
DeepSeek R1 Dynamic 1.58-bit の概要

以下の記事が面白かったので、簡単にまとめました。
1. DeepSeek R1 Dynamic 1.58-bit
「DeepSeek-R1」は、オープンでありながら、「OpenAI」のo1に匹敵することで話題になっています。「Unsloth」では、より多くのローカルユーザーがこれを実行できるようにする方法を検討し、「DeepSeek-R1 671B」を「131GB」のサイズに量子化することに成功しました。これは、非常に機能的でありながら、元の720GBから80%のサイズ削減です。
「DeepSeek R1」のアーキテクチャを研究することで、特定のレイヤーを高bit (4bitなど) で選択的に量子化し、残り多くの MoEレイヤーを 1.5bitのままにすることに成功しました。すべてのレイヤーを単純に量子化すると、モデルが完全に壊れ、無限ループと意味不明な出力が発生します。Unslothの動的量子化 (Dynamic Quant) はこれを解決します。
高速推論 (2x H100 80GB) も 160GBのVRAM に収まり、スループットでは1 秒あたり約140トークン、単一ユーザー推論では1秒あたり14トークンを達成します。1.58bit R1 を実行するために VRAM (GPU) は必要ありません。20GBのRAM (CPU) があれば動作しますが、遅くなる場合があります。最適な性能を得るには、VRAM + RAM の合計が少なくとも 80GB 以上であることを推奨します。
2. 動的量子化版
「Unsloth」では4つの動的量子化版を提供しています。最初の3つは、重要度マトリックスを使用して量子化プロセス (llama.cpp経由のimatrix) を調整し、より低いbit表現を可能にします。最後の212GB版は、調整が行われていない一般的な 2bit量子です。

3. ベンチマーク
すべての量子化モデルをテストするために、一般的なベンチマークに頼るのではなく、「DeepSeek R1」に3回の試行で「Flappy Bird」を作成するように依頼し(pass@3)、10の基準(ランダムな色、ランダムな形の使用、Pythonインタープリターで実行できるかどうかなど)でスコアを付けました。シードは3407、3408、3409、推奨温度は0.6を使用しました。
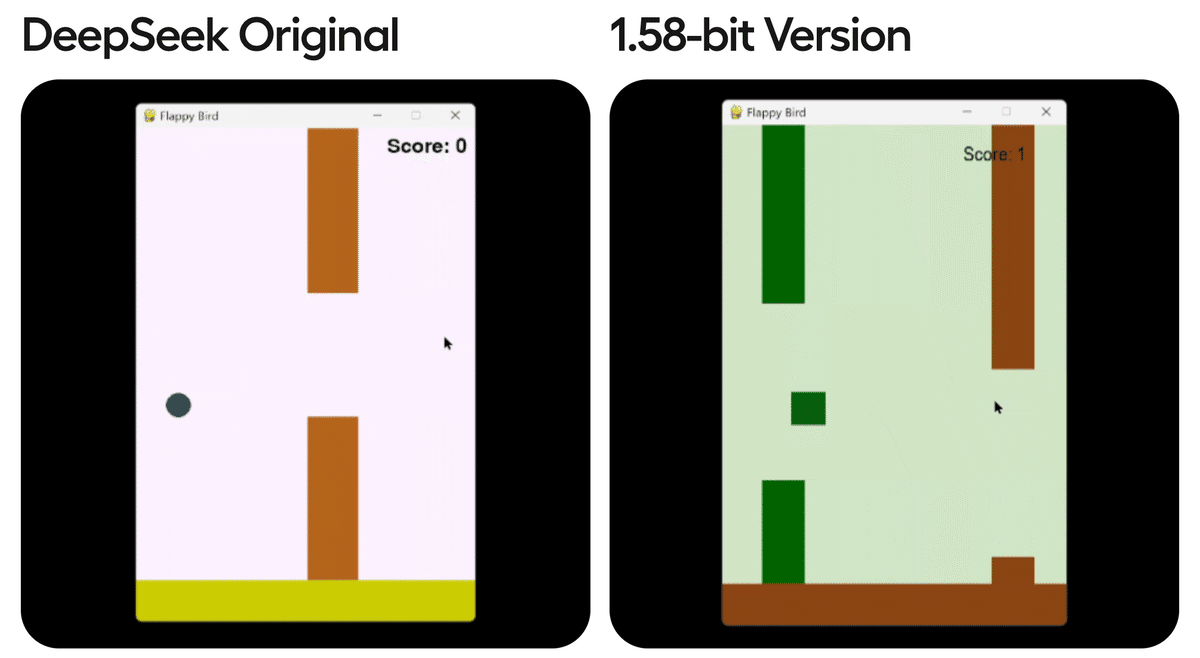
モデルのサイズを80%削減した後でも、Unslothの1.58bit版は有効な出力を生成できることがわかります。
しかし、Dynamic 1.58bit を使用せず、すべてのレイヤーを単純に量子化すると、シード3407では「Colours with dark Colours with dark Colours with dark Colours with dark Colours with dark」のように無限に繰り返されたり、シード3408では「Set up the Pygame's Pygame display with a Pygame's Pygame's Pygame's Pygame's Pygame's Pygame's Pygame's Pygame's Pygame's」のような出力になってしまいます。
同様に、動的量子化を使用せず、すべてのレイヤーを1.75bit (149GB) に量子化すると、無限ループは止まりますが、出力は完全に不正確になります。すべての出力が真っ黒な画面になります。さらに、すべてのレイヤーを2.06bit (175GB) に量子化すると、1.58bit (131GB) の動的量子化よりもさらに悪い結果になります。それならば、より優れた性能を発揮する2.22bit (183GB) 版を使用する方が賢明です。
1.58bitの動的量子化は、稀にですが 8000 トークンごとに1つの誤ったトークンを生成することがあり、これをコメントアウトする必要があります。最小確率 (min_p) を 0.1 または 0.05 に設定すると、1.58bitの量子化が単発の誤ったトークンを生成するのを軽減できるはずです。
10点満点のスコアと Pass@3 の評価では、1.58bit 131GB版は「Flappy Bird」ベンチマークで 69.2%の正答率を記録し、2bit 183GB版は 91.7% を達成しました。
一方、動的でない量子化は成績が非常に悪いです。すべてのレイヤーを 1.58bitに量子化すると、ベンチマークで 0% という結果になり、175GB のモデルでも 61.7% にとどまりました。これは、動的量子化版よりもスコアが低く、モデルサイズも大きいにもかかわらず、性能が劣ることを示しています。

