
Llama 3.2 の使い方

以下の記事が面白かったので、簡単にまとめました。
・Llama can now see and run on your device - welcome Llama 3.2
1. Llama 3.2 Vision 11B・90B
1-1. Llama 3.2 Vision 11B・90B
「Llama 3.2 Vision 11B・90B」は、Metaがリリースした最も強力なオープンマルチモーダルモデルです。画像+テキストのプロンプトでは英語のみ、テキストのみのプロンプトでは英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語をサポートしています。
コンテキスト長は128kトークンで、画像を含む可能性のある複数ターンの会話が可能です。ただし、モデルは単一の画像に注目する場合に最適に機能するため、transformers実装では入力で提供された最後の画像のみに注目します。これにより品質が維持され、メモリが節約されます。
モデルは多様なデータが混在する60億の画像とテキストのペアの大規模なデータセットで学習しました。そのため、下流のタスクのファインチューニングに最適です。
1-2. ベンチマーク
ベンチマーク結果は次のとおりです。
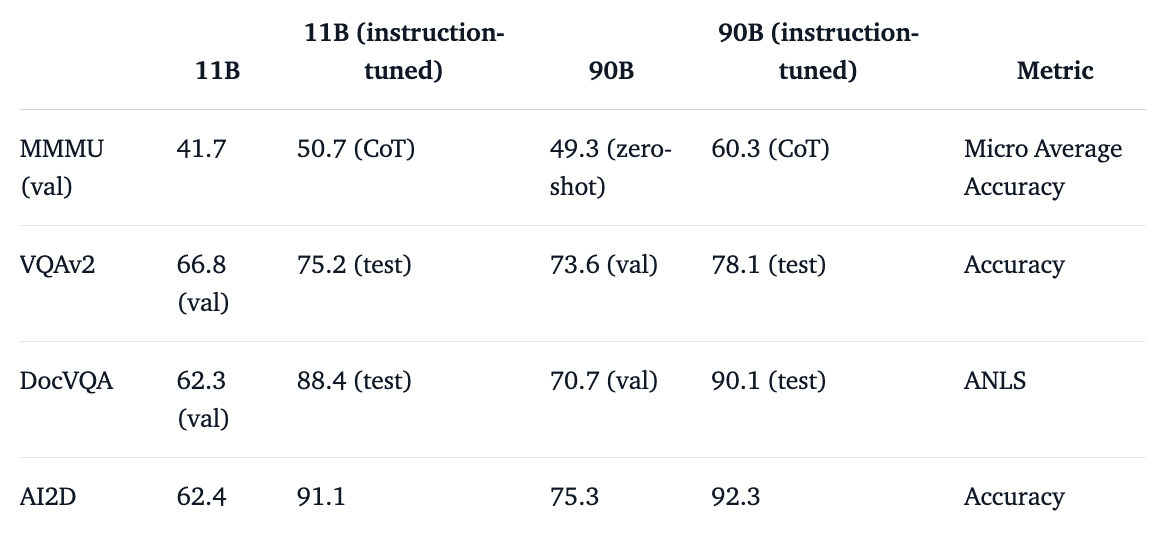
テキストの能力は、Visionモデルの学習中にTextモデルが固定されたと理解しているため、「Llama 3.1」と同等になると予想されます。
1-3. ライセンス
ライセンスに関しては、「Llama 3.2」には「Llama 3.1」と非常によく似たライセンスが付属していますが、許容される使用ポリシーに1つの重要な違いがあります。それは、欧州連合に居住する個人、または欧州連合に主たる事業所がある企業には、「Llama 3.2」に含まれるマルチモーダル モデルを使用するライセンス権が付与されないことです。この制限は、このようなマルチモーダルモデルを組み込んだ製品またはサービスのエンドユーザーには適用されないため、Visionバリアントを使用してグローバルな製品を構築することは可能です。
詳細については、公式ライセンスと利用規約を参照してください。
2. Llama 3.2 1B・3B
2-1. Llama 3.2 1B・3B
「Llama 3.2 1B・3B」は、プロンプトの書き換え、多言語の知識検索、要約タスク、ツールの使用、ローカルで実行するアシスタントなど、デバイス上のユースケース向けに調整されてるモデルです。
「Llama 3.1」と同じアーキテクチャで、最大9兆のトークンで学習され、128kトークンの長いコンテキスト長もサポートしています。モデルは多言語で、英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語をサポートしています。
2-2. Llama Guard 3 1B
「Llama Guard」の新しい小型バージョンである「Llama Guard 3 1B」もリリースされており、複数ターンの会話における最後のユーザーまたはアシスタントの応答を評価できます。詳しくは、モデルカードを参照してください。
2-3. ベンチマーク
ベンチマーク結果は次のとおりです。
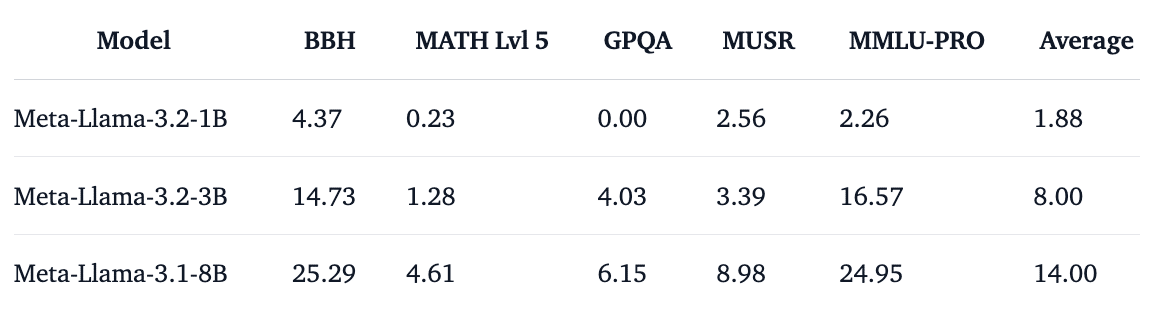

「3B」は「IFEval」で「8B」と同じくらい強力です。これにより、モデルは信頼性の向上に指示に従うことが非常に重要なエージェントアプリケーションに最適です。このサイズのモデルとして、この高い「IFEval」スコアは非常に印象的です。
ツールの使用は、「1B」「3B」指示調整モデルの両方でサポートされています。ツールは、Zero-Shotでユーザーによって指定されます。したがって、「Llama 3.1」の一部であった組み込みツール (brave_searchおよびwolfram_alpha) は使用できなくなりました。
2-4. 投機的デコード
これらの小さなモデルはサイズが小さいため、より大きなモデルのアシスタントとして使用し、「投機的デコード」を実行できます。
3. デモ
以下のデモで3つのモデルを試すことができます。
