
LangChain への OpenAIのRAG戦略の適用

以下の記事が面白かったので、かるくまとめました。
1. はじめに
「Open AI」はデモデーで一連のRAG実験を報告しました。評価指標はアプリケーションによって異なりますが、何が機能し、何が機能しなかったかを確認するのは興味深いことです。以下では、各手法を説明し、それぞれを自分で実装する方法を示します。アプリケーションでのこれらの方法を理解する能力は非常に重要です。問題が異なれば異なる検索手法が必要となるため、「万能の」解決策は存在しません。

2. RAG スタックにどのように適合するか
まず、各手法をいくつかの「RAGカテゴリ」に分類します。以下は、カテゴリ内の各RAG実験を示し、RAGスタックに配置する図です。

3. ベースライン
距離ベースのベクトルデータベース検索は、クエリを高次元空間に埋め込み(表現)し、「距離」に基づいて類似の埋め込み文書を見つけます。OpenAIの研究で使用されたベースケースの検索方法では、コサイン類似性について言及しました。「LangChain」には60以上のベクトルストア統合があり、その多くは類似性検索で使用される距離関数を可能にします。さまざまな距離メトリクスに関する有用なブログ投稿は、Weaviate と Pinecone で見つけることができます。
4. クエリ変換
「クエリ変換」(Query Transformations) は、検索を改善するためにユーザー入力を変換することに重点を置いた一連のアプローチです。 このトピックに関する最近のブログはこちらを参照してください。
「OpenAI」は次の2つの方法を報告しました。
・Query expansion : LangChain の「Multi-query retriever」は、LLM を使用してクエリ拡張を実現し、特定のユーザー入力クエリに対してさまざまな観点から複数のクエリを生成します。クエリごとに、関連するドキュメントセットを取得し、すべてのクエリにわたる一意の結合を取得します。
・HyDE : LangChainの「HyDE」(Hypothetical Document Embeddings) retrieverは、受信クエリに対して仮説ドキュメントを生成し、埋め込み、検索に使用します (論文を参照)。これらのシミュレートされた文書は、質問よりも目的のソース文書との類似性が高い可能性があるという考えです。
考慮すべき他のアイデアは、次のとおりです。
・Step back prompting : この論文では、推論タスクの場合、ステップバックの質問を使用して、より高いレベルの概念または原則に基づいた答えの合成を行うことができることを示しています。たとえば、物理学に関する質問は、ユーザーのクエリの背後にある物理原理に関する質問と回答に抽象化できます。最終的な答えは、入力された質問とステップバックの答えから導き出すことができます。詳しくは、このブログ投稿またはLangChain実装を参照してください。
・Rewrite-Retrieve-Read : この論文では、検索を改善するためにユーザーの質問を書き直しています。 詳細しくは、LangChain実装を参照してください。
5. ルーティング
複数のデータストアにわたってクエリを実行する場合、質問を適切なソースにルーティングすることが重要になります。「OpenAI」のプレゼンテーションでは、2 つのベクトルストアと1つのSQLデータベースの間で質問をルーティングする必要があると報告されました。LangChainは、LLM を使用してユーザー入力を一連の定義されたサブチェーン (この場合のように、異なるベクトルストアである可能性があります) にゲートするルーティングをサポートしています。
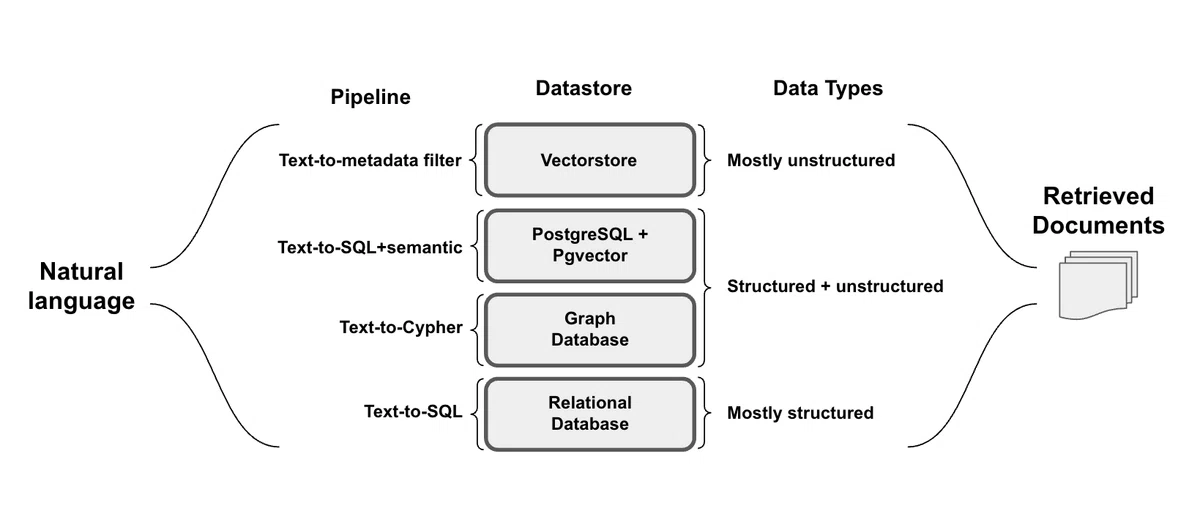
6. クエリの構築
「OpenAI」の調査で言及されているデータソースの1つはリレーショナル (SQL) データベースであるため、必要な情報を抽出するにはユーザー入力から有効な SQLを生成する必要がありました。LangChainはtext-to-sqlをサポートしています。これについては、クエリ構築に焦点を当てた最近のブログで詳しくレビューしています。
考慮すべき他のアイデアは、次のとおりです。
・Text-to-metadata filter (ベクトルストア)
・Text-to-Cypher (グラフデータベース)
・Text-to-SQL+semantic (Postgres with Pgvectorの半構造化データ)
7. インデックスの構築
「OpenAI」は、ドキュメントの埋め込み中にチャンクサイズを実験するだけで、パフォーマンスが大幅に向上したと報告しました。これはインデックス構築の中心的なステップであるため、チャンクサイズをテストできるオープンソースの Streamlitアプリがあります。

