
LangChain v0.3 クイックスタートガイド - Python版

Python版の「LangChain」のクイックスタートガイドをまとめました。
・langchain 0.3.0
1. LangChain
「LangChain」は、「大規模言語モデル」 (LLM : Large language models) と連携するアプリの開発を支援するライブラリです。
「LLM」という革新的テクノロジーによって、開発者は今まで不可能だったことが可能になりました。しかし、「LLM」を単独で使用するだけでは、真に強力なアプリケーションを作成するのに不十分です。真の力は、それを他の 計算 や 知識 と組み合わせた時にもたらされます。「LangChain」は、そのようなアプリケーションの開発をサポートします。
2. LangChainのユースケース
主なユースケースは、次の3つになります。
・文書に関する質問応答
・チャットボット
・エージェント
3. LangChain のモジュール
「LangChain」は、言語モデル アプリケーションの構築に使用できる多くのモジュールを提供します。モジュールを組み合わせて複雑なアプリケーションを作成したり、個別に使用したりできます。
主なモジュールは、次のとおりです。
・Model I/O : モデルの入出力
・Language Model : 言語モデルによる推論の実行
・LLM : テキスト生成モデル
・ChatModel : チャットモデル
・Prompt Template : ユーザー入力からのプロンプトの生成
・Output Parser : 言語モデルの応答を構造データ化
・Chain : 複数のLLMやプロンプトの入出力を繋げる
・LCEL (LangChain Expression Language) : 表記言語によるチェーン実装
・Chain Interface : クラスによるチェーン実装 (レガシー)
・Agent : ユーザーの要求に応じてどの機能をどういう順番で実行するかを決定
・Memory : 過去のやりとりに関する情報を保持。
・Retrieval : 検索拡張生成 (RAG)
・Callback : ロギング、モニタリング、ストリーミングなどで利用
モジュールは、単純なアプリケーションではモジュール単体で使用でき、より複雑なユースケースではモジュールをチェーンで繋げて利用することができます。
4. インストール
Google Colabでのインストール手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install langchain==0.3.0
!pip install langchain_community
!pip install langgraph
!pip install langchain_openai(2) 環境変数の準備。
左端の鍵アイコンで「OPENAI_API_KEY」を設定してからセルを実行してください。
import os
from google.colab import userdata
# 環境変数の準備 (左端の鍵アイコンでOPENAI_API_KEYを設定)
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")5. Model I/O
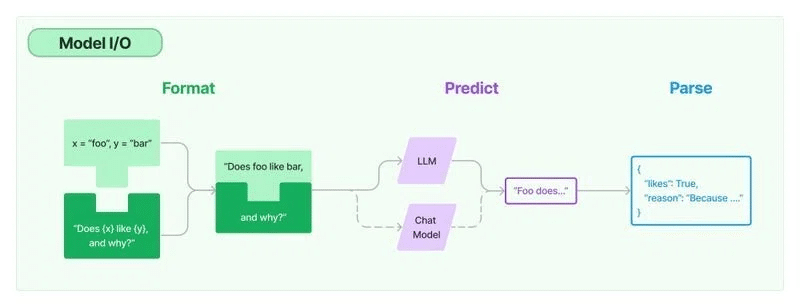
LLMアプリケーションの中核はLLMです。「LangChain」は、様々なLLMを手順で操作できる共通インタフェースを提供します。
主な構成要素は、次の3つです。
・Language Model
・Prompt Template
・Output Parser
5-1. Language Model
「LangChain」の最も基本的な機能は、LLMを呼び出すことです。「Language Model」は、LLMを呼び出すモジュールになります。
次の2種類のインタフェースを提供します。
・LLM
今回は例として、「テキスト生成モデル」でLLMの呼び出しを行います。テキスト→テキストのインタフェースになります。
from langchain_openai import OpenAI
# LLMの準備
llm = OpenAI(temperature=0.9)
# LLMの実行
output = llm.invoke("コンピュータゲームを作る日本語の新会社名をを1つ提案してください。")
print(type(output))
print(output)<class 'str'>
ツクルゲームスLLMの入力は文字列、出力は文字列になります。Messageリストで入力することも可能です。
・ChatModel
次に、「チャットモデル」でLLMの呼び出しを行います。メッセージリスト→メッセージのインタフェースになります。
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
# ChatModelの準備
chat_model = ChatOpenAI(temperature=0.9)
# ChatModelの実行
messages = [
HumanMessage(content="コンピュータゲームを作る日本語の新会社名をを1つ提案してください。")
]
output = chat_model.invoke(messages)
print(type(output))
print(output)<class 'langchain_core.messages.ai.AIMessage'>
content='「夢遊計画」(ゆめあるけいかく)' response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 38, 'total_tokens': 56}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None} id='run-93614b2e-aaba-40c6-ace3-f6abced6610e-0'ChatModelの入力はMessageリスト、出力はMessageになります。文字列で入力することも可能です。
メッセージは役割 (システム、ユーザー、AIなど) とコンテンツの情報を持ちます。「LangChain」の主なメッセージ型は、次の3種類です。
・SystemMessage : システムからのメッセージ
・HumanMessage : ユーザーからのメッセージ
・AIMessage : AIからのメッセージ
5-2. Prompt Template
「Prompt Template」は、ユーザー入力からプロンプトを生成するためのテンプレートです。アプリケーションで LLM を使用する場合、通常、ユーザー入力を直接LLM に渡すことはありません。ユーザー入力を基に「Prompt Template」でプロンプトを作成して、それをLLMに渡します。
今回は例として、ユーザー入力「作るもの」を基に「○○を作る日本語の新会社名をを1つ提案してください」というプロンプトを生成します。
from langchain_core.prompts import PromptTemplate
# プロンプトテンプレートの準備
prompt_template = PromptTemplate(
