
TRL - 強化学習によるLLMの学習のためのライブラリ

「TRL」のドキュメントを簡単にまとめました。
・trl v0.4.2
1. TRL
「TRL」(Transformer Reinforcement Learning) は、強化学習を使用してTransformer言語モデルを学習できます。このライブラリはHuggingFace Transformersと統合されています。
「TRL」は、「GPT-2」「BLOOM」「GPT-Neo」などのデコーダモデルをサポートしており、これらすべて「PPO」を使用して最適化できます。
2. クイックスタート
2-1. 処理の流れ
「PPO」による言語モデルのファインチューニングは、3つのステップで構成されます。
・ロールアウト : 言語モデルは、文の始まりとなるクエリをもとに、応答または継続を生成します。
・評価 : クエリと応答は、関数、モデル、人間によるフィードバック、またはそれらの組み合わせによって評価されます。重要なことは、このプロセスでは各クエリ/応答 ペアのスカラー値が生成されることです。最適化は、この値を最大化することを目的とします。
・最適化 : 最も複雑な部分です。最適化ステップでは、クエリ/応答 ペアを使用して、シーケンス内のトークンの log-probabilities を計算します。これは、学習モデルと参照モデル (通常はファインチューニング前の事前学習モデル) を使用して行われます。2つの出力間の KL-divergence は、生成された応答が参照言語モデルから大きく逸脱しないようにするための追加の報酬信号として使用されます。 次に、アクティブな言語モデルが PPO で学習されます。
完全な処理の流れは、次図のとおりです。

2-2. 最小限のコード
上記手順を示す最小限のコード例は、次のとおりです。
# 0. インポート
import torch
from transformers import GPT2Tokenizer
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
# 1. 事前学習モデルの読み込み
model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
# 2. トレーナーの初期化
ppo_config = {"batch_size": 1}
config = PPOConfig(**ppo_config)
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer)
# 3. クエリのエンコード
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt").to(model.pretrained_model.device)
# 4. モデル応答の生成
generation_kwargs = {
"min_length": -1,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True,
"pad_token_id": tokenizer.eos_token_id,
"max_new_tokens": 20,
}
response_tensor = ppo_trainer.generate([item for item in query_tensor], return_prompt=False, **generation_kwargs)
response_txt = tokenizer.decode(response_tensor[0])
# 5. 応答に対する報酬の定義
reward = [torch.tensor(1.0, device=model.pretrained_model.device)]
# 6. PPOでモデルを学習
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)一般に、ステップ 3 ~ 6 を for ループで実行します。
2-3. 学習済みモデルの使用方法
「AutoModelForCausalLMWithValueHead」を学習後、transformersでモデルを直接使用できます。
# .. PPOTrainer と AutoModelForCausalLMWithValueHead を使用して学習したモデルがあると仮定
# モデルをHubにPush
model.push_to_hub("my-fine-tuned-model-ppo")
# またはローカルに保存
model.save_pretrained("my-fine-tuned-model-ppo")