ファインチューニングの埋め込みによるパフォーマンスの大幅な向上は報告されていませんが、良好な結果は報告されています。「OpenAI」は、これはおそらく「簡単にできる成果」として推奨されないと述べていますが、ファインチューニングのためのガイドを共有しており、これについて詳しく説明した HuggingFace の非常に優れたチュートリアルがいくつかあります。
8. 後処理
取得後、LLM取り込みの前にドキュメントを処理することは、多くのアプリケーションにとって重要な戦略です。後処理を使用して、取得したドキュメントの多様性や最新性を強制できます。これは、複数のソースからドキュメントをプールする場合に特に重要になります。
「OpenAI」は次の2つの方法を報告しました。
・Re-rank : LangChain と Cohere ReRankの統合は1つのアプローチであり、大量のドキュメントを取得する場合のドキュメント圧縮 (冗長性の削減) に使用できます。これに関連して、「RAG-fusion」は相互ランクフュージョン (ブログと実装を参照) を使用して、multi-query (上で説明) と同様に、取得者から返されたドキュメントを ReRank します。
・Classification : OpenAI は、取得した各ドキュメントをその内容に基づいて分類し、分類に応じて異なるプロンプトを選択しました。これは 2 つのアイデアを結びつけます。LangChain は、分類のためのテキストのタグ付け (たとえば、関数呼び出しを使用して出力スキーマを強制する) をサポートします。前述したように、論理ルーティングを使用して、タグに基づいてルーティングすることもできます (または、論理ルーティングチェーン自体にセマンティック タグ付けのプロセスを含めることもできます)。
考慮すべき他のアイデアは、次のとおりです。
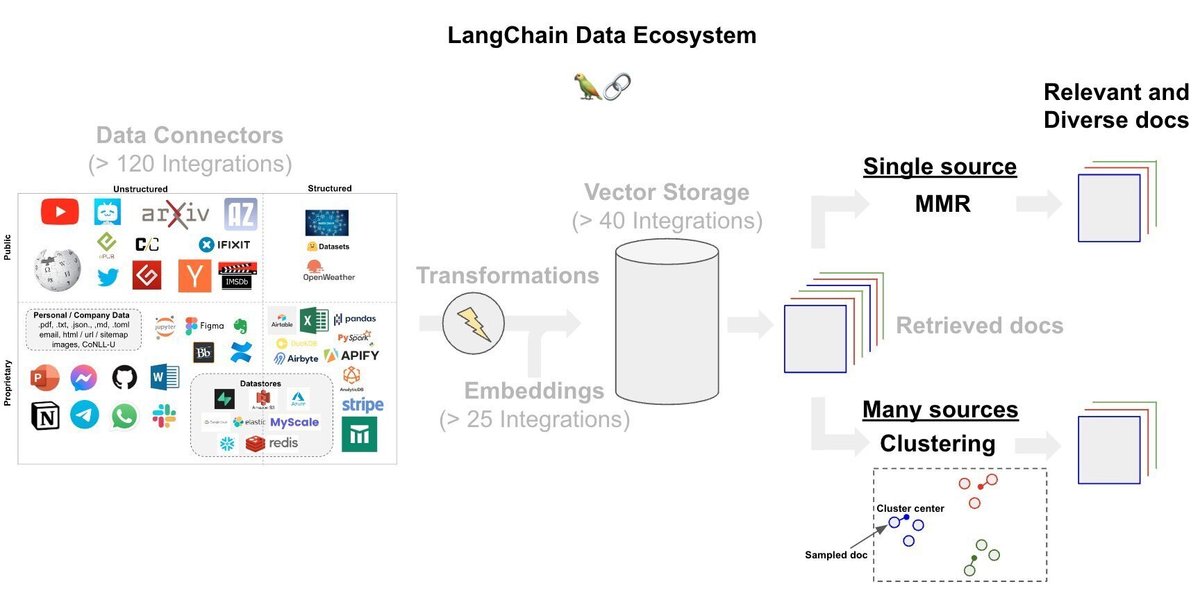
・MMR : 関連性と多様性のバランスをとるために、多くのベクトルストアはmax-marginal-relevance searchを提供しています (ブログ投稿を参照)。
・Clustering : 一部のアプローチでは、サンプリングによる埋め込みドキュメントのclusteringが使用されています。これは、広範囲のソースにわたるドキュメントを統合する場合に役立つ可能性があります。
この記事が気に入ったらサポートをしてみませんか?