input_variables=["product"],
template="{product}を作る日本語の新会社名をを1つ提案してください",
)
# プロンプトテンプレートの実行
output = prompt_template.invoke({"product": "家庭用ロボット"})
print(type(output))
print(output)<class 'langchain_core.prompt_values.StringPromptValue'>
text='家庭用ロボットを作る日本語の新会社名をを1つ提案してください'「Prompt Template」の入力は辞書、出力は「PromptValue」です。
「PromptValue」は、LLMとChatModelの入力となるクラスです。文字列(LLMの入力)にキャストするto_string()と、Messageリスト(ChatModelの入力)にキャストするto_messages()を持ちます。
5-3. Output Parser
「Output Parser」 は、「Language Model」の出力を用途にあわせて変換するモジュールです。
主な用途は次のとおりです。
・Language Modelの出力 → プレーンテキスト
・Language Modelの出力 → 構造化データ (JSONなど)
・Language Modelの出力 → メッセージ以外の情報 (OpenAI Functionsなど)
今回は、「StrOutputParser」でMessageリストをプレーンテキストに変換します。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import AIMessage
# Output Parserの準備
output_parser = StrOutputParser()
# Output Parserの実行
message = AIMessage(content="AIからのメッセージです")
output = output_parser.invoke(message)
print(type(output))
print(output)<class 'str'>
AIからのメッセージです「StrOutputParser」の入力は「Language Model」の出力 (文字列またはMessageリスト)、出力は文字列になります。
提供されている「OutputParser」は、次のとおりです。
・CSV parser
・Datetime parser
・Enum parser
・JSON parser
・OpenAI Functions
・OpenAI Tools
・Output-fixing parser
・Pandas DataFrame Parser
・Pydantic parser
・Retry parser
・Structured output parser
・XML parser
・YAML parser
6. Chain
単純なアプリケーションであれば「LLM」や「ChatModel」の単独使用で問題ありませんが、それらモジュール (Runnable) をチェーンで繋げることで、複雑なアプリケーションを構築することができます。
Chainの実装方法には、次の2種類があります。
・LCEL (LangChain Expression Language) : 表記言語によるチェーン実装
・Chain Interface : クラスによるチェーン実装 (レガシー)
「LangChain」ではこのチェーンを「LCEL」(LangChain Expression Language)と呼ばれる表現言語で記述します。基本的な使い方は、モジュールを「|」で繋げるだけになります。
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# プロンプトテンプレートの準備
prompt_template = PromptTemplate(
input_variables=["product"],
template="{product}を作る日本語の新会社名を1つ提案してください",
)
# ChatModelの準備
chat_model = ChatOpenAI(temperature=0.9)
# OutputParserの準備
output_parser = StrOutputParser()
# チェーンをつなげて実行
chain = prompt_template | chat_model | output_parser
output = chain.invoke({"product": "家庭用ロボット"})
print(output)家庭ロボットテクノロジー株式会社7. Agent
7-1. Agentの概要
「Agent」は、ユーザーの要求に応じて、どの「Action」をどういう順番で実行するかを決定するモジュールです。「Chain」の機能の実行の順番はあらかじめ決まっていますが、「Agent」はユーザーの要求に応じてLLM自身が決定します。この「Agent」が「Action」で実行する特定の機能のことを「Tool」と呼びます。
・Agent : 実行するアクションと順番を決定
・Action : 次のアクションを実行 or ユーザーに応答
・Tool : アクションで実行される特定の機能
今回は例として、次の2つのToolを使うAgentを作成します。
・Tavily Tool (オンライン検索用)
・Retriever Tool (ローカル検索用)
7-2. Tavility Toolの準備
(1) パッケージのインストール。
「Tavily」のパッケージをインストールします。
# パッケージのインストール
!pip install tavily-python(2) 環境変数の準備。
左端の鍵アイコンで「TAVILY_API_KEY」を設定してからセルを実行してください。
import os
from google.colab import userdata
# 環境変数の準備 (左端の鍵アイコンでTAVILY_API_KEYを設定)
os.environ["TAVILY_API_KEY"] = userdata.get("TAVILY_API_KEY")(3) Tavilityツールの準備。
from langchain_community.tools.tavily_search import TavilySearchResults
# Tavilyの準備
tavily_tool = TavilySearchResults()
# 動作確認
tavily_tool.invoke("2024年夏の日本で一番人気のアニメは?")[
{
'url': 'https://dengekionline.com/article/202406/8973',
'content': '対抗となる作品は? 2024年夏アニメの放送前人気ランキングベスト10を発表 ... '
},
{
'url': 'https://dengekionline.com/article/202408/15557',
'content': '電撃オンラインで8月9日から8月18日にかけて実施した、2024年夏アニメの放送中人気ランキングの投票結果をお届けします ...'
