NVIDIA Cosmos の概要

以下の記事が面白かったので、簡単にまとめました。
・Advancing Physical AI with NVIDIA Cosmos World Foundation Model Platform
1. NVIDIA Cosmos
ロボティクスや自律走行車が進化する中、物理的な世界での複雑な行動を認識、理解、実行できる自律機械を可能にする「Physical AI」の開発を加速させることが重要になっています。このシステムの中心には、物理状態を物理を考慮した動画でシミュレーションする「World Foundation Model」(WFM) があります。これにより、機械は正確な意思決定を行い、周囲とのシームレスな相互作用を実現します。
「NVIDIA Cosmos」は、「Physical AI」向けに「World Foundation Model」を大規模に構築するためのプラットフォームです。データキュレーション、学習、カスタマイズに至るまで、開発のあらゆる段階で活用できるオープンな「World Foundation Model」および「Tool」を提供しています。
「NVIDIA Cosmos」で提供されている機能は、次のとおりです。
・World Foundation Model
ロボティクスと自動運転向けに事前学習された基盤モデル。
・NVIDIA NeMo Curator
効率的なビデオデータキュレーションツール。
・Cosmos Tokenizer
効率的で忠実度の高いビデオトークン作成が可能なトークナイザー。
・NVIDIA NeMo
モデルの学習と最適化のためのフレームワーク
2. World Foundation Model
Cosmosの「World Foundation Model」は、9,000兆トークン、つまり自律走行、ロボティクス、合成環境、その他関連分野からの2,000万時間分のデータを使用して事前学習された大規模生成AIモデルです。これらのモデルは、環境や相互作用のリアルな合成動画を生成し、複雑なシステムの学習のためのスケーラブルな基盤を提供します。これにより、高度な行動を実行するヒューマノイドロボットのシミュレーションから、エンドツーエンドの自律走行モデルの開発に至るまで、さまざまな用途に対応できます。
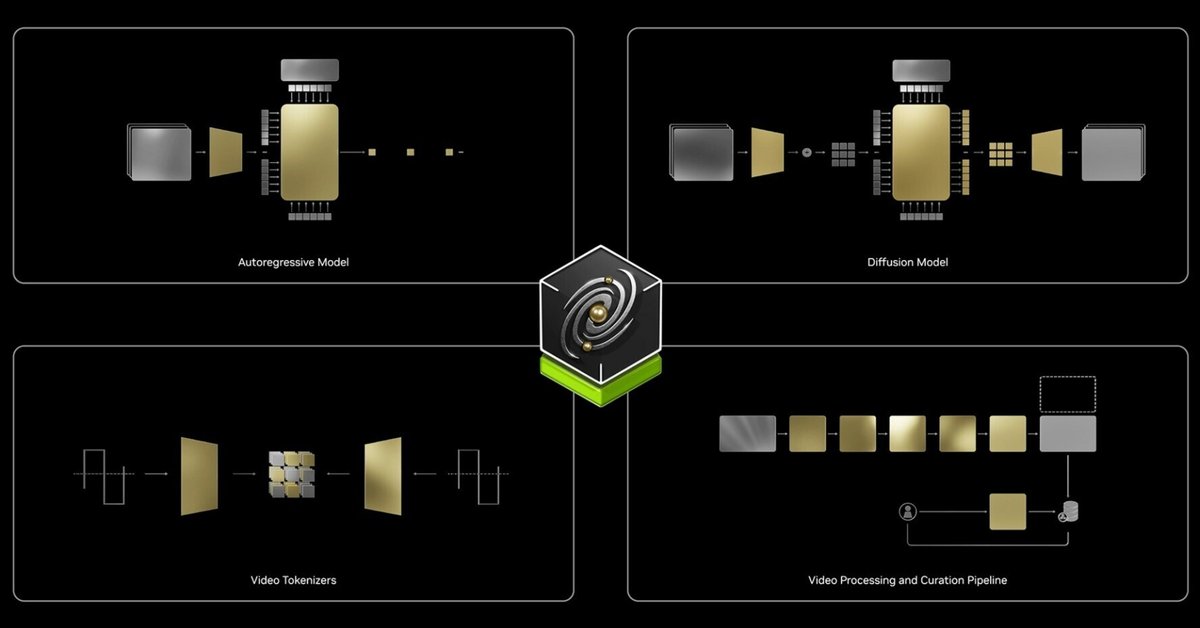
2-1. 自己回帰モデルと拡散モデル
これらモデルは、「自己回帰」と「拡散」の 2 つのアーキテクチャを使用します。。
・自己回帰モデル
「Cosmos」の「自己回帰モデル」はビデオ生成用に設計されており、入力テキストと過去のビデオフレームに基づいて次のトークンを予測します。transformer decoder アーキテクチャを使用し、World Model 開発用に重要な変更が加えられています。
・「3D RoPE」 (Rotary Position Embeddings) は、空間次元と時間次元を個別にエンコードし、正確なビデオ シーケンス表現を保証します。
