Google Colab で CogVideoX の Image-to-Video と Video-to-Video を試す

「Google Colab」で「CogVideoX」の Image-to-Video と Video-to-Video を試したのでまとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. CogVideoX
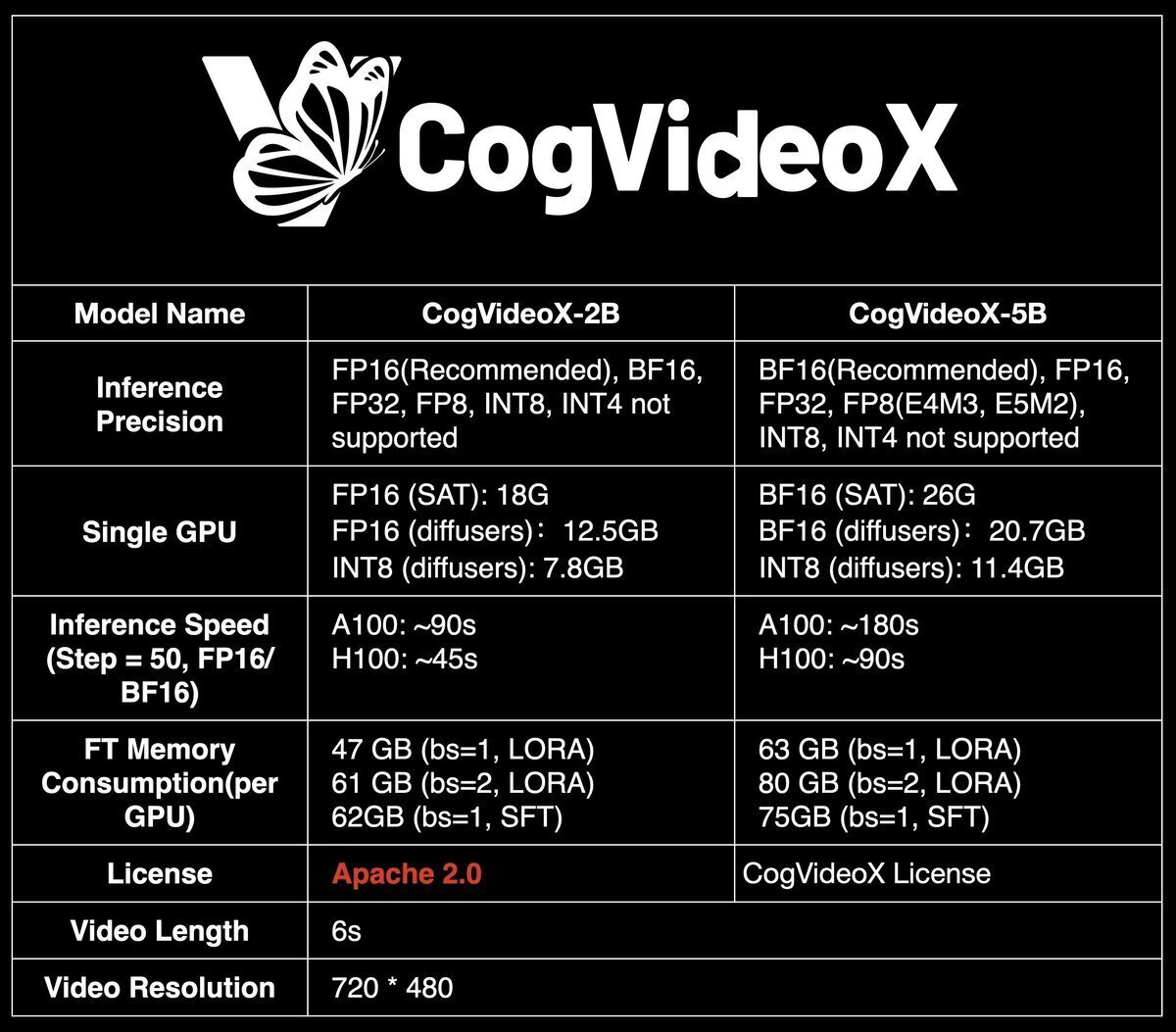
「CogVideoX」は、「Zhipu AI」が開発した動画生成AIです。「CogVideoX-2B」と「CogVideoX-5B」の2つのモデルが提供されています。
・THUDM/CogVideoX-2b
・THUDM/CogVideoX-5b
・THUDM/CogVideoX-5b-I2V
1. Image-to-Video
Google ColabでのImage-to-Videoの手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install git+https://github.com/huggingface/diffusers(2) パイプラインの準備。
import torch
from diffusers import CogVideoXImageToVideoPipeline
# パイプラインの準備
pipe = CogVideoXImageToVideoPipeline.from_pretrained(
"THUDM/CogVideoX-5b-I2V",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()(3) プロンプトと画像の準備と推論の実行。
from diffusers.utils import export_to_video, load_image
# プロンプトと画像の準備
prompt = "An astronaut hatching from an egg, on the surface of the moon, the darkness and depth of space realised in the background. High quality, ultrarealistic detail and breath-taking movie-like camera shot."