},
{
'url': 'https://news.mynavi.jp/article/20240625-2968167/',
'content': 'Skyの関連記事はこちらから- PR - レポート 2024年夏アニメ、気になる作品ランキング - 圧倒的1位は『【推しの子】』、...'
},
{
'url': 'https://animeanime.jp/article/2024/07/29/85711.html',
'content': 'そこで今回は「2024年夏アニメ"いま"一番推せる作品は? 」 と題した読者アンケートを実施しました。...'
},
{
'url': 'https://filmarks.com/list-anime/release_year/2024/7',
'content': '2024年 夏放送・配信のおすすめアニメ。山﨑雄太監督の逃げ上手の若君や、大塚剛央出演の【推しの子】第2期、負けヒロインが多すぎる!などが含まれます。...'
}
]
7-3. Retriever Toolの準備
(1) パッケージのインストール。
ベクトルストア関連のパッケージをインストールします。
# パッケージのインストール
!pip install unstructured faiss-cpu(2) ドキュメントの準備。
今回は、マンガペディアの「ぼっち・ざ・ろっく!」のドキュメントを用意しました。
・bocchi.txt
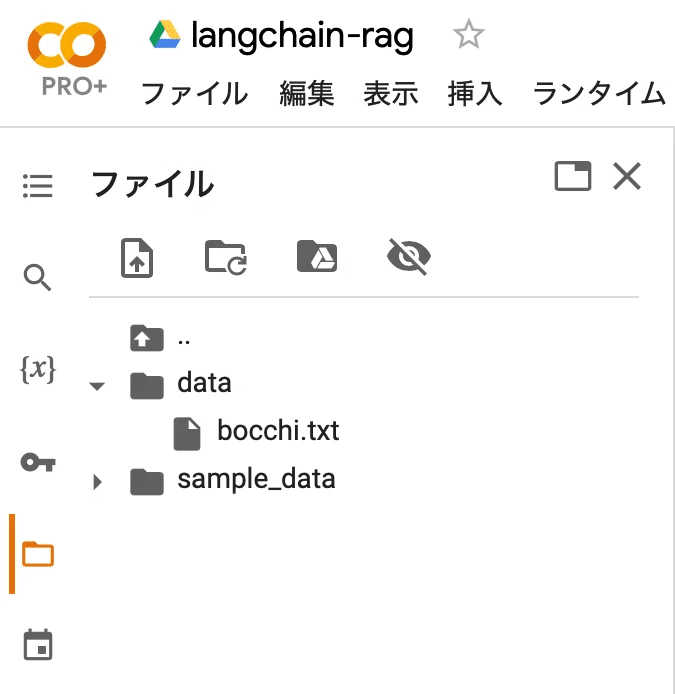
(3) Colabにdataフォルダを作成して配置。
(4) Retrieverの準備。
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
# ドキュメントの準備
loader = DirectoryLoader("./data/", glob="*.txt", loader_cls=TextLoader)
docs = loader.load()
docs = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
).split_documents(docs)
# ベクトルストアの準備
vector = FAISS.from_documents(docs, OpenAIEmbeddings())
# Retrieverの準備
retriever = vector.as_retriever()
# 動作確認
retriever.invoke("ぼっち・ざ・ろっくのぼっちちゃんの本名は?")[Document(page_content='後藤ひとり(ごとうひとり)\n\n秀華高校に通う女子。...', metadata={'source': 'data/bocchi.txt'}),
Document(page_content='長谷川あくび(はせがわあくび)\n\nメタルバンド...', metadata={'source': 'data/bocchi.txt'}),
Document(page_content='2号(にごう)\n\n美術大学の映像学科に在籍する女子。...', metadata={'source': 'data/bocchi.txt'}),
Document(page_content='山田リョウ(やまだりょう)\n\n下北沢高校に通う女子。...', metadata={'source': 'data/bocchi.txt'})](5) Retriever Toolの準備。
from langchain_core.tools.retriever import create_retriever_tool
# Retriever Toolの準備
retriever_tool = create_retriever_tool(
retriever,
"bocchi_search",
"ぼっち・ざ・ろっくに関する情報を検索します。ぼっち・ざ・ろっくに関する質問がある場合は、このツールを使用する必要があります。",
)7-4. Agentの準備
(1) Toolsの準備。
# Toolsの準備
tools = [tavily_tool, retriever_tool](2) ToolsとLLMの準備。
from langchain_openai import ChatOpenAI
# Toolsの準備
tools = [tavily_tool, retriever_tool]
# LLMの準備
llm = ChatOpenAI(temperature=0)(3) Agentの準備。
