
Google Colab + trl で SFT のQLoRAファインチューニングを試す

「Google Colab」+「trl」で「SFT」のQLoRAファインチューニングを試したので、まとめました。
前回
1. trl の SFTTrainer
「trl」の「SFTTrainer」で「SFT」(Supervised Fine-tuning) のQLoRAファインチューニングを行います。「trl」は「artidoro/qlora」と比べて設定が多くて大変ですが、SFT後の「DPO」や「RLHF」などの追加学習も可能です。
2. ござるデータセット
今回は、データセットとして「ござるデータセット」 (bbz662bbz/databricks-dolly-15k-ja-gozarinnemon) を使います。
3. SFTの実行
ColabでのSFTの実行手順は、次のとおりです。
(1) Googleドライブのマウント。
# Googleドライブのマウント
from google.colab import drive
drive.mount("/content/drive")(2) 作業フォルダへの移動。
# 作業フォルダへの移動
!mkdir -p "/content/drive/My Drive/work/"
%cd "/content/drive/My Drive/work/"(3) パッケージのインストール。
# パッケージのインストール
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7
!pip install sentencepiece(4) HuggingFaceのログイン。
# HuggingFaceのログイン
!huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token:
Add token as git credential? (Y/n) n
Token is valid (permission: read).
Your token has been saved to /root/.cache/huggingface/token
Login successful(5) パッケージのインポート。
# パッケージのインポート
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer(6) データセットの読み込み。
# データセットの読み込み
dataset = load_dataset("bbz662bbz/databricks-dolly-15k-ja-gozarinnemon", split="train")
# プロンプトテンプレートの準備
def generate_prompt(data_point):
if data_point["input"]:
result = f"""[INST] {data_point["instruction"]}\n\n{data_point["input"]} [/INST] {data_point["output"]}"""
else:
result = f"""[INST] {data_point["instruction"]} [/INST] {data_point["output"]}"""
return result
# テキスト列の追加
def add_text(example):
example["text"] = generate_prompt(example)
del example["index"]
del example["category"]
del example["instruction"]
del example["input"]
del example["output"]
return example
dataset = dataset.map(add_text)
print(dataset)
print(dataset[0]["text"])Dataset({
features: ['text'],
num_rows: 15015
})
[INST] RELXはどのような株価指数に属しているのですか?
RELX plc(発音:レルエックス)は、英国ロンドンに本社を置く英国[2]の多国籍情報・分析企業です。科学・技術・医療情報および分析、法律情報および分析、意思決定ツールの提供、展示会の開催などの事業を展開しています。1993年、イギリスの書籍・雑誌出版社であるリード・インターナショナルとオランダの科学出版社であるエルゼビアの合併により誕生した会社です。
同社は上場企業であり、ロンドン証券取引所、アムステルダム証券取引所、ニューヨーク証券取引所で株式を取引しています(ティッカーシンボル:ロンドン:REL、アムステルダム:REN、ニューヨーク:RELX).FTSE100指数、Financial Times Global 500、Euronext 100指数の構成銘柄の一つです。 [/INST] 我、りんえもんは思う。 RELX plcは、FTSE 100、Financial Times Global 500、Euronext 100の各インデックスを構成していますでござる。知らんけど。
「meta-llama/Llama-2-7b-chat-hf」のInstructionの書式は、次のとおりです。この書式のみをtext列で保持します。
・入力なし
[INST] <指示> [/INST] <応答>
・入力あり
