Google Colab で Janus-1.3B を試す

「Google Colab」で「Janus-1.3B」を試したのでまとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. Janus-1.3B
「Janus-1.3B」は、マルチモーダル理解と画像生成の両対応なモデルです。処理には単一の統合されたTransformerアーキテクチャを使用しながら、視覚エンコーディングを別々の経路に分離することで、従来のアプローチの限界に対処しています。

2. セットアップ
Google Colabでのセットアップ手順は、次のとおりです。
(1) リポジトリのクローンとインストール。
# リポジトリのクローンとインストール
!git clone https://github.com/deepseek-ai/Janus
%cd Janus
!pip install -e .(2) Flash Attention2 のインストール。
# Flash Attention2 のインストール
!pip install flash-attn --no-build-isolation(3) メニュー「ランタイム→セッションを再起動する」で再起動した後、元フォルダに戻る。
# メニュー「ランタイム→セッションを再起動する」で再起動した後、元フォルダに戻る
%cd Janus3. マルチモーダル理解
(1) 画面左端のフォルダアイコンから画像「bocchi.png」を「Janus」フォルダにアップロード。
(2) プロセッサとモデルとトークナイザーの準備。
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images
# プロセッサとモデルとトークナイザーの準備
model_path = "deepseek-ai/Janus-1.3B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()(3) 推論の実行。
# プロンプトの準備
conversation = [
{
"role": "User",
"content": "<image_placeholder>\nConvert the formula into latex code.",
"images": ["images/equation.png"],
},
{"role": "Assistant", "content": ""},
]
# 画像の読み込み
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)
# 画像の埋め込みの取得
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
# 推論の実行
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.
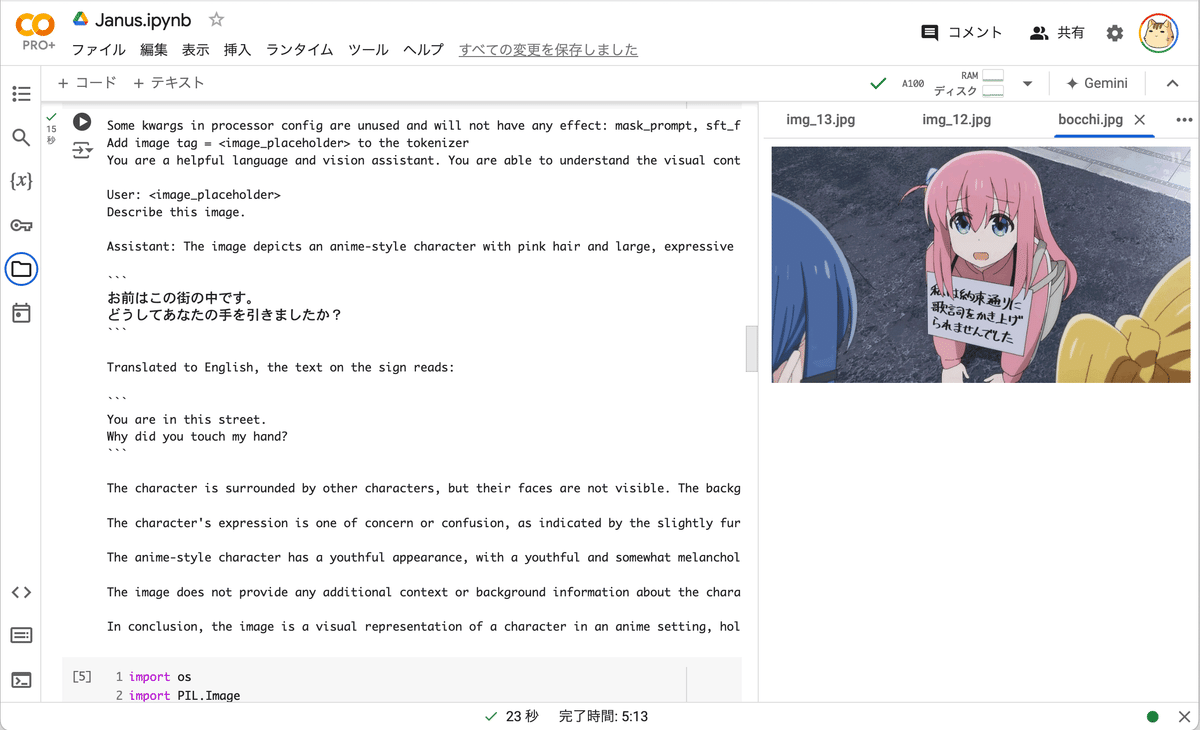
User: <image_placeholder>
Describe this image.
Assistant: The image depicts an anime-style character with pink hair and large, expressive blue eyes. The character is holding a sign with both hands. The sign contains text written in Japanese. The text on the sign reads:
```
お前はこの街の中です。
どうしてあなたの手を引きましたか?
```
Translated to English, the text on the sign reads:
```
You are in this street.
Why did you touch my hand?
```
The character is surrounded by other characters, but their faces are not visible.The background appears to be an outdoor setting, possibly a street or a public area, with a gray pavement and a white line on the ground.
The character's expression is one of concern or confusion, as indicated by the slightly furrowed eyebrows and the hand on the chin.The overall mood of the image seems to be serious or somber.
The anime-style character has a youthful appearance, with a youthful and somewhat melancholic expression.
The character's hair is pink, and the eyes are large and expressive, which are characteristic features of many anime characters.
The image does not provide any additional context or background information about the characters or the setting.The focus is primarily on the character holding the sign and the surrounding environment.