from langgraph.prebuilt import chat_agent_executor
# Agentの準備
agent_executor = chat_agent_executor.create_tool_calling_executor(
llm,
tools=tools
)(3) 動作確認1。
オンライン検索が必要な場合は、「Tavility Tool」が呼ばれます。
# 動作確認
response = agent_executor.invoke(
{"messages": [("human", "2024年夏の日本で一番人気のアニメは?")]}
)
response["messages"][-1].content2024年夏の日本で人気のアニメには、以下の作品が挙げられています:\n\n1. **推しの子**(第2期) - 人気の続編で、多くのファンに支持されています。\n2. **しかのこ** - プロモーションビデオが話題になっている作品です。\n3. **2.5次元の誘惑** - コスプレ青春ストーリーとして注目されています。\n4. **逃げ上手の若君** - 山﨑雄太監督による作品。\n5. **異世界スーサイド・スクワッド** - 永瀬アンナが出演する異世界もの。\n\nこれらの作品は、恋愛系や青春ものが特に人気を集めているようです。詳細なランキングや情報は、[こちらの記事](https://dengekionline.com/article/202406/8973)を参照してください。
(4) 動作確認2。
ローカル検索が必要な場合は、「Retriever Tool」が呼ばれます。
# 動作確認
response = agent_executor.invoke(
{"messages": [("human", "ぼっち・ざ・ろっくのぼっちちゃんの本名は?")]}
)
response["messages"][-1].contentぼっち・ざ・ろっくのぼっちちゃんの本名は「後藤ひとり(ごとうひとり)」です。彼女は秀華高校に通う女子で、引きこもり気味の性格を持っています。ギターの腕前はプロ級ですが、人と接するのが苦手で、友達を作るのに苦労しています。
8. Memory
これまでの「Chain」や「Agent」はステートレスでしたが、「Memory」を使うことで、「Chain」や「Agent」で過去の会話のやり取りを記憶することができます。過去の会話の記憶を使って、会話することができます。
Agentに「Memory」を追加する手順は、次のとおりです。
(1) Memoryの準備。
from langgraph.checkpoint.memory import MemorySaver
# Memoryの準備
memory = MemorySaver()(2) Memory付きAgentの準備。
# Memory付きAgentの準備
agent_executor = chat_agent_executor.create_tool_calling_executor(
llm,
tools=tools,
checkpointer=memory
)(3) コンフィグの準備。
# コンフィグの準備
config = {"configurable": {"thread_id": "abc123"}}(2) 動作確認1。
# 動作確認
response = agent_executor.invoke(
{"messages": [("human", "ぼっち・ざ・ろっくのぼっちちゃんの本名は?")]},
config=config
)
response["messages"][-1].contentぼっち・ざ・ろっくのぼっちちゃんの本名は後藤ひとり(ごとうひとり)です。
(3) 動作確認2。
過去の会話内容を覚えていることがわかります。
# 動作確認
response = agent_executor.invoke(
{"messages": [("human", "性格は?")]},
config=config
)
response["messages"][-1].content後藤ひとり(ぼっちちゃん)は自他共に認める引きこもり一歩手前の「陰キャ」で、承認欲求が人一倍強いにもかかわらず、臆病な性格で人と接するのを極度に苦手としています。彼女は情緒不安定で、すぐに自分の世界に入って落ち込む傾向があります。また、運動も勉強も苦手で、生来の要領の悪さから赤点ギリギリとなることもあります。しかし、ギターの腕前はプロ級であり、音楽に対する情熱と才能を持っています。