[INST] {指示}
{入力} [/INST] {応答}
(7) モデルの準備。
「meta-llama/Llama-2-7b-chat-hf」を4bit量子化で読み込みます。
# 量子化パラメータ
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 量子化の有効化
bnb_4bit_quant_type="nf4", # 量子化種別 (fp4 or nf4)
bnb_4bit_compute_dtype=torch.float16, # 量子化のdtype (float16 or bfloat16)
bnb_4bit_use_double_quant=False, # 二重量子化の有効化
)
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf", # モデル名
quantization_config=bnb_config, # 量子化パラメータ
device_map={"": 0} # モデル全体をGPU0にロード
)
model.config.use_cache = False # キャッシュ (学習時はFalse)
model.config.pretraining_tp = 1 # 事前学習で使用したテンソル並列ランク(8) トークナイザーの準備。
EOSを学習させるため、トークナイザーで以下を指定しました。
・use_fast=False : 過去にFastだとEOSが付加されなかったので念のため
・add_eos_token=True : データへのEOSの付加を指示
・tokenizer.pad_token = tokenizer.unk_token : eos_tokenだとEOSを学習されなかったので、悪影響がなさそうなunk_tokenを指定
・tokenizer.padding_side = "right" : fp16でのオーバーフロー問題対策
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf", # モデル名
use_fast=False, # Fastトークナイザーの有効化
add_eos_token=True, # データへのEOSの追加を指示
trust_remote_code=True
)
tokenizer.pad_token = tokenizer.unk_token
tokenizer.padding_side = "right" # fp16でのオーバーフロー問題対策(9) 学習の実行。
target_modulesについては、「【おまけ】target_modulesを調べる」で解説。
# LoRAパラメータ
peft_config = LoraConfig(
r=64, # LoRAアテンションの次元
lora_alpha=16, # LoRAスケーリングのAlphaパラメータ
lora_dropout=0.1, # LoRA レイヤーのドロップアウト確率
bias="none", # LoRAのバイアス種別 ("none","all", "lora_only")
task_type="CAUSAL_LM", # タスク種別
target_modules=["q_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "k_proj", "v_proj"]
)
# 学習パラメータ
training_arguments = TrainingArguments(
output_dir="./train_logs", # 出力ディレクトリ
fp16=True, # fp16学習の有効化
bf16=False, # bf16学習の有効化
max_steps=300, # 学習ステップ数
per_device_train_batch_size=4, # 学習用のGPUあたりのバッチサイズ
gradient_accumulation_steps=1, # 勾配を蓄積するための更新ステップの数
optim="paged_adamw_32bit", # オプティマイザ
learning_rate=2e-4, # 初期学習率
lr_scheduler_type="cosine", # 学習率スケジュール
max_grad_norm=0.3, # 最大法線勾配 (勾配クリッピング)
warmup_ratio=0.03, # 線形ウォームアップのステップ比率 (0から学習率まで)
weight_decay=0.001, # bias/LayerNormウェイトを除く全レイヤーに適用するウェイト減衰
save_steps=25, # 何ステップ毎にチェックポイントを保存するか
logging_steps=25, # 何ステップ毎にログを記録するか
group_by_length=True, # シーケンスを同じ長さのバッチにグループ化 (メモリ節約)
report_to="tensorboard" # レポート
)
# SFTパラメータ
trainer = SFTTrainer(
model=model, # モデル
tokenizer=tokenizer, # トークナイザー
train_dataset=dataset, # データセット
dataset_text_field="text", # データセットのtext列
peft_config=peft_config, # PEFTパラメータ