# Hubからモデルを読み込む
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("my-fine-tuned-model-ppo")学習を継続する場合など、value headを使用したい場合は、AutoModelForCausalLMWithValueHeadを使用してモデルを読み込むこともできます。
from trl.model import AutoModelForCausalLMWithValueHead
model = AutoModelForCausalLMWithValueHead.from_pretrained("my-fine-tuned-model-ppo")3. インストール
「TRL」は pipまたはソースからインストールできます。
◎ pip
pip install trl◎ ソース
git clone https://github.com/lvwerra/trl.git
cd trl/
pip install -e .4. 学習のカスタマイズ
「TRL」では、ユーザーがニーズに合わせて学習ループを効率的にカスタマイズできるよう、十分なモジュール性を提供します。 以下に、さまざまなテクニックを適用して、テストする方法の例を紹介します。
4.1 複数のGPU/ノードでの実行
accelerateンを利用して、ユーザーが複数の GPU またはノードで学習できるようにします。次のコマンドで accelerate config を作成する必要があります。
accelerate config次に、マルチGPU / マルチードが選択されていることを確認してください。 その後、以下を実行するだけで学習できます。
accelerate launch your_script.py詳細については、examples page を参照。
4-2. さまざまなオプティマイザーの使用
デフォルトでは、「PPOTrainer」は「torch.optim.Adam」オプティマイザを作成します。 別のオプティマイザを作成して定義し、それを「PPOTrainer」に指定することもできます。
import torch
from transformers import GPT2Tokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
# 1. 事前学習モデルの読み込み
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 2. コンフィグの定義
ppo_config = {'batch_size': 1, 'learning_rate':1e-5}
config = PPOConfig(**ppo_config)
# 2. オプティマイザの作成
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
# 3. トレーナーの初期化
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer, optimizer=optimizer)メモリ効率をファインチューニングするために、bitsandbytes から Adam8bit オプティマイザを指定することもできます。
import torch
import bitsandbytes as bnb
from transformers import GPT2Tokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
# 1. 事前学習モデルの読み込み
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 2. コンフィグの定義
ppo_config = {'batch_size': 1, 'learning_rate':1e-5}
config = PPOConfig(**ppo_config)
# 2. オプティマイザの作成
optimizer = bnb.optim.Adam8bit(model.parameters(), lr=config.learning_rate)
# 3. トレーナーの初期化
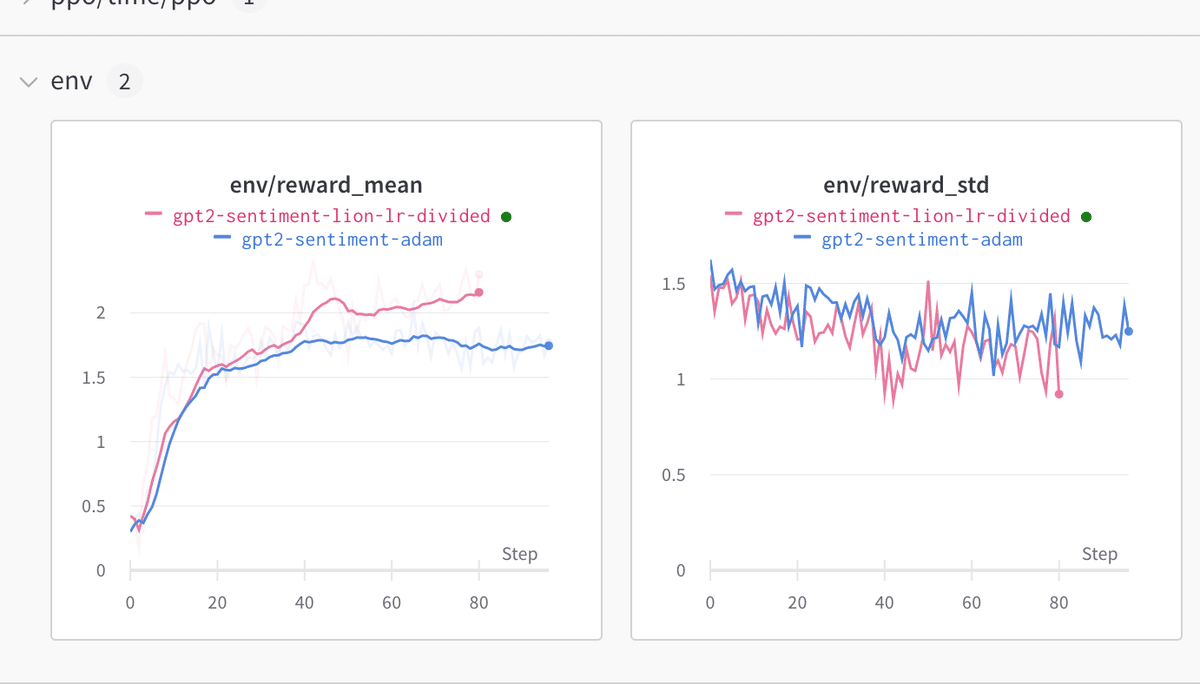
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer, optimizer=optimizer)4-3. LION オプティマイザの使用
Google の新しい LION オプティマイザも使用できます。オプティマイザ定義のソース コードを取得し、オプティマイザをインポートできるようにコピーします。よりメモリ効率の高い学習を行うためにのみ、学習可能なパラメーターを考慮してオプティマイザを初期化してください。
optimizer = Lion(filter(lambda p: p.requires_grad, self.model.parameters()), lr=self.config.learning_rate)
...