・Gradio Space with Llama 3.2 11B Vision Instruct
・Gradio-powered Space with Llama 3.2 3B
・Llama 3.2 3B running on WebGPU
・WebGPU Llama 3.2 3B powered by MLC Web-LLM
4. Transformers での使用
4-1. Transformers での使用
「Llama 3.2 Vision」では「Transformers」を更新する必要があります。v4.45.0 以降にアップグレードしてください。Textモデルは前のリリースと同じアーキテクチャであるため、更新する必要はありません。
pip install "transformers>=4.45.0" --upgrade4-2. Llama 3.2 Vision
Visionモデルはサイズが大きいため、小さなTextモデルよりも実行に多くのメモリが必要です。「11B」は、4bitで推論中に約10GBのGPU RAMを使用します。
指示調整されたVisionモデルで推論する最も簡単な方法は、組み込みのチャットテンプレートを使用することです。入力には、会話のターンを示すuserロールとassistantロールがあります。Textモデルとの1つの違いは、systemロールがサポートされていないことです。userターンには、画像+テキスト、またはテキストのみの入力を含めることができます。入力に画像が含まれていることを示すには、入力のコンテンツ部分に {"type": "image"} を追加し、画像データをプロセッサに渡します。
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device="cuda",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]}
]
input_text = processor.apply_chat_template(
messages, add_generation_prompt=True,
)
inputs = processor(
image, input_text, return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].shape[-1]:]))
## The image depicts a rabbit dressed in a blue coat and brown vest, standing on a dirt road in front of a stone house.画像に関する会話を続けることができます。ただし、新しいuserターンで新しい画像を提供すると、モデルはその瞬間から新しい画像を参照することに注意してください。2つの異なる画像を同時にクエリすることはできません。これは、前の会話の続きの例で、assistantターンを会話に追加して、さらに詳細を尋ねています。
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]},
{"role": "assistant", "content": "The image depicts a rabbit dressed in a blue coat and brown vest, standing on a dirt road in front of a stone house."},
{"role": "user", "content": "What is in the background?"}
]
input_text = processor.apply_chat_template(
messages,
add_generation_prompt=True,
)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].shape[-1]:]))In the background, there is a stone house with a thatched roof, a dirt road, a field of flowers, and rolling hills.
