Google Colab で Stable Diffusion WebUI を試す

「Google Colab」で「Stable Diffusion WebUI」を試したので、まとめました。
【注意】無料版Colabでは画像生成AIの使用が規制されているため、Google Colab Pro / Pro+で動作確認しています。
・Stable Diffusion WebUI v1.7.0
1. Stable Diffusion WebUI
「Stable Diffusion WebUI」は、「Stable Diffusion」で画像生成するためのWebUIです。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」を選択。
(2) リポジトリのクローン。
# パッケージのインストール
!pip install torch==2.1.0 torchvision==0.16.0 xformers --index-url https://download.pytorch.org/whl/cu121
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd /content/stable-diffusion-webui(3) モデルを「models/Stable-diffusion」にダウンロード。
今回は、「IrisMix-v3」を使います。
# モデルのダウンロード
!wget https://huggingface.co/natsusakiyomi/IrisMix/resolve/main/IrisMix-v3.safetensors -O models/Stable-diffusion/IrisMix-v3.safetensors(4) 「Stable Diffusion WebUI」の実行。
初回はインストールやモデルダウンロードなどで数分ほどかかります。
# 実行
!python ./launch.py --share --xformers --enable-insecure-extension-access(5) 「https://XXXX.gradio.live」のURLが表示されたらクリック。

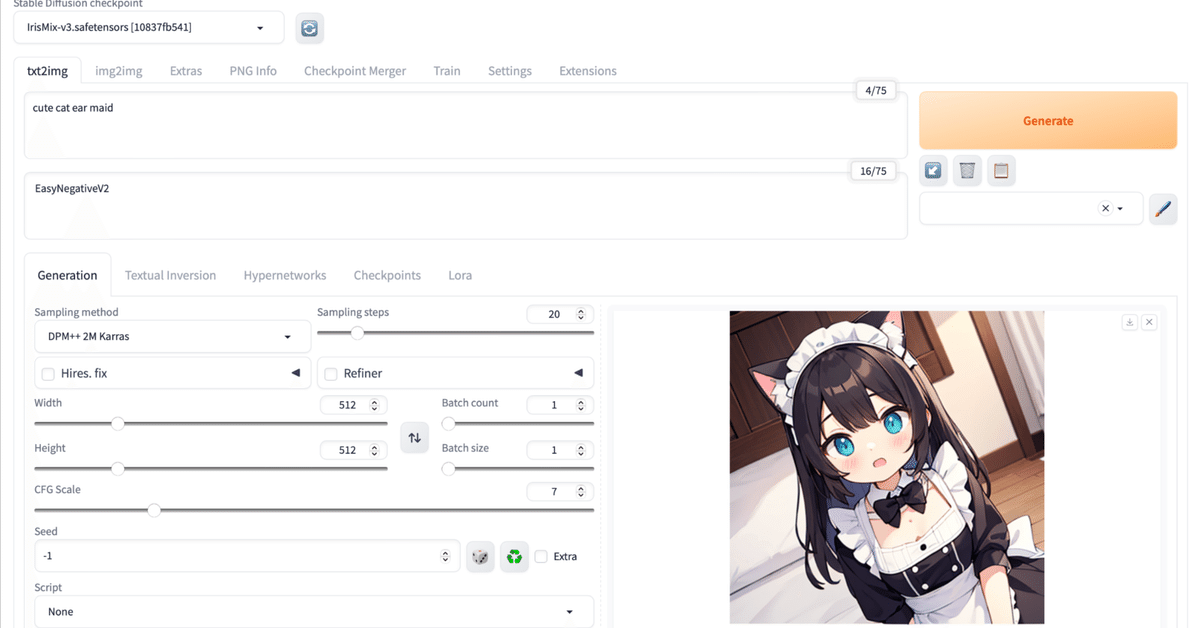
(6) 画像生成。
モデルに「IrisMix-v3」 、プロンプトに「cute cat ear maid」を指定して、「Generate」ボタンを押します。