In conclusion, the image is a visual representation of a character in an anime setting, holding a sign with Japanese text. The character's expression and the surrounding environment suggest a serious or emotional moment.
【翻訳】
あなたは役に立つ言語および視覚アシスタントです。ユーザーが提供する視覚コンテンツを理解し、自然言語を使用してさまざまなタスクでユーザーを支援することができます。
User: <image_placeholder>
この画像について説明してください。
Assistant: この画像には、ピンクの髪と大きくて表情豊かな青い目をしたアニメ風のキャラクターが描かれています。キャラクターは両手で看板を持っています。看板には日本語で書かれたテキストがあります。看板のテキストは次のとおりです。
```
お前はこの街の中です。
どうしてあなたの手を引きましたか?
```
英語に翻訳すると、標識の文章は次のようになります:
```
お前はこの街の中です。
どうしてあなたの手を引きましたか?
```
キャラクターは他のキャラクターに囲まれていますが、顔は見えません。背景は屋外の風景、おそらく通りか公共エリアで、灰色の舗装と地面に白い線があります。
キャラクターの表情は、眉を少し寄せ、あごに手を当てていることから、心配や混乱の表情をしています。画像全体の雰囲気は、深刻または陰鬱なようです。
アニメ風のキャラクターは若々しい外見で、若々しくやや憂鬱な表情をしています。キャラクターの髪はピンク色で、目は大きく表情豊かで、これは多くのアニメキャラクターの特徴です。
この画像では、キャラクターや設定に関する追加のコンテキストや背景情報は提供されていません。主に、看板を持っているキャラクターと周囲の環境に焦点が当てられています。
結論として、この画像は、日本語のテキストが書かれた看板を持っているアニメの設定のキャラクターの視覚的表現です。キャラクターの表情と周囲の環境は、深刻または感情的な瞬間を示唆しています。
4. 画像生成
(1) プロセッサとトークナイザーとモデルの準備。
import os
import PIL.Image
import torch
import numpy as np
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
# プロセッサとトークナイザーとモデルの準備
model_path = "deepseek-ai/Janus-1.3B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()(2) 画像生成の実行。
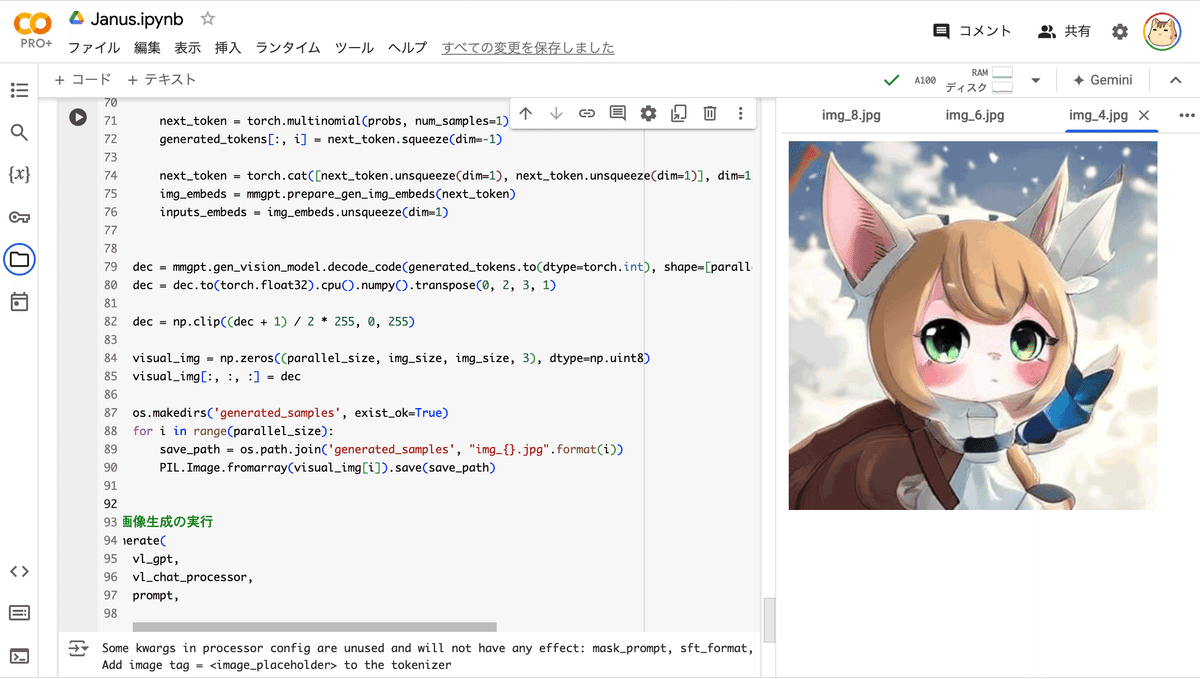
プロンプト「cute cat-ear maid of japanese anime style」で作成しました。
# プロンプトの準備
conversation = [
{
"role": "User",
"content": "cute cat-ear maid of japanese anime style",
},
{"role": "Assistant", "content": ""},
]
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_start_tag
# 画像生成の関数
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1,
parallel_size: int = 16,
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
probs = torch.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
os.makedirs('generated_samples', exist_ok=True)
for i in range(parallel_size):
save_path = os.path.join('generated_samples', "img_{}.jpg".format(i))
PIL.Image.fromarray(visual_img[i]).save(save_path)
# 画像生成の実行
generate(
vl_gpt,
vl_chat_processor,
prompt,
)「Janus/generated_samples」に16枚の画像が生成されています。