4. DeepSeek R1 アーキテクチャの活用
前回の分析合成データ生成に「DeepSeek R1」を使用した「DeepSeek V3」では、「DeepSeek」の最初の3つのレイヤーは完全に密であり、「MoE」ではないことに気付きました。おさらいすると、「MoE」レイヤーを使用すると、ほとんどのエントリを0として動的にマスクし、ゼロにされたエントリに対する行列の乗算を基本的にスキップするため、使用されるFLOPの数を増やすことなく、モデル内のパラメータの数を増やすことができます。

「MoE」の目的は、計算コストを変えずにパラメータの数を増やすことでスケーリング則を「騙す」ことです。「MoE」に関する詳しい情報と、「MoE」よりも優れた性能を目指す「Memory Layers」と呼ばれる新しい方法については、このツイートを参照してください。
以下の4つのアイデアを組み合わせることで、洞察を活用することができました。
・Unslothの4-bit Dynamic Quantization手法
・1.58-bit LLMs paper
・Llama.cpp’s 1.5-bit 量子化
・Super Weights paper
(1) 最初の3つの高密度レイヤーは、すべての重みの 0.5% を使用します。これらは4bitまたは6bitのままにします。
(2) MoEレイヤーは共有エキスパートを使用し、重みは 1.5% にします。6bitを使用します。
(3) すべてのMLAアテンション モジュールを4bitまたは6bitのままにして、重みを 5% 未満にすることができます。アテンション出力 (3%) を量子化する必要がありますが、より高い精度のままにしておくのが最適です。
(4) down_projは量子化の影響を最も受けやすく、特に最初の数層ではその傾向が顕著です。私たちはSuper Weights論文、動的量子化法、llama.cppのGGUF量子化法で調査結果を裏付けました。そのため、最初の3~6個のMoE down_proj行列は高精度のままにしておきます。たとえば、Super Weights paper を見ると、量子化されるべきではないほぼすべての重みが down_proj にあることがわかります。