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg"
)
# 推論の実行
video = pipe(image, prompt, use_dynamic_cfg=True)
export_to_video(video.frames[0], "output.mp4", fps=8)【翻訳】
月の表面で卵から孵化する宇宙飛行士。背景には宇宙の暗さと深さが表現されています。高品質で超リアルなディテールと息を呑むような映画のようなカメラショット。
Google Colab で diffusers の CogVideoX-I2Vをお試し中。
— 布留川英一 / Hidekazu Furukawa (@npaka123) September 20, 2024
・Time: 03:40
・GPU RAM: 18GBhttps://t.co/G9mCy4Qf0C pic.twitter.com/FqDE9Gfou3

2. Video-to-Video
Google ColabでのVideo-to-Videoの手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install git+https://github.com/huggingface/diffusers(2) パイプラインの準備。
import torch
from diffusers import CogVideoXDPMScheduler, CogVideoXVideoToVideoPipeline
# パイプラインの準備
pipe = CogVideoXVideoToVideoPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
torch_dtype=torch.bfloat16
)
pipe.scheduler = CogVideoXDPMScheduler.from_config(pipe.scheduler.config)
pipe.to("cuda")(3) プロンプトと画像の準備と推論の実行。
from diffusers.utils import export_to_video, load_video
# プロンプトと画像の準備
prompt = (
"An astronaut stands triumphantly at the peak of a towering mountain. Panorama of rugged peaks and "
"valleys. Very futuristic vibe and animated aesthetic. Highlights of purple and golden colors in "
"the scene. The sky is looks like an animated/cartoonish dream of galaxies, nebulae, stars, planets, "
"moons, but the remainder of the scene is mostly realistic."
)
input_video = load_video(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/hiker.mp4"
)
# 推論の実行
video = pipe(
video=input_video,
prompt=prompt,
strength=0.8,
guidance_scale=6,
num_inference_steps=50
).frames[0]
export_to_video(video, "output.mp4", fps=8)【翻訳】
宇宙飛行士がそびえ立つ山の頂上に意気揚々と立っています。険しい山頂と谷のパノラマ。非常に未来的な雰囲気とアニメーションの美学。シーンでは紫と金色がハイライトになっています。空は銀河、星雲、星、惑星、月などのアニメーション/漫画風の夢のように見えますが、シーンの残りの部分はほぼ現実的です。
Google Colab で diffusers の CogVideoX-V2V をお試し中。
— 布留川英一 / Hidekazu Furukawa (@npaka123) September 20, 2024
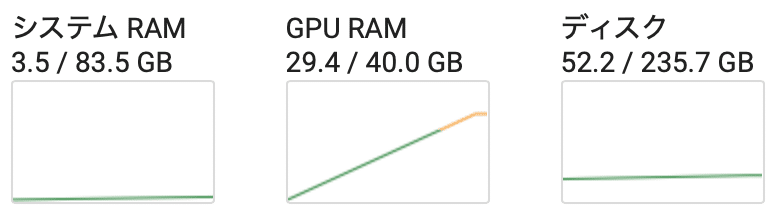
・Time: 2:46
・GPU RAM: 29.4GBhttps://t.co/G9mCy4Qf0C pic.twitter.com/deDQmEfiFp