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer, optimizer=optimizer)ここで指摘されているように、Adam に使用する学習率を 3 で割った値を使用することをお勧めします。このオプティマイザを使用すると、従来の Adam と比較して改善が見られました。
4-4. 学習率スケジューラの追加
学習率スケジューラを追加して、学習を試すこともできます。
import torch
from transformers import GPT2Tokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
# 1. 事前学習モデルの読み込み
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 2. コンフィグの定義
ppo_config = {'batch_size': 1, 'learning_rate':1e-5}
config = PPOConfig(**ppo_config)
# 2. オプティマイザの作成
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
# 3. トレーナーの初期化
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer, optimizer=optimizer, lr_scheduler=lr_scheduler)4-5. レイヤーの共有によるメモリ効率の高いファインチューニング
よりメモリ効率の高いファインチューニングに使用できるもう 1 つのツールは、参照モデルと学習モデルの間でレイヤーを共有することです。
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
# 1. 事前学習モデルの読み込み
model = AutoModelForCausalLMWithValueHead.from_pretrained('bigscience/bloom-560m')
model_ref = create_reference_model(model, num_shared_layers=6)
tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
# 2. トレーナーの初期化
ppo_config = {'batch_size': 1}
config = PPOConfig(**ppo_config)
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer)4-6. 8-bit参照モデルの指定
「TRL」は、from_pretrained を使用してtransformersからモデルを読み込む時、すべてのパラメータをサポートするため、load_in_8bit を指定して、よりメモリ効率の高いファインチューニングを行うこともできます。
8-bitモデルの読み込みについて詳しくは、こちらを参照。
# 0. インポート
# pip install bitsandbytes
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
# 1. 事前学習モデルの読み込み
model = AutoModelForCausalLMWithValueHead.from_pretrained('bigscience/bloom-560m')
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained('bigscience/bloom-560m', device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
# 2. トレーナーの初期化
ppo_config = {'batch_size': 1}
config = PPOConfig(**ppo_config)
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer)4-7. CUDA キャッシュ オプティマイザの使用
大規模なモデルを学習する場合は、CUDAキャッシュを繰り返しクリアして、より適切に処理する必要があります。PPOConfigでoptimize_cuda_cache=True を指定します。
config = PPOConfig(..., optimize_cuda_cache=True)4-8. DeepSpeed stage 3 を正しく使用
DeepSpeed stage 3 を正しく使用するには、学習スクリプトに小さな調整を追加する必要があります。 zero3_init_context_manager コンテキスト マネージャを使用して、正しいデバイスで報酬モデルを適切に初期化する必要があります。 gpt2-sentiment スクリプトに適応した例を、次に示します。
ds_plugin = ppo_trainer.accelerator.state.deepspeed_plugin
if ds_plugin is not None and ds_plugin.is_zero3_init_enabled():
with ds_plugin.zero3_init_context_manager(enable=False):
sentiment_pipe = pipeline("sentiment-analysis", model="lvwerra/distilbert-imdb", device=device)
else:
sentiment_pipe = pipeline("sentiment-analysis", model="lvwerra/distilbert-imdb", device=device)4-9. torch distributed の使用
torch.distributed パッケージは、ネットワークを複数のマシンに分散するための PyTorch ネイティブメソッドを提供します (複数のGPUノードがある場合に最も役立ちます)。 各GPUでモデルをコピーし、それぞれで順方向と逆方向を実行し、すべてのGPUの勾配の平均をそれぞれに適用します。
torch 1.XXの場合、次のように torch.distributed.launch を呼び出すことができます。
python -m torch.distributed.launch --nproc_per_node=1 reward_summarization.py --bf16torch 2.+ では torch.distributed.launch は非推奨となり、次の呼び出しが必要です。
torchrun --nproc_per_node=1 reward_summarization.py --bf16
# または
python -m torch.distributed.run --nproc_per_node=1 reward_summarization.py --bf16torch 2.0で python -m torch.distributed.launch --nproc_per_node=1 reward_summarization.py -bf16 を使うと、次のようになります。
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--local-rank=0']
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 194889) of binary: /home/ubuntu/miniconda3/envs/trl/bin/python5. ロギング
5-1. ロギング
強化学習アルゴリズムは歴史的にデバッグが難しいため、ロギングに細心の注意を払うことが重要です。デフォルトでは、TRL PPOTrainer は多くの関連情報を wandb または tensorboard に保存します。
初期化時に、次の2つのオプションのいずれかを PPOConfig に渡します。
config = PPOConfig(
model_name=args.model_name,
log_with=`wandb`, # or `tensorboard`
)tensorboard を使用してログを記録する場合は、kwargaccelerator_kwargs={"logging_dir": PATH_TO_LOGS} を PPOConfig に追加します。
5-2. 重要なパラメータ
学習中、多くのパラメータが記録されますが、ここでは最も重要なものを紹介します。
・env/reward_mean, env/reward_std, env/reward_dist : 「環境」からの報酬分布の特性。
・ppo/mean_scores : 報酬モデルから直接出力される平均点。
・ppo/mean_non_score_reward : 学習中のKLペナルティの平均値 (ステップのバッチで参照モデルと新しいポリシーの間のdeltaを示す)
5-3. 学習の安定性パラメータ
安定性を監視するのに役立ついくつかのパラメータを次に示します。これらのパラメータが発散するか0に崩壊する場合は、変数を調整してみてください。
・ppo/loss/value : 価値関数 loss。うまくいかない場合はspike / NaN になります。
・ppo/val/clipfrac : 値関数損失におけるクリップされた値の割合。 多くの場合、これは 0.3 ~ 0.6 です。
・object/kl_coef : AdaptiveKLController でのターゲット係数。 多くの場合、数値が不安定になる前に増加します。