・クロスアテンションレイヤーによりテキスト入力が可能になり、ワールド生成をより適切に制御できるようになります。
・QK 正規化により学習の安定性が向上します。
このモデルの事前学習は段階的に行われ、1つの入力フレームから最大17の将来のフレームを予測することから始まり、34フレーム、最終的には最大121フレーム (または 50,000 トークン) まで拡張されます。テキスト入力は説明とビデオフレームを組み合わせるために導入され、モデルは高品質のデータでファインチューニングされ、堅牢な性能を実現します。この構造化されたアプローチにより、モデルはテキスト入力の有無にかかわらず、さまざまな長さと複雑さのビデオを生成できます。

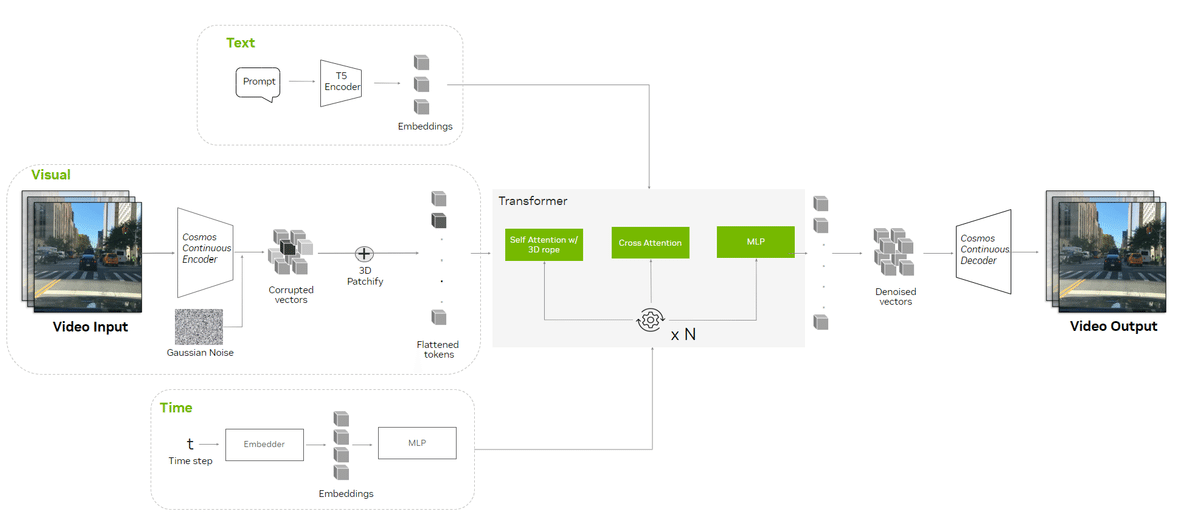
・拡散モデル
「Cosmos」の「拡散モデル」は、学習データを分解し、ユーザー入力に基づいて再構築して、高品質でリアルな出力を生成する機能があるため、画像、ビデオ、オーディオの生成によく使用されます。
拡散モデルは、次の2つのフェーズで動作します。
(1) 順方向拡散プロセス
学習データは、複数のステップにわたってガウスノイズを追加することによって徐々に破損し、実質的に純粋なノイズに変換されます。
(2) 逆拡散プロセス
モデルは段階的にこのノイズを逆転させることを学習し、破損した入力のノイズを除去して元のデータを回復します。
一度学習されると、拡散モデルはランダムなガウスノイズをサンプリングし、学習したノイズ除去プロセスに渡すことで新しいデータを生成します。さらに、「Cosmos」の拡散モデルには、「Physical AI」に合わせて調整されたいくつかの重要なアップデートも施されています。
・3Dパッチ化はビデオをより小さなパッチに処理し、時空間シーケンスの表現を簡素化します。
・ハイブリッド位置埋め込みは空間的および時間的次元を処理し、さまざまな解像度とフレーム レートのビデオをサポートします。
・クロスアテンションレイヤーにはテキスト入力が組み込まれており、説明に基づいてビデオ生成をより適切に制御できます。
・LoRAを使用した適応レイヤー正規化により、モデルサイズが36%削減され、より少ないリソースで高い性能が維持されます。
2-2. モデルサイズ
開発者は、性能、品質、デプロイのニーズに合わせて、次の3つのモデルサイズから選択できます。
・Nano
リアルタイム、低遅延の推論とエッジ展開向けに最適化。
・Super
性能の高いベースライン モデルとして設計。
・Ultra
最高の品質と忠実度に重点を置き、カスタムモデルの作成に最適。
2-3. 長所と限界
「Cosmos」の「World Foundation Model」は、ロボティクスや自律走行車システムの学習に不可欠な、低解像度で現実世界に忠実な合成ビデオデータを生成します。芸術的なセンスはありませんが、その出力は物理的な世界を忠実に再現するため、物理的なAIモデルの学習における正確なオブジェクトの永続性と現実的なシナリオに最適です。
