デプロイするモデルをエクスポートするメカニズム
さらに、「Gemma」はCUDA グラフを使用した torch.compile() と互換性があり、推論時に最大4倍の速度向上が得られます。
必ず最新の Transformers を使用してください。
pip install -U "transformers==4.38.0" --upgrade次のコードは、Transformersで「gemma-7b-it」を使用する方法を示しています。 3090や4090などのコンシューマGPUを含む、約18GBのRAMが必要です。
from transformers import AutoTokenizer, pipeline
import torch
model = "google/gemma-7b-it"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(
prompt,
max_new_tokens=256,
add_special_tokens=True,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95
)
print(outputs[0]["generated_text"][len(prompt):])Avast me, me hearty. I am a pirate of the high seas, ready to pillage and plunder. Prepare for a tale of adventure and booty!
コードに関するいくつかの詳細は次のとおりです。
・bfloat16を使用したのは、それが参照精度であり、すべての評価の実行方法であるためです。 ハードウェアではfloat16で実行した方が高速になる可能性があります。
・トークン化された入力が <bos> トークンで始まらない限り、モデルは応答しません。 そのため、パイプライン呼び出しで add_special_tokens=True を使用しました。
モデルを自動的に量子化し、8bitモードまたは4bitモードでロードすることもできます。4bit読み込みの実行には約9GBのメモリが必要で、多くの一般向けカードや Google ColabのすべてのGPUと互換性があります。
pipeline = pipeline(
"text-generation",
model=model,
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True}
},
)詳しくは、モデルカードを参照してください。
2-3. JAXウェイト
すべての「Gemma」バリアントは、上で説明したように PyTorch または JAX / Flax で使用できます。Flax ウェイトをロードするには、以下に示すように、リポジトリからの Flax リビジョンを使用する必要があります。
import jax.numpy as jnp
from transformers import AutoTokenizer, FlaxGemmaForCausalLM
model_id = "google/gemma-2b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.padding_side = "left"
model, params = FlaxGemmaForCausalLM.from_pretrained(
model_id,
dtype=jnp.bfloat16,
revision="flax",
_do_init=False,
)
inputs = tokenizer("Valencia and Málaga are", return_tensors="np", padding=True)
output = model.generate(inputs, params=params, max_new_tokens=20, do_sample=False)
output_text = tokenizer.batch_decode(output.sequences, skip_special_tokens=True)['Valencia and Málaga are two of the most popular tourist destinations in Spain. Both cities boast a rich history, vibrant culture,']