すべての「Super Weights」または最も重要な重みが down_proj にある主な理由は、SwiGLU が次のことを行うためです。

これは、アップとゲートの投影が本質的に大きな数値を形成するために乗算され、down_proj がそれらを縮小する必要があることを意味します。つまり、特にトランスフォーマーの初期レイヤーでは、down_proj を量子化することは良い考えではない可能性があります。
(5) 埋め込みと lm_head はそれぞれ4bitと6bitのままにしておきます。MoEルーターとすべてのレイヤーノルムは32bitのままにします。
(6) これにより、重みの約88%がMoE重みとして残ります。これを 1.58bitに量子化することで、モデルを大幅に縮小できます。
(7) 動的量子化コードを llama.cpp へのフォークとして提供しました。
(8) Bartowskiの下位量子に対する重要度マトリックスを活用しました。。
5. チャットテンプレートの問題
すべての蒸留バージョンとメインの 671B R1 モデルは同じチャットテンプレートを使用します。
<|begin▁of▁sentence|><|User|>What is 1+1?<|Assistant|>It's 2.<|end▁of▁sentence|><|User|>Explain more!<|Assistant|>
「BOS」は強制的に追加され、「EOS」は各インタラクションを分離します。推論中に二重の「BOS」に対抗するには、チャットテンプレートによっても「BOS」が自動的に追加されるため、tokenizer.encode(..., add_special_tokens = False)
のみを呼び出す必要があります。llama.cpp / GGUF 推論では、「BOS」が自動的に追加されるため、BOS をスキップする必要があります。
<|User|>What is 1+1?<|Assistant|>
<think> および </think> には、それぞれ専用のトークンが割り当てられます。Qwen および Llama の精製版では、一部のトークンが再マップされますが、たとえば Qwen には「BOS」がないため、代わりに <|object_ref_start|> を使用する必要があります。
・トークナイザー ID マッピング
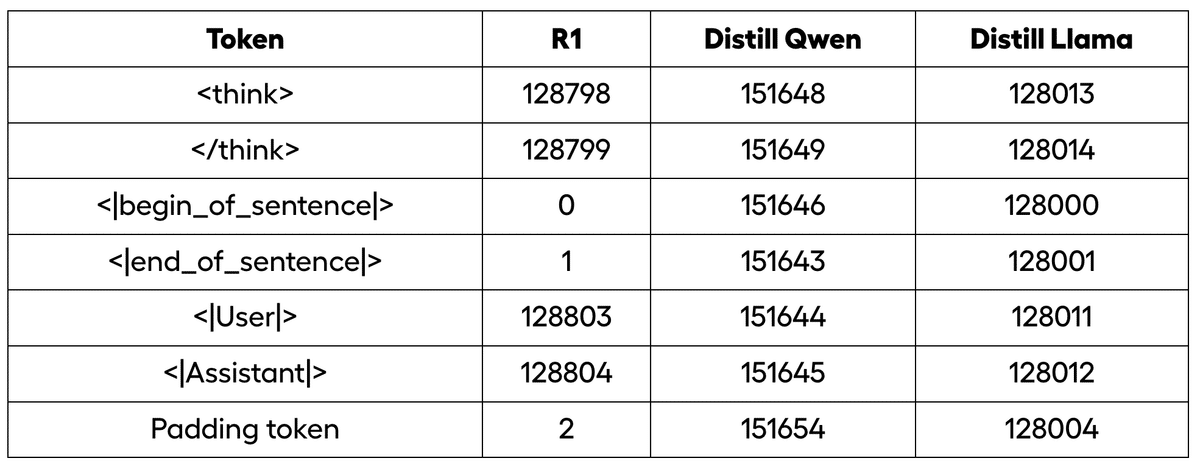
・モデル内のオリジナルトークン

すべての Distilled版と元のR1版では、パディングトークンが誤って <|end of sentence|> に割り当てられているようです。これは、特にこれらの推論モデルをさらにファインチューニングする場合、ほとんどの場合、良い考えではありません。ほとんどのフレームワークは「EOS」を -100 としてマスクするため、これにより無限の生成が繰り返されます。
すべての Distilled版と元のR1版を正しいパディングトークンで修正しました (Qwen は <|vision_pad|>、Llama は <|finetune_right_pad_id|>、R1 は <| pad |> または独自に追加した <|PAD TOKEN|> を使用します)。
6. 動的量子化モデルの実行
新しいllama.cppを使用する必要はありません。 GGUF を実行できるシステム (Ollama、OpenWebUI、Transformers、vLLM など) であれば、動的量子化モデルを実行できるはずです。十分なVRAMまたはRAMがない場合、遅くなる可能性がありますが、動作します。
llama.cpp を直接使用したい場合は、ここにある llama.cpp のビルド手順に従ってください。GPU サポートを有効にする必要があります。
apt-get update
apt-get install build-essential cmake curl libcurl4-openssl-dev -y
git clone https://github.com/ggerganov/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli
cp llama.cpp/build/bin/llama-* llama.cpp次にモデルをダウンロードします。これには HuggingFace を使用できます。1.58bit版をダウンロードするには、以下のコードを実行します。ダウンロードを高速化したい場合は、以下の最初の数行のコメントアウトを解除して hf_transfer も使用してください。
# pip install huggingface_hub hf_transfer
# import os # Optional for faster downloading
# os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"],
)これにより、3つのGGUFが「DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S」にダウンロードされます。次に以下の式を使用して、GPU にオフロードできるレイヤーの数を決定します。GPUがない場合は、オフロードを0に設定します。