2-4. ガードレール
AIモデルには、ハルシネーションを軽減し、有害な出力を防ぎ、プライバシーを保護し、安全で制御された展開のための AI 標準に準拠することで信頼性を確保するための「ガードレール」が必要です。「Cosmos」は、信頼できるAIに対する NVIDIA の取り組みに沿ったカスタマイズ可能な2段階の「ガードレール」を通じて、「World Founcation Model」の安全な使用を保証します。
・Pre-guard
「Pre-guard」では、次の2つのレイヤーを使用して、テキストプロンプトベースの安全対策が実施されます。
・キーワードのブロック
ブロックリストチェッカーはプロンプトをスキャンして安全でないキーワードを探し、レマタイズを使用してバリエーションを検出し、英語以外の用語やスペルの誤りをブロックします。
・Aegis Guardrail
NVIDIAがファインチューニングした Aegis AIコンテンツセーフティモデルは、暴力、嫌がらせ、冒とくなどのカテゴリを含む、意味的に安全でないプロンプトを検出してブロックします。安全でないプロンプトはビデオ生成を停止し、エラー メッセージを返します。
・Post-guard
「Post-guard」では、次の方法で生成されたビデオの安全性を確保します。
・ビデオコンテンツ安全性分類器
マルチクラス分類器は、すべてのビデオ フレームの安全性を評価します。いずれかのフレームが安全でないとフラグ付けされると、ビデオ全体が拒否されます。
・顔ぼかしフィルター
生成されたビデオ内のすべての人間の顔は、プライバシーを保護し、年齢、性別、人種に基づく偏見を減らすために、RetinaFace モデルを使用してぼかされます。
NVIDIAの専門家は敵対的サンプルを使用して厳密にテストし、10,000 を超えるプロンプトとビデオのペアに注釈を付けて、システムを改良し、エッジケースに対処します。
3. World Foundation Model の評価
「Cosmos」のベンチマークは、「Physical AI」アプリケーションで現実世界の物理を正確かつ効率的にシミュレートする「World Foundation Model」の能力を評価する上で重要な役割を果たします。公開されているビデオ生成ベンチマークは、生成されたビデオの忠実度、時間的一貫性、速度に重点を置いていますが、「Cosmos」のベンチマークは、汎用モデルを評価するための新しい次元、つまり3D一貫性と物理的アライメントを追加し、ビデオが「Physical AI」に必要な精度に基づいて評価されるようにします。
3-1. 3D一貫性
オープンデータセットから厳選された500本のビデオのサブセットの静的シーンで「3D一貫性」をテストしました。動きに関連する複雑さを回避するために、ビデオを説明するテキストプロンプトを生成しました。ベースライン生成モデルである「VideoLDM」と比較しました。
・指標
・幾何学的一貫性
サンプソン誤差やカメラ姿勢推定成功率などの指標を使用して、エピポーラ幾何学制約を通じて評価されます。
