
Google Colab で FLUX.1 を試す

「Google Colab」で「FLUX.1」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. FLUX.1
「FLUX.1」は、「Stable Diffusion」の開発者たちが立ち上げた「Black Forest Labs」が発表した最新の画像生成AIモデルです。
・FLUX.1 [pro] : APIから利用可能な最高品質のモデル。
・FLUX.1 [dev] : 非商用アプリ向けのオープンなガイダンス蒸留モデル。
・FLUX.1 [schnell] : 最速のタイムステップ蒸留モデル。
2. FLUX.1 [dev]
「Google Colab」でのFLUX.1 [dev] (ガイダンス蒸留モデル) の実行手順は、次のとおりです。
・ガイダンス蒸留モデルでは、高品質の生成に約50ステップが必要
・max_sequence_length に関する制限はない
(1) パッケージのインストール。
# パッケージのインストール
!pip install git+https://github.com/huggingface/diffusers.git(2) モデルカードで「Agree and access repository」をクリック。

(3) HuggingFaceのログイン。
!huggingface-cli login指示に従って次の情報を入力します。
・Enter your token (input will not be visible) : HuggingFaceのトークン
・Add token as git credential? (Y/n) : n (認証情報として保存するか)
(4) パイプラインの準備。
「black-forest-labs/FLUX.1-dev」をダウンロードします。
import torch
from diffusers import FluxPipeline
# パイプラインの準備
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload()(5) プロンプトの準備と画像生成の実行。
# プロンプトの準備
prompt = "cute cat ear maid of japanese anime style"
# 画像生成の実行
out = pipe(
prompt=prompt,
guidance_scale=3.5,
width=1024,
height=1024,
num_inference_steps=50,
max_sequence_length=256,
).images[0]
out.save("image.png")
50ステップで56秒かかりました。消費メモリは次の通り。

3. FLUX.1 [schnell]
「Google Colab」でのFLUX.1 [schnell] (タイムステップ蒸留モデル) の実行手順は、次のとおりです。
・max_sequence_length は 256 を超えることはできない
・guidance_scale は 0 である必要がある
・タイムステップ蒸留モデルであるため、ステップが少ないほど有利
(1) パッケージのインストール。
# パッケージのインストール
!pip install git+https://github.com/huggingface/diffusers.git(2) パイプラインの準備。
「black-forest-labs/FLUX.1-schnell」をダウンロードします。
import torch
from diffusers import FluxPipeline
# パイプラインの準備
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-schnell",
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload()(3) プロンプトの準備と画像生成の実行。
# プロンプトの準備
prompt = "cute cat ear maid of japanese anime style"
# 画像生成の実行
out = pipe(
prompt=prompt,
guidance_scale=0.,
width=1024,
height=1024,
num_inference_steps=4,
max_sequence_length=256,
).images[0]
out.save("image.png")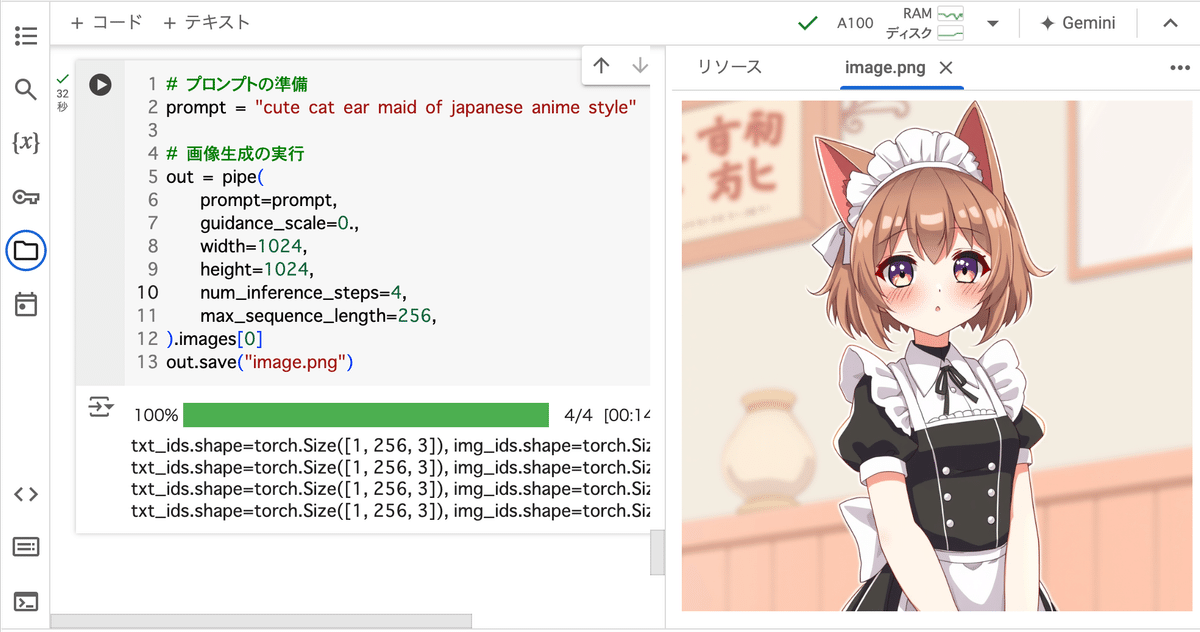
4ステップで34秒かかりました。消費メモリは次の通り。

4. Comfy UI
「Comfy UI」で「FLUX.1」の使い方は、以下の記事が参考になりました。
【注意】Macでノイジー画像しかでない不具合の解決策はこちら。
「Stability Matrix」での対応コマンドの例は次のとおりです。
cd "/Users/<ユーザー名>/Library/Application Support/StabilityMatrix/Packages/ComfyUI"
source venv/bin/activate
pip install torch==2.3.1 torchaudio==2.3.1 torchvision==0.18.1