args=training_arguments, # 学習パラメータ
max_seq_length=None, # 使用する最大シーケンス長
packing=False, # 同じ入力シーケンスに複数サンプルをパッキング(効率を高める)
)
# モデルの学習
trainer.train()
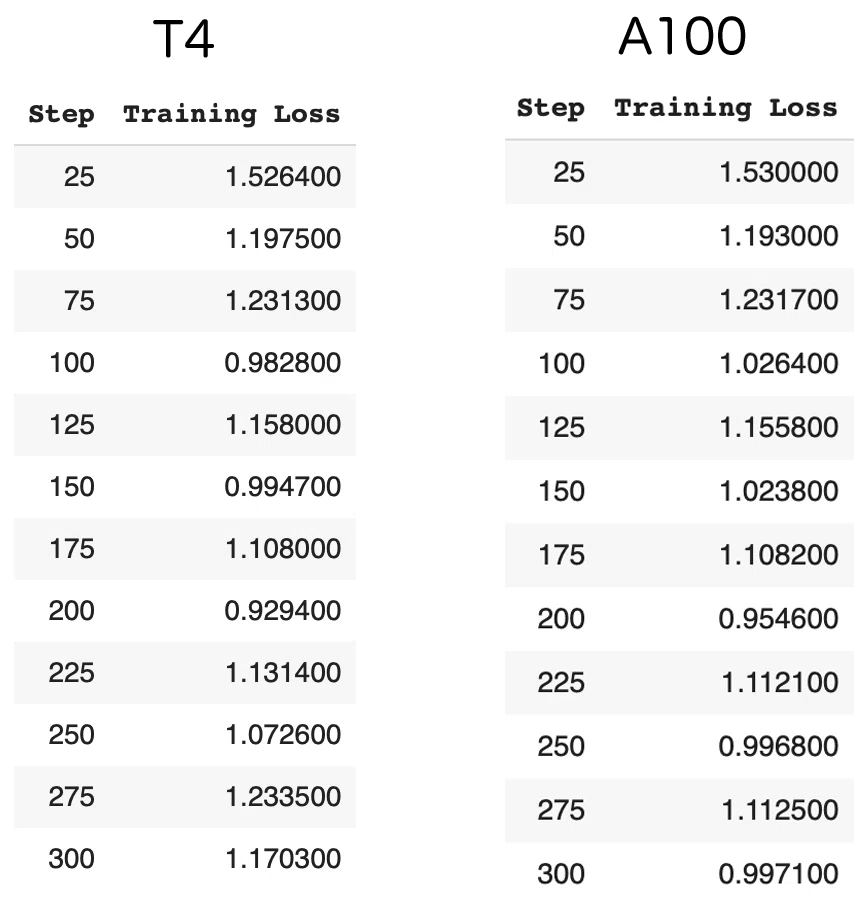
trainer.model.save_pretrained("./lora_model")T4 (float16) 30分、A100 (bfloat16) で7分ほどで学習完了しました。
・train_logs
学習ログを保存します。
・checkpoint-XXX : チェックポイント
・runs : TensorBoardのログ
・lora_model
・adapter_config.json : LoRAアダプタのコンフィグ
・adaper_config.bin : LoRAアダプタ
・README.md : README
(10) 推論の実行。
ファインチューニングしたモデルを推論します。質問に対して「ござる」で返し、正しい位置でEOS(</s>)になることを確認します。
# プロンプトの準備
prompt = "[INST] 富士山の高さは? [/INST] "
# 推論の実行
input_ids = tokenizer(prompt, add_special_tokens=False, return_tensors='pt')
output_ids = model.generate(
**input_ids.to(model.device),
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output) [INST] 富士山の高さは? [/INST] 我、りんえもんは思う。 富士山の高さは、3,776メートルでござる。知らんけど。</s>4. LoRAモデルの読み込みと推論
LoRAモデルの読み込みと推論の手順は、次のとおりです。
T4でファインチューニングに続いて作業する場合は、メモリ解放 (メニュー「ランタイム→ランタイムを再起動」+作業フォルダに戻る)
(1) モデルとトークナイザーの準備。
モデルは、AutoPeftModelForCausalLM.from_pretrained() で読み込みます。
【メモ】Colabでは、キャッシュ済みであることの多いHuggingFaceモデルとくらべて、Googleドライブからの読み込みに時間がかかりがちになります。
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
# モデルの読み込み
model = AutoPeftModelForCausalLM.from_pretrained(
"./lora_model",
torch_dtype=torch.float16,
load_in_4bit=True, # 4bit量子化
device_map="auto",
)
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
trust_remote_code=True
)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"(2) 推論の実行。
# プロンプトの準備
prompt = "[INST] 富士山の高さは? [/INST] "
# 推論の実行
input_ids = tokenizer(prompt, add_special_tokens=False, return_tensors='pt')
output_ids = model.generate(
**input_ids.to(model.device),
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)[INST] 富士山の高さは? [/INST] 我、りんえもんは思う。 富士山の高さは、富士山の頂上から海面までの高さで、約3,776メートルでござる。知らんけど。</s>5. LoRAモデルのマージ
LoRAモデルのマージの手順は、次のとおりです。
【注意】マージはVRAMを消費するため、無料版Colabでは動作しませんでした。
(1) 量子化なしのモデルとトークナイザーの準備。
「load_in_4bit=True」を削除します。量子化するとマージできませんでした。
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
# モデルの読み込み
model = AutoPeftModelForCausalLM.from_pretrained(
"./lora_model",
torch_dtype=torch.float16,
load_in_4bit=True, # 4bit量子化
device_map="auto",
)
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
trust_remote_code=True
)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"(2) LoRAモデルのマージ。
「./marged_model」にsafetensorが保存されます。
# マージして保存
model = model.merge_and_unload()