・ビュー合成の一貫性
ピーク信号対雑音比 (PSNR)、構造類似性指数 (SSIM)、学習知覚画像パッチ類似性 (LPIPS) などのメトリックを通じて評価されます。これらのメトリックは、補間されたカメラ位置から合成されたビューの品質を測定します。
Sampson エラーが低く、成功率が高いほど、3D アライメントが優れていることを示します。同様に、PSNR と SSIM が高く、LPIPS が低いほど、品質が優れていることを示します。

・結果
「Cosmos」の「World Foundation Model」は、「3D一貫性」においてベースラインを上回り、幾何学的配置とカメラポーズの成功率も高くなっています。合成されたビューは現実世界の品質と一致しており、世界シミュレーターとしての有効性が確認されています。
3-2. 物理アライメント
「物理アライメント」では、Cosmos モデルが動き、重力、エネルギー ダイナミクスなどの現実世界の物理をどの程度シミュレートできるかをテストしました。「PhysX」と「Isaac Sim」を使用して、仮想環境における重力、衝突、トルク、慣性などの特性を評価するための8つの制御されたシナリオを設計しました。
・指標
・ピクセルレベルの指標
ピーク信号対雑音比 (PSNR) は、モデルの出力のピクセル値が参照ビデオとどの程度一致するかを測定します。値が高いほど、ノイズが少なく、精度が高いことを示します。構造類似性指標測定 (SSIM) は、生成されたフレームと実際のフレーム間の構造、輝度、コントラストの類似性を評価します。SSIM 値が高いほど、視覚的な忠実度が高くなります。
・機能レベルの指標
DreamSim は、両方のビデオから抽出された高レベルの特徴間の類似性を測定します。このアプローチでは、個々のピクセルではなくオブジェクトと動きに焦点を当てて、生成されたコンテンツの意味の一貫性を評価します。
・オブジェクトレベルの指標
Intersection-over-Union (IoU) は、ビデオ内の予測されたオブジェクト領域と実際のオブジェクト領域間の重なりを計算します。これは、シミュレーションを通じて特定のオブジェクトを追跡し、その動作が物理的な期待と一致することを確認する場合に特に役立ちます。
PSNR、SSIM、DreamSim、IoU が高いほど、物理的な調整が優れていることを示します。
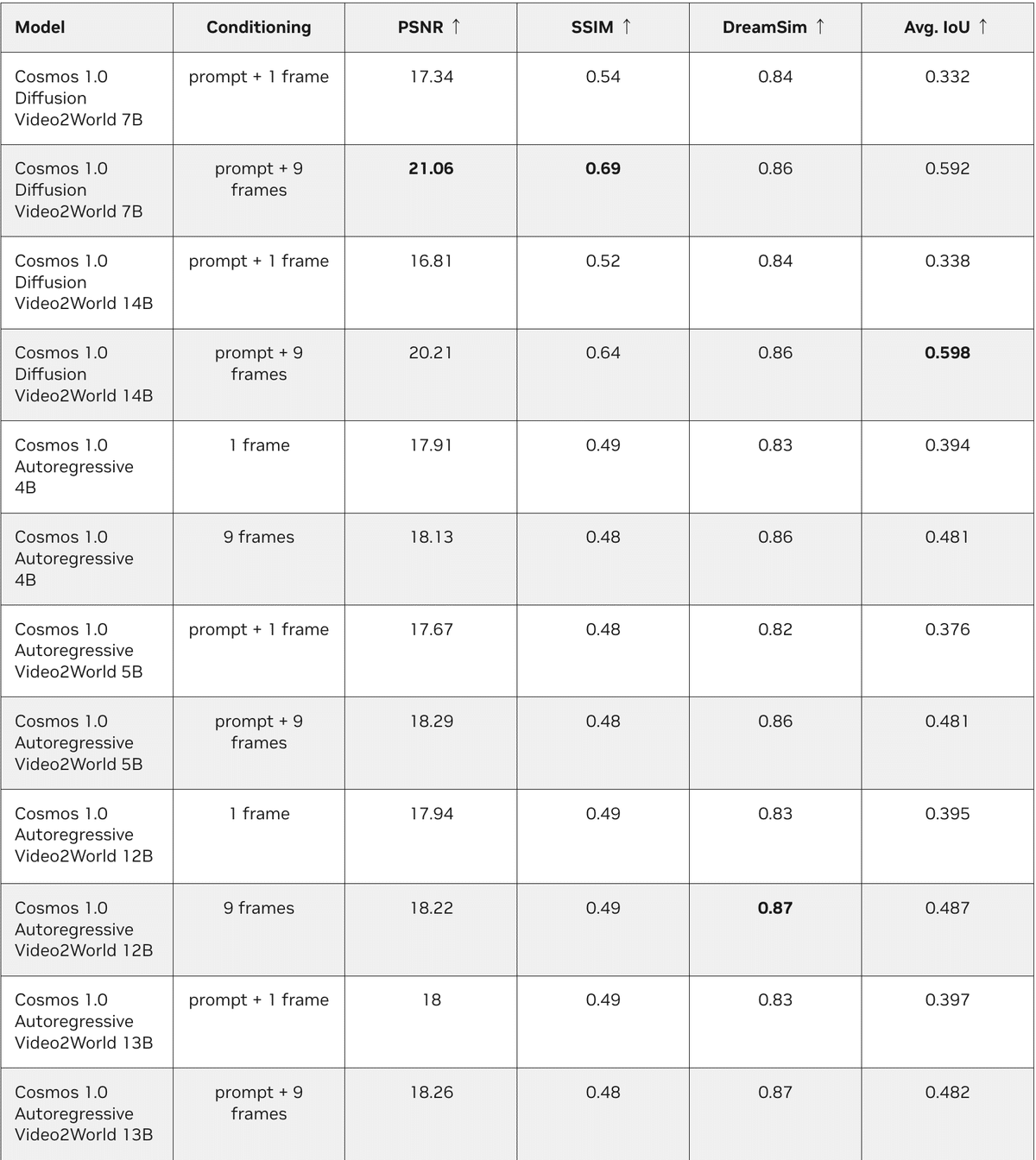
・結果
「Cosmos」の「World Founcation Model」は、特にコンディショニングデータの増加により、物理法則に強く準拠していることが示されています。カメラコンディショニングデータセットでの学習後、ベースラインモデルと比較してポーズ推定の成功率が 2 倍に向上しました。ただし、オブジェクトの非永続性 (オブジェクトが突然消えたり現れたりする) やあり得ない動作 (重力に違反するなど) などの課題は、改善の余地を浮き彫りにしています。