また、モデルを自動的に量子化し、bitsandbytes を使用して8bitまたは4bitで読み込むこともできます。生成パイプラインを4bitで読み込む方法は、次のとおりです。
import torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
+from transformers import BitsAndBytesConfig
+bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.bfloat16
)
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
- torch_dtype=torch.bfloat16,
- device="cuda",
+ quantization_config=bnb_config,
)その後、チャットテンプレートを適用し、プロセッサを使用して、以前と同じようにモデルを呼び出すことができます。
4-3. Llama 3.2 1B・3B
「Transformers」を使用すると、わずか数行で「Llama 3.2 1B・3B」を実行できます。

from transformers import pipeline
import torch
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
response = outputs[0]["generated_text"][-1]["content"]
print(response)
# Arrrr, me hearty! Yer lookin' fer a bit o' information about meself, eh? Alright then, matey! I be a language-generatin' swashbuckler, a digital buccaneer with a penchant fer spinnin' words into gold doubloons o' knowledge! Me name be... (dramatic pause)...Assistant! Aye, that be me name, and I be here to help ye navigate the seven seas o' questions and find the hidden treasure o' answers! So hoist the sails and set course fer adventure, me hearty! What be yer first question?モデルを bfloat16 でロードします。これは Meta公式のチェックポイントで使用されている型であるため、推奨されます。ハードウェアによっては、float16 の方が高速になる場合があります。
デフォルトでは、Transformersは元のMetaコードベースと同じサンプリングパラメータ (temperature=0.6 および top_p=0.9) を使用します。
5. オンデバイス
オープンソースライブラリを使用して、「Llama 3.2 1B・3B」をオンデバイスのCPU・GPU・ブラウザ上で直接実行できます。
5-1. Llama.cpp
「Llama.cpp」は、クロスプラットフォームのデバイス内ML推論のすべてに対応するフレームワークです。このコレクションでは、1B・3Bの両方に量子化された4bit・8bitのウェイトを提供します。量子化された「Llama 3.2」は、こちらで参照できます。
使用手順は、次のとおりです。
(1) brewでllama.cpp をインストール (Mac および Linux で動作)
brew install llama.cppCLI を使用して単一の生成を実行したり、Open AIメッセージ仕様と互換性のあるllama.cppサーバーを起動したりできます。
(2) CLIの実行
llama-cli --hf-repo hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -p "The meaning to life and the universe is"5-2. llama-cpp-python
「llama-cpp-python」で、Python経由でモデルにアクセスすることもできます。
(1) パッケージのインストール。
pip install llama-cpp-python(2) 推論の実行。
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF",
filename="*q8_0.gguf",
)
output = llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "What is the capital of France?"
