LangChain のユースケース

「LangChain」 のユースケースをまとめました。
1. RAGのQA
「RAGのQA」は、RAG技術を使用して、特定の情報源に関する質問に回答するチャットボットを構築します。RAGは、ユーザーの質問に応じて適切な情報を検索し、それをLLMのプロンプトに組み込むことで、LLMの知識を強化します。具体的には、ドキュメントと読み込み、チャンクに分割して、インデックスを作成した後、ユーザーの入力に基づいて関連するデータを検索し、回答を生成します。


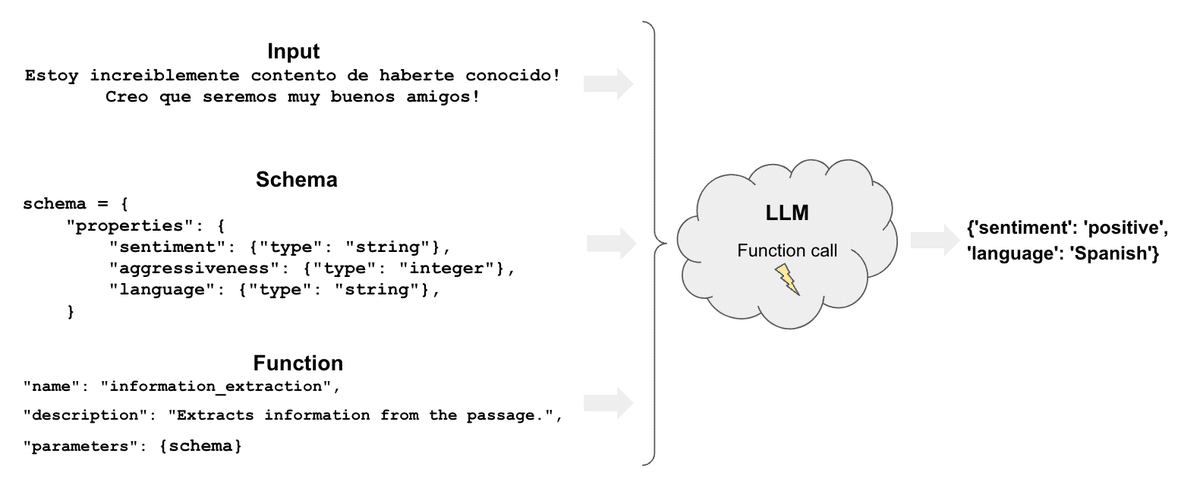
2. 情報抽出
「情報抽出」は、LLMでテキストから構造化データを抽出するユースケースです。次の3つのアプローチがあります。
・Tool Callingモード : Tool Callingで指定されたスキーマに従って、構造化データを出力
・JSONモード : プロンプトの一部としてスキーマを提供し、JSONデータを出力
・プロンプトベース : 指示に従って生成されたテキストを既存のパーサーで解析し、構造化データを出力
3. チャットボット
「チャットボット」は、長期的な対話を維持し、ユーザーの質問に関連情報を使用して回答する能力を持ちます。主な機能には、記憶管理、外部データソースからの情報取得、他のシステムやAPIとの連携があります。特定のドメインに関する質問に対してより適切な回答を提供するために、RAG技術がよく使われます。

4. ツールエージェント
「ツールエージェント」は、自然言語インターフェースを通じてAPIや関数、データベースなどのツールを操作するシステムを構築します。
次の2つのアプローチがあります。
・チェーン : ツール使用の事前定義されたシーケンスを作成
・エージェント : ツールを繰り返し使用してタスクを自動的に実行


5. クエリ解析
「クエリ解析」は、ユーザーの質問を最適化して検索クエリを生成し、より正確な情報を取得することを目的としています。手法には、クエリの分解、クエリ拡張、仮想ドキュメントの埋め込み、クエリのルーティング、ステップバックプロンプティング、クエリの構造化などがあります。これにより、検索品質が向上し、ユーザーの質問に対する回答精度が高まります。