4. Cosmos と Omniverse による Physical AI のカスタマイズ
Cosmos と Omniverse による Physical AI のカスタマイズは、次の通りです。
(1) ビデオの検索と理解
空間的および時間的なパターンを理解することでビデオのタグ付けと検索を簡素化し、学習データの準備を容易にします。
(2) 制御可能な 3D からリアルへの合成データ生成
「Omniverse」を使用すると、開発者は3Dシナリオを作成し、「Cosmos」を使用して、高度にカスタマイズされた合成データセットの3Dシーンによって正確に制御されたフォトリアリスティックなビデオを生成できます。
(3) ポリシーモデルの開発と評価
アクション条件付きビデオ予測用に微調整された世界基盤モデルにより、ポリシーモデル (状態をアクションにマッピングする戦略) のスケーラブルで再現可能な評価が可能になり、障害物のナビゲーションやオブジェクトの操作などのタスクに対するリスクの高い現実世界のテストや複雑なシミュレーションへの依存が軽減されます。
(4) アクション選択のための先見性
「Cosmos」は、潜在的なアクションの結果を評価するための予測機能を物理 AI モデルに装備します。
(5) マルチバースシミュレーション
「Cosmos」と「Omniverse」を使用すると、開発者は複数の将来の結果をシミュレートして、AIモデルが目標を達成するための最善の戦略を評価および選択できるようにし、予測メンテナンスや自律的な意思決定などのアプリケーションに役立ちます。
「Cosmos」は、「World Model」の学習に2段階のアプローチを導入します。
・ジェネラリストモデル
「Cosmos」の「World Foundation Model」はジェネラリストとして構築されており、さまざまな現実世界の物理と環境を網羅する広範なデータセットで学習されています。これらのオープンモデルは、自然のダイナミクスからロボットの相互作用まで、幅広いシナリオに対応でき、あらゆる物理的なAIタスクに強固な基盤を提供します。
・スペシャリストモデル
開発者は、小規模でターゲットを絞ったデータセットを使用してジェネラリストモデルをファインチューニングし、自動運転やヒューマノイドロボットなどの特定のアプリケーションに合わせたスペシャリストモデルを作成したり、緊急車両のある夜景や高忠実度の産業用ロボット環境などのカスタマイズされた合成シナリオを生成したりできます。このファインチューニングプロセスにより、モデルをゼロから学習する場合と比較して、必要なデータとトレーニング時間が大幅に削減されます。
5. NVIDIA NeMo Curator
モデルの学習には、キュレーションされた高品質のデータが必要であり、これには多くの時間とリソースが必要です。「Cosmos」には、「NVIDIA NeMo Curator」を搭載し、NVIDIAデータセンター GPU 向けに最適化されたデータ処理およびキュレーションパイプラインが含まれています。