}
]
)
print(output)5-3. Transformers.js
「Transformers.js」を使用すると、ブラウザ (または Node.js、Deno、Bun など) で「Llama 3.2」を実行することもできます。ONNXはHubで見つかります。まだインストールしていない場合は、次の方法でNPMからライブラリをインストールできます。
(1) パッケージのインストール。
npm i @huggingface/transformers(2) モデルの実行。
import { pipeline } from "@huggingface/transformers";
const generator = await pipeline("text-generation", "onnx-community/Llama-3.2-1B-Instruct");
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Tell me a joke." },
];
const output = await generator(messages, { max_new_tokens: 128 });
console.log(output[0].generated_text.at(-1).content);Here's a joke for you:
What do you call a fake noodle?
An impasta!
I hope that made you laugh! Do you want to hear another one?
5-4. MLC.ai Web-LLM
「MLC.ai Web-LLM」は、ハードウェアアクセラレーションを使用してWebブラウザにLLM推論を直接提供する、高性能なブラウザ内LLM推論エンジンです。サーバのサポートなしでブラウザ内で実行され、WebGPUで高速化されます。
「WebLLM」は「OpenAI API」と完全に互換性があります。つまり、ストリーミング、JSONモード、Function Callingなどの機能を使用して、ローカルの任意のオープンソースモデルで使用できます。
(1) パッケージのインストール。
npm install @mlc-ai/web-llm(2) モデルの実行。
import * as webllm from "@mlc-ai/web-llm";
import { CreateMLCEngine } from "@mlc-ai/web-llm";
const initProgressCallback = (initProgress) => {
console.log(initProgress);
}
const selectedModel = "Llama-3.2-3B-Instruct-q4f32_1-MLC";
const engine = await CreateMLCEngine(
selectedModel,
{ initProgressCallback: initProgressCallback }, // engineConfig
);エンジンの初期化が正常に完了すると、engine.chat.completionsインターフェースを介して OpenAIスタイルの Chat API を使用して Chat Completion を呼び出すことができるようになります。
const messages = [
{ role: "system", content: "You are a helpful AI assistant." },
{ role: "user", content: "Explain the meaning of life as a pirate!" },
]
const reply = await engine.chat.completions.create({
messages,
});
console.log(reply.choices[0].message);
console.log(reply.usage);5. Llama 3.2 のファインチューニング
5-1. TRLによるファインチューニング
「TRL」は、「Llama 3.2」のTextモデルのファインチューニングをサポートします。
# Chat
trl chat --model_name_or_path meta-llama/Llama-3.2-3B
# Fine-tune
trl sft --model_name_or_path meta-llama/Llama-3.2-3B \
--dataset_name HuggingFaceH4/no_robots \
--output_dir Llama-3.2-3B-Instruct-sft \
--gradient_checkpointingこのスクリプトを使用すると、「TRL」で「Llama 3.2 Vision」をファインチューニングするためのサポートも利用できます。
5-2. PEFTによるLoRAファインチューニング
「PEFT」を使用したLoRAファインチューニングについては、このノートブックを参照してください。
# Tested on 8x H100 GPUs
accelerate launch --config_file=examples/accelerate_configs/deepspeed_zero3.yaml \
examples/scripts/sft_vlm.py \
--dataset_name HuggingFaceH4/llava-instruct-mix-vsft \
--model_name_or_path meta-llama/Llama-3.2-11B-Vision-Instruct \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 8 \
--output_dir Llama-3.2-11B-Vision-Instruct-sft \
--bf16 \
--torch_dtype bfloat16 \
--gradient_checkpointing6. HuggingFace パートナー統合
現在、「AWS」「Google Cloud」「Microsoft Azure」「DELL」のパートナーと協力して、「Llama 3.2 11B・90B」を「Amazon SageMaker」「Google Kubernetes Engine」「Vertex AI Model Catalog」「Azure AI Studio」「DELL Enterprise Hub」に追加しています。コンテナが利用可能になり次第、このセクションを更新します。また、「Hugging Squad」に登録して、電子メールによる更新情報を受け取ることもできます。
関連
・Models on the Hub
・Hugging Face Llama Recipes
・Open LLM Leaderboard
・Meta Blog
・Evaluation datasets