6. SQLデータベースのQA
「SQLデータベースQA」は、「SQLデータベース」を対象としたQ&Aシステムを構築します。具体的には、自然言語の質問に基づいてSQLクエリを生成し、その結果を使って質問に回答するチャットボットや、ユーザーが分析したいインサイトに基づいてカスタムダッシュボードを作成することが可能です。

7. グラフデータベースのQA
「グラフデータベースのQA」は、「グラフデータベース」を対象としたQ&Aシステムを構築します。具体的には、「Cypher」や「SparQL」などのグラフクエリ言語を使用し、自然言語の質問に基づいてクエリを生成し、データベースからの情報を取得して回答を生成するチャットボットやカスタムダッシュボードを作成します。対応するデータベースには「Neo4j」「Amazon Neptune」「Tigergraph」などがあります。

8. コード理解
「コード理解」は、ソースコードの分析を目的としています。具体的には、コードベースに関するQ&Aを行い、リファクタリングや改善の提案、コードのドキュメント化を支援します。手順としては、コードのロード、分割、埋め込み、ベクトルストアへの保存、そして質問に基づいた検索と回答生成を行います。

9. データ生成
「データ生成」は、人工的にデータを生成することで、機械学習モデルの学習やテストに役立てます。具体的なメリットには、プライバシー保護、データ拡張、コスト削減、規制遵守、迅速なプロトタイピングが含まれます。医療データなどを用いて、必要なデータスキーマとプロンプトテンプレートを定義し、LLMを使用してデータを生成します。
10. タグ付け
「タグ付け」は、ドキュメントに感情、言語、スタイル、トピック、政治的傾向などのクラスをラベル付けします。LLMを使用し、指定されたスキーマに基づいて、テキストからこれらの情報を抽出します。
11. 要約
「要約」は、長いドキュメントの内容を要約するためのシステムを構築します。複数のドキュメントや長文テキストを効率的に要約することが可能になります。これには、「Stuff」「Map-Reduce」「Refine」の3つの手法があります。

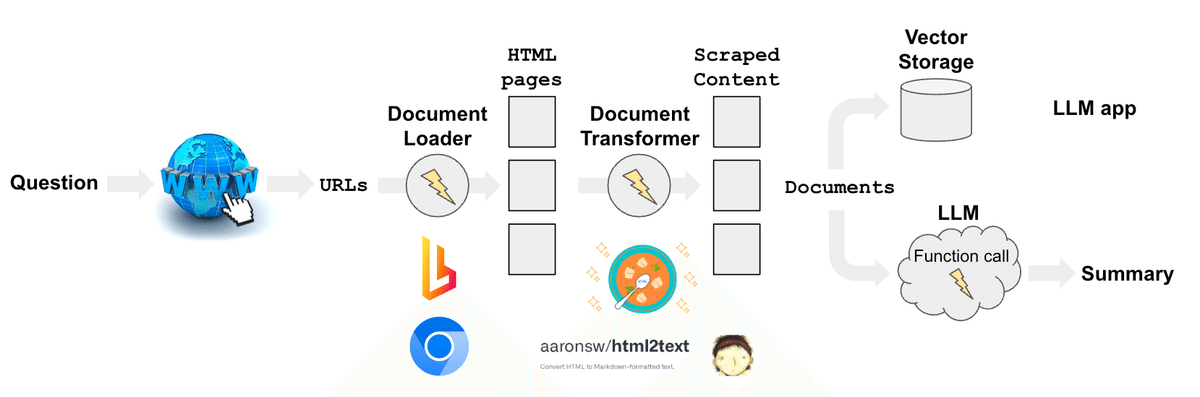
12. Webスクレイピング
「Webスクレイピング」は、Webからコンテンツを収集し、自然言語処理に使用するシステムを構築します。具体的には、検索クエリからURLを取得し、HTMLコンテンツをロードし、テキストを抽出するプロセスを含みます。「Playwright」や「BeautifulSoup」を使って、JavaScriptレンダリングや特定のタグからテキストを抽出し、データを構造化して分析や質問応答に活用します。