3. EasyNegative
「EasyNegative」をネガティブプロンプトに指定することで、望ましくないものを含む画像の生成防止になります。
(1) 「Colab」のメニュー「ランタイム→実行を中断」で「Stable Diffusion WebUI」を停止。
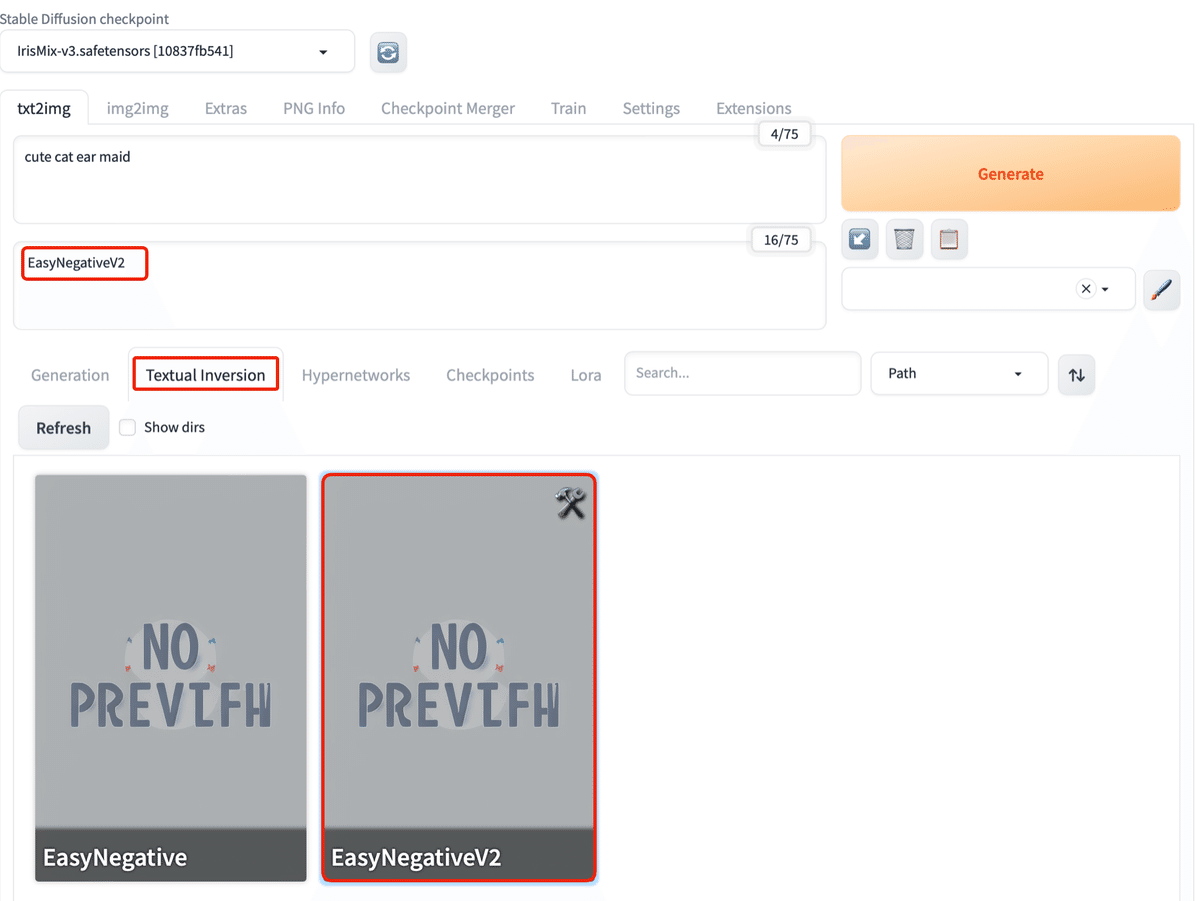
(2) 「EasyNegative」を「embeddings」にダウンロード。
「EasyNegative」と「EasyNegativeV2」の2種類があります。
# EasyNegativeV2のダウンロード
!wget https://huggingface.co/datasets/gsdf/EasyNegative/resolve/main/EasyNegative.safetensors -O embeddings/EasyNegative.safetensors
!wget https://huggingface.co/gsdf/Counterfeit-V3.0/resolve/main/embedding/EasyNegativeV2.safetensors -O embeddings/EasyNegativeV2.safetensors(3) 「Stable Diffusion WebUI」を実行。
(4) 「Textual Inversion」タグを選択し、ネガティブプロンプト領域を選択し、「EasyNegativeV2」をクリック。
ネガティブプロンプト領域に「EasyNegativeV2」が追加されます。
(5) Generateボタンを押して画像生成。
破綻のすくないクォリティの高い画像になります。

4. LoRA
「LoRA」を指定することで、特定のスタイルの画像を生成しやすくなります。
(1) 「Colab」のメニュー「ランタイム→実行を中断」で「Stable Diffusion WebUI」を停止。
(2) 「LoRAウェイト」を「models/Lora」にダウンロード。
今回は、「JujoHotaru/lora」の白目を使います。
# LoRAウェイトのダウンロード
!wget https://huggingface.co/JujoHotaru/lora/resolve/main/hotarueye_whiteeye9_v100.safetensors -O models/Lora/hotarueye_whiteeye9_v100.safetensors(3) 「Stable Diffusion WebUI」を実行。
(4) 「LoRA」タグを選択し、プロンプト領域を選択し、「hotarueye_whiteeye9_v100」をクリック。
プロンプト領域に「<lora:hotarueye_whiteeye9_v100:1>」が追加されます。

