
Google Colab で japanese-reranker-cross-encoder-large-v1 を試す

「Google Colab」で「japanese-reranker-cross-encoder-large-v1」を試したので、まとめました。
1. japanese-reranker-cross-encoder-large-v1
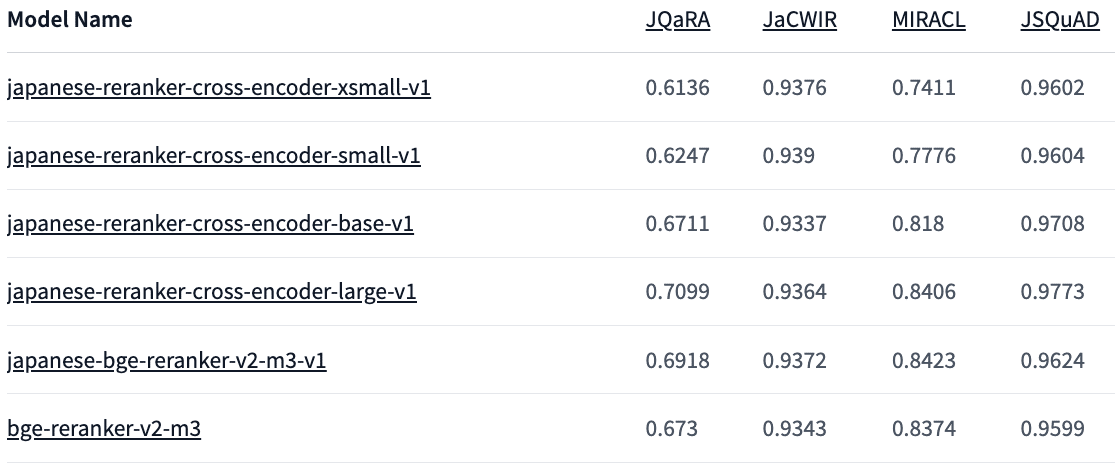
「 japanese-reranker-cross-encoder-large-v1」は、日本語に特化した形で学習した「Reranker」です。xsmallからlargeまで複数のサイズが提供されており、「large」は多言語Rerankerで最も人気のある「bge-reranker-v2-m3」をベンチマークで上回っています。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install transformers fugashi unidic-lite(3) トークナイザーとモデルの準備。
今回は、「hotchpotch/japanese-reranker-cross-encoder-large-v1」を使用します。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"hotchpotch/japanese-reranker-cross-encoder-large-v1"
)
model = AutoModelForSequenceClassification.from_pretrained(
"hotchpotch/japanese-reranker-cross-encoder-large-v1"
).to("cuda")
model.eval()(4) クエリと文章の準備と、スコアの計算。
from torch.nn import Sigmoid
# クエリとの文章の準備
query = "感動的な映画について"
passages = [
"深いテーマを持ちながらも、観る人の心を揺さぶる名作。登場人物の心情描写が秀逸で、ラストは涙なしでは見られない。",
"重要なメッセージ性は評価できるが、暗い話が続くので気分が落ち込んでしまった。もう少し明るい要素があればよかった。",
"どうにもリアリティに欠ける展開が気になった。もっと深みのある人間ドラマが見たかった。",
"アクションシーンが楽しすぎる。見ていて飽きない。ストーリーはシンプルだが、それが逆に良い。",
]
# スコアの計算
inputs = tokenizer(
[(query, passage) for passage in passages],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
inputs = {k: v.to("cuda") for k, v in inputs.items()}
logits = model(**inputs).logits
activation = Sigmoid()
scores = activation(logits).squeeze().tolist()
print(scores)[0.7776229381561279, 0.019648903980851173, 0.02329898253083229, 0.21026723086833954]1つ目の文章が、クエリと最も関連性が高いことがわかりました。