TPU または複数の GPU デバイスで実行している場合は、jit と pmap を使用して推論を並行してコンパイルおよび実行できます。
3. Google Cloud との統合
「Vertex AI」または「Google Kubernetes Engine」 (GKE) を通じて、「Text Generation Inference」と「Transformers」を使用して、「Gemma」を 「Google Cloud」にデプロイして学習できます。
HuggingFace から「Gemma」をデプロイするには、model pageに移動し、Deploy → Google Cloud をクリックします。 これにより、「Google Cloud Console」が表示され、「Vertex AI」または「GKE」に「Gemma」を1クリックでデプロイできます。「Text Generation Inference」は「Google Cloud」上の 「Gemma」を強化しており、「Google Cloud」とのパートナーシップの一環としての最初の統合になります。
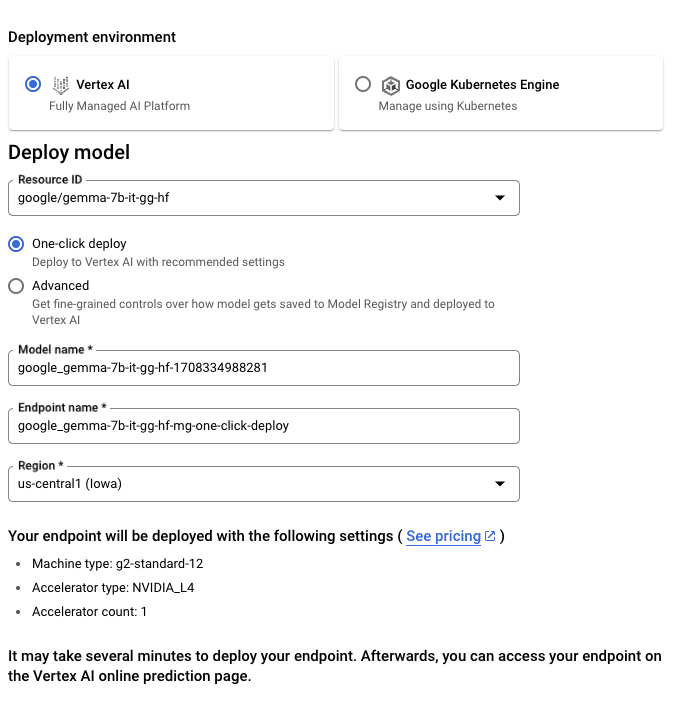
「Vertex AI Model Garden」を通じて「Gemma」に直接アクセスすることもできます。
HuggingFace から「Gemma」をチューニングするには、model pageに移動し、Train → Google Cloud をクリックします。これにより、「Google Cloud Console」が表示され、ノートブックにアクセスして「Vertex AI」または「GKE」で「Gemma」をチューニングできます。
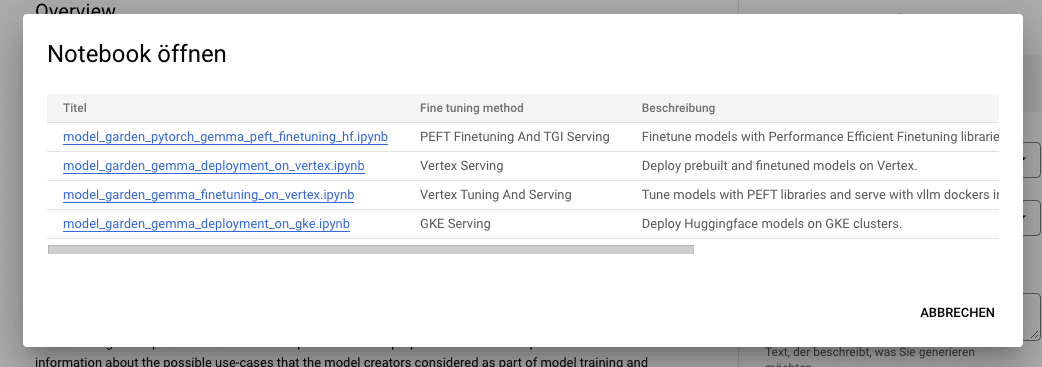
4. 推論エンドポイントとの統合
HuggingFace の「Text Generation Inference」に「Gemma」をデプロイできます。これは、HuggingFace によって開発された実稼働対応の推論コンテナであり、LLMの簡単なデプロイを可能にします。連続バッチ処理、トークンストリーミング、複数GPUでの高速推論のためのテンソル並列処理、本番環境に対応したロギングとトレースなどの機能を備えています。
「Gemma」をデプロイするには、model pageに移動し、Deploy → Inference Endpoints ウィジェットをクリックします。 推論エンドポイントは、テキスト生成推論を通じて Messages API もサポートします。詳しくは、過去の記事を参照してください。
5. TRL によるファインチューニング
OpenAssistantの チャットデータセット で「Gemma」をファインチューニングする例を以下に示します。4bit量子化とQLoRAを使用して、すべてのアテンション ブロックのlinear層をターゲットにします。
(1) TRLのnightlyバージョンをインストールし、リポジトリをクローン。
pip install -U transformers
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trl(2) 学習スクリプトを実行。
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \
examples/scripts/sft.py \
--model_name google/gemma-7b \
--dataset_name OpenAssistant/oasst_top1_2023-08-25 \
--batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--save_steps 20_000 \
--use_peft \
--peft_lora_r 16 --peft_lora_alpha 32 \
--target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit単一のA10Gでの学習には約 9 時間かかりますが、利用可能なGPU数に合わせて --num_processes を調整することで簡単に並列化できます。
6. 追加リソース
・Models on the Hub
・Leaderboard
・Chat demo on Hugging Chat
・Official Gemma Blog
・Gemma Product Page
・Vertex AI model garden link
・Google Notebook