「DeepSeek R1」には 61のレイヤーがあります。たとえば、「24GB GPU」または「80GB GPU」の場合、切り捨て後のオフロードが期待できます (メモリが不足する場合は 1 減らします)。

モデルを実行するには、Kキャッシュを4bitに量子化します。Vキャッシュを量子化するには、フラッシュアテンションカーネルを llama.cpp 用にコンパイルする必要があります。マシン上のすべてのスレッドを使用し、DeepSeek の推奨温度 0.6 を使用します。コンテキストサイズは、モデルで生成するトークンの数です。
メインディレクトリに移動すると、llama.cpp フォルダーと DeepSeek-R1-GGUF フォルダーが表示されます。
-- threads == CPU コアの数
--ctx-size == 出力のコンテキストの長さ
--n-gpu-layers == GPU にオフロードするレイヤーの数 (上記の表から取得)
24GB VRAM / メモリを搭載した RTX 4090 GPU では、次のようにします。
./llama.cpp/llama-cli \
--model DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--cache-type-k q4_0 \
--threads 16 \
--prio 2 \
--temp 0.6 \
--ctx-size 8192 \
--seed 3407 \
--n-gpu-layers 7 \
-no-cnv \
--prompt "<|User|>Create a Flappy Bird game in Python.<|Assistant|>"7. Mac / Appleデバイスでの実行
Apple Metalデバイスの場合、--n-gpu-layers に注意してください。マシンのメモリが不足している場合は、メモリを減らしてください。128GBの統合メモリマシンの場合、59層程度をオフロードできます。
./llama.cpp/llama-cli \
--model DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--cache-type-k q4_0 \
--threads 16 \
--prio 2 \
--temp 0.6 \
--ctx-size 8192 \
--seed 3407 \
--n-gpu-layers 59 \
-no-cnv \
--prompt "<|User|>Create a Flappy Bird game in Python.<|Assistant|>"8. Ollama/vLLM での実行
GGUFの推論にOllamaまたはvLLMを使用する場合、まず以下のコードのように3つのGGUF分割ファイルを1つにマージする必要があります。次に、モデルをローカルで実行する必要があります。
./llama.cpp/llama-gguf-split --merge \
DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
merged_file.gguf9. プロンプトと結果
使用されたプロンプトは次のとおりです。
Create a Flappy Bird game in Python. You must include these things:You must use pygame.
1. The background color should be randomly chosen and is a light shade. Start with a light blue color.
2. Pressing SPACE multiple times will accelerate the bird.
3. The bird's shape should be randomly chosen as a square, circle or triangle. The color should be randomly chosen as a dark color.
4. Place on the bottom some land colored as dark brown or yellow chosen randomly.
5. Make a score shown on the top right side. Increment if you pass pipes and don't hit them.
6. Make randomly spaced pipes with enough space. Color them randomly as dark green or light brown or a dark gray shade.
7. When you lose, show the best score. Make the text inside the screen. 8. Pressing q or Esc will quit the game. Restarting is pressing SPACE again.
The final game should be inside a markdown section in Python. Check your code for errors and fix them before the final markdown section.
【翻訳】
Python で Flappy Bird ゲームを作成します。次の項目を含める必要があります。
(1) pygame を使用する必要があります。
(2) 背景色はランダムに選択し、明るい色合いにします。まずは明るい青色から始めます。
(3) スペースキーを複数回押すと鳥が加速します。
(4) 鳥の形は、四角、円、三角形の中からランダムに選択します。色は暗い色からランダムに選択します。
(5) ランダムに選んだ濃い茶色または黄色の土地を下部に置きます。
(6) 右上に表示されるスコアを獲得します。パイプを通過してパイプに当たらなかった場合はスコアが増加します。
(7) 十分なスペースを確保しながら、ランダムな間隔でパイプを作ります。濃い緑、薄い茶色、濃い灰色など、ランダムに色付けします。
(8)負けたときは最高スコアを表示します。画面内にテキストを作成します。q または Esc キーを押すとゲームを終了します。再起動するには、もう一度 SPACE キーを押します。
最終的なゲームは、Python のマークダウン セクション内に記述する必要があります。コードにエラーがないか確認し、最終的なマークダウン セクションの前に修正してください。
結果はこちらにあります。