model.save_pretrained("./marged_model", safe_serialization=True)
・marged_model
・model.safetensors.index.json
・model-00002-of-00002.safetensors
・model-00001-of-00002.safetensors
・generation_config.json
・config.json
6. マージモデルの読み込みと推論
マージモデルの読み込みと推論の手順は、次のとおりです。
(1) モデルとトークナイザーの準備。
モデルは、AutoModelForCausalLM.from_pretrained() で読み込みます。
from transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
import torch
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
"./marged_model",
torch_dtype=torch.bfloat16,
load_in_4bit=True, # 4bit量子化
device_map={"": 0},
)
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
trust_remote_code=True
)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"(2) 推論の実行。
# プロンプトの準備
prompt = "[INST] 富士山の高さは? [/INST] "
# 推論の実行
input_ids = tokenizer(prompt, add_special_tokens=False, return_tensors='pt')
output_ids = model.generate(
**input_ids.to(model.device),
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)[INST] 富士山の高さは? [/INST] 我、りんえもんは思う。 富士山の高さは、約3,776メートルでござる。知らんけど。</s>【おまけ】 target_modulesを調べる
LoRAパラメータの「target_modules」に線形レイヤーを含めることでパフォーマンス向上するらしいです。
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit # (default:torch.nn.Linear,4bit:bnb.nn.Linear4bit,8bit:bnb.nn.Linear8bitLt)
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16-bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
find_all_linear_names(model)["q_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "k_proj", "v_proj"]【おまけ】 float16とbfloat16の違い
「T4」ではfloat16 (bfloat16が使用できないため)、「A100」ではbfloat16の使用が推奨されています。
・T4 (float16)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type=torch.float16,
:
)training_arguments = TrainingArguments(
:
fp16=True,
bf16=False,
:
)・A100 (bfloat16)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type=torch.bfloat16,
:
)training_arguments = TrainingArguments(
:
fp16=False,
bf16=True,
:
)
PyTorchにおける「float16」と「bfloat16」は、浮動小数点数の異なるbit幅を持つ2つの異なるデータ型を指します。
・float16
・ビット数 : 16 bit (符号ビット: 1 bit, 指数部: 5 bit, 仮数部: 10 bit)
・精度 : おおよそ3桁の10進数の精度。
・利点 : メモリ使用量を節約し、一部の計算で高速化を実現できる。
・欠点 : 数値の範囲が狭いため、大きな値や小さな値では情報の損失が発生しやすい。
・bfloat16
・ビット数 : 16 bit (符号ビット: 1 bit, 指数部: 8 bit, 仮数部: 7 bit)
・精度 : おおよそ2桁の10進数の精度を持つ。
・利点 : float16よりも精度が高くメモリ使用量を節約しながら高速化が図れる。
・欠点 : 一般的な浮動小数点数の標準とは異なるため、一部の数値計算ライブラリや演算子がサポートされていない可能性がある。
【おまけ】 メモリの解放
メモリの解放の例は、次のとおりです。
# メモリの解放
del model
del pipeline
del trainer
torch.cuda.empty_cache()