「NVIDIA NeMo Curator」を使用すると、ロボットや AV の開発者は膨大なデータセットを効率的に処理できます。たとえば、2,000 万時間分のビデオを「NVIDIA Hopper GPU」では 40 日で処理できますが、「NVIDIA Blackwell GPU」ではわずか 14 日で処理できます。一方、最適化されていないCPUパイプラインでは 3.4 年かかります。
主な利点は次のとおりです。
・キュレーションが89倍高速化
処理時間を大幅に短縮。
・スケーラビリティ
100 PB 以上のデータをシームレスに処理。
・高スループット
高度なフィルタリング、キャプション、埋め込みにより、速度を犠牲にすることなく品質を確保。
6. Cosmos Tokenizer
データがキュレートされたら、学習のためにトークン化する必要があります。トークン化により、複雑なデータが管理可能な単位に分割され、モデルがより効率的にデータを処理し、学習できるようになります。
「Cosmos Tokenizer」は、品質を維持しながら高速圧縮と視覚的再構築によってこのプロセスを簡素化し、コストと複雑さを軽減します。自己回帰モデルの場合、離散トークナイザーはデータを時間で8倍、空間で16×16に圧縮し、一度に最大49フレームを処理します。拡散モデルの場合、連続トークナイザーは時間で8倍、空間で8×8の圧縮を実現し、最大121フレームを処理します。
7. NVIDIA NeMo
開発者は、「NVIDIA NeMo」を使用して「Cosmos」の「World Foundation Model」をファインチューニングできます。「NeMo」は、オンプレミスのデータセンターからクラウドまで、既存のモデルを強化する場合でも、新しいモデルを構築する場合でも、GPU搭載システムでのモデルの学習を高速化します。
「NeMo」は、次の方法でマルチモーダル データを効率的に読み込みます。
・テラバイト規模のデータセットを圧縮ファイルに分割して、IO オーバーヘッドを削減。
・繰り返しを回避し、計算の無駄を最小限に抑えるために、データセットを確定的に保存および読み込む。
・最適化された通信を使用してデータを交換する際のネットワーク帯域幅を削減。
8. おわりに
「World Foundation Model」はオープンで、「NGC」および「Hugging Face」で入手できます。開発者は、「NVIDIA API カタログ」で 「Cosmos」の「World Founcation Model」を実行することもできます。「APIカタログ」では、テキストプロンプトの精度を高める「Cosmos」ツール、組み込みの透かしシステム、拡張現実アプリケーション用のビデオシーケンスをデコードする専用モデルも入手できます。
「NeMo Curator」は、マネージド サービスおよび SDK として利用できます。開発者は、早期アクセスを申請できます。
「Cosmos Tokenizer」は、 「GitHub」および「Hugging Face」で利用できるオープンニューラル ネットワークです。