(5) Generateボタンを押して画像生成。
LoRAのスタイル (今回は白目) を反映した画像になります。

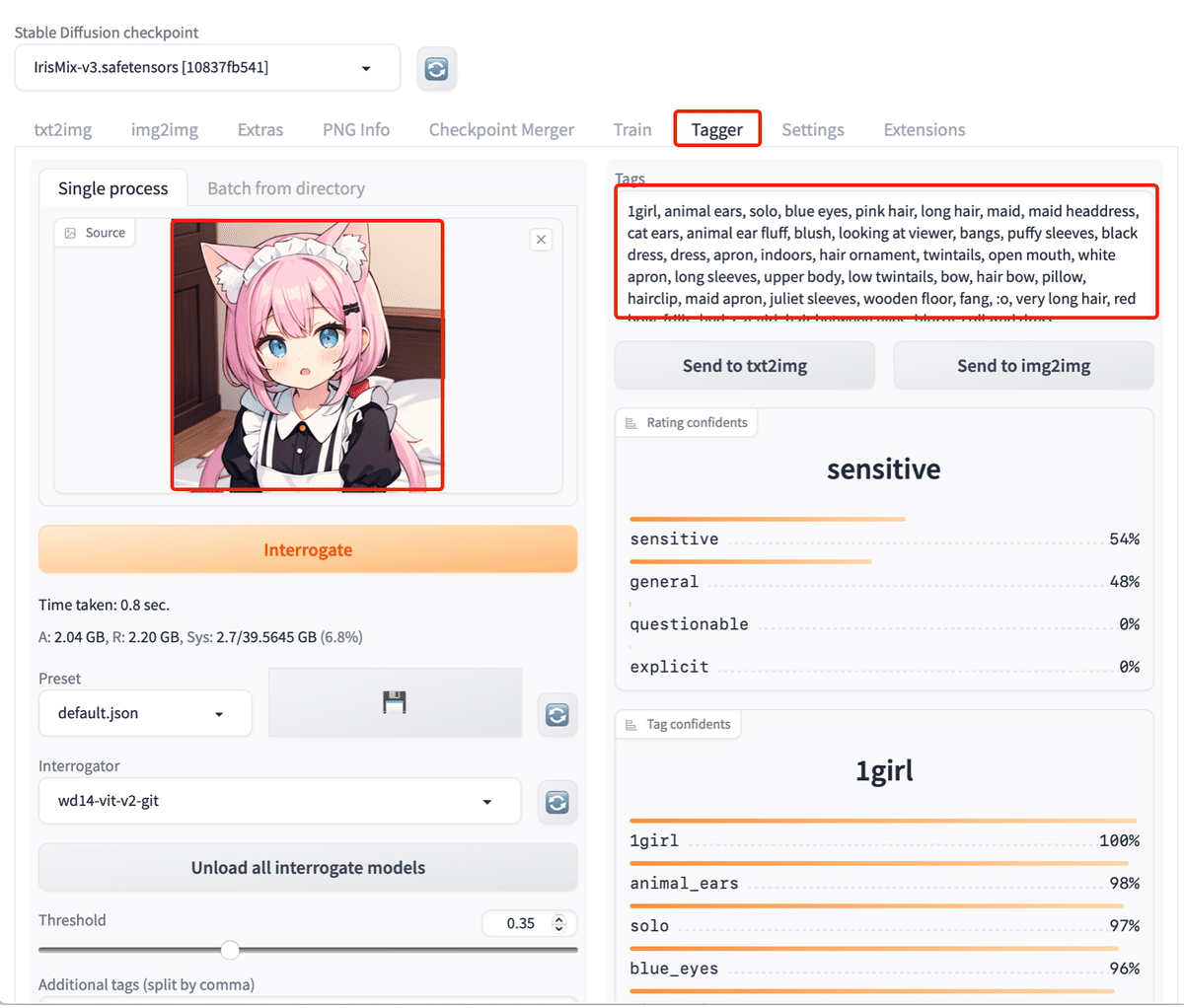
5. wd14-tagger
「wd14-tagger」は「Stable Diffusion WebUI」の拡張機能の1つで、画像の内容を解析してタグを生成します。
(1) 「Colab」のメニュー「ランタイム→実行を中断」で「Stable Diffusion WebUI」を停止。
(2) 「wd14-tagger」を「extentions」にダウンロード。
# wd14-taggerのダウンロード
!git clone https://github.com/toriato/stable-diffusion-webui-wd14-tagger /content/stable-diffusion-webui/extensions/stable-diffusion-webui-wd14-tagger/(3) 「wd14-tagger」をそのまま実行するとエラーがでるため、この記事を参考にソースコードを書き換える。
・stable-diffusion-webui\extensions\stable-diffusion-webui-wd14-tagger\preload.py
from modules.shared import models_path↓
import argparse
import os
modules_path = os.path.dirname(os.path.realpath(__file__))
parser_pre = argparse.ArgumentParser(add_help=False)
parser_pre.add_argument("--data-dir", type=str, default=os.path.dirname(modules_path), help="base path where all user data is stored", )
cmd_opts_pre = parser_pre.parse_known_args()[0]
data_path = cmd_opts_pre.data_dir
models_path = os.path.join(data_path, "models")・stable-diffusion-webui\extensions\stable-diffusion-webui-wd14-tagger\tagger\ui.py
from webui import wrap_gradio_gpu_call↓
from modules.call_queue import wrap_gradio_gpu_call(4) 「Stable Diffusion WebUI」を実行。
(5) 新規追加された「Tagger」を選択し、画像をドラッグ&ドロップ。
画像の内容を解析してタグが生成されます。