
Ragas で LangChainのRAG評価 を試す

「Ragas」でLangChainのRAG評価を試したので、まとめました。
・langchain v0.2.0
1. Ragas
「Ragas」は、「RAG」を評価するためのフレームワークです。
2. LangChainの準備
LangChainの準備手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install langchain==0.2.0
!pip install langchain-openai
!pip install langchain-chroma
!pip install langchain-community
!pip install unstructured(2) 左端の鍵アイコンで「OPENAI_API_KEY」に自分のOpenAI APIキーを設定してからセルを実行。
import os
from google.colab import userdata
# 環境変数の準備 (左端の鍵アイコンでOPENAI_API_KEYを設定)
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")3. ドキュメントの準備
ドキュメントの準備手順は、次のとおりです。
(1) ドキュメントの準備。
今回は、マンガペディアの「ぼっち・ざ・ろっく!」のあらすじのドキュメントを用意しました。
・bocchi.txt

(2) Colabにdataフォルダを作成してドキュメントを配置。
左端のフォルダアイコンでファイル一覧を表示し、右クリック「新しいフォルダ」でdataフォルダを作成し、ドキュメントをドラッグ&ドロップします。

4. RAGの作成
RAGの作成手順は、次のとおりです。
(1) LLMと埋め込みモデルの準備。
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
# LLMの準備
llm = ChatOpenAI(
model="gpt-4o", # モデル
temperature=0, # ランダムさ
)
# 埋め込みモデルの準備
embeddings = OpenAIEmbeddings()(2) ドキュメントの読み込みと分割。
from langchain.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# ドキュメントの読み込み
loader = DirectoryLoader("./data/")
documents = loader.load()
# ドキュメントの分割
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, # ドキュメントサイズ (トークン数)
chunk_overlap=0, # 前後でオーバーラップするサイズ
separators=["\n\n"] # セパレーター
).split_documents(documents)
print(len(documents))15(3) VectorStoreの準備。
from langchain_chroma import Chroma
# VectorStoreの準備
vectorstore = Chroma.from_documents(
documents,
embedding=embeddings,
)(4) Retrieverの準備。
# Retrieverの準備
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 2},
)(5) PromptTemplateの準備。
from langchain_core.prompts import ChatPromptTemplate
# PromptTemplateの準備
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "次のコンテキストのみを使用して、この質問に答えてください。\n\n{context}"),
("human", "{input}"),
]
)(6) RAGチェーンの準備。
from langchain_core.runnables import RunnablePassthrough
# RAGチェーンの準備
rag_chain = (
{"context": retriever, "input": RunnablePassthrough()}
| prompt_template
| llm
)(7) 質問応答。
# 質問応答
response = rag_chain.invoke("ギターヒーローの正体は?")
print(response.content)ギターヒーローの正体は後藤ひとりです。5. ソースつきのRAGの作成
次に、応答だけでなくソース (応答に使用したコンテキスト) も返すRAGを作成します。
(1) ソース付きRAGチェーンの準備
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# コンテキストのフォーマット
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Generationチェーンの準備
gemeration_chain = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt_template
| llm
| StrOutputParser()
)
# Retrieverチェーンの準備
retrieve_chain = (lambda x: x["input"]) | retriever
# ソース付きRAGチェーンの準備
rag_chain_with_source = RunnablePassthrough.assign(context=retrieve_chain).assign(
answer=gemeration_chain
)RunnablePassthrough.assign() は、ユーザー入力の辞書に特定のキー・バリューを割り当てます。
(2) 質問応答。
# 質問応答
rag_chain_with_source.invoke({"input": "ギターヒーローの正体は?"}){
'input': 'ギターヒーローの正体は?',
'context': [
Document(
page_content='ギターヒーロー:後藤ひとりが動画配信の際に用いるハンドルネーム。...',
metadata={'source': 'data/bocchi.txt'}
),
Document(
page_content='後藤ひとり(ごとうひとり):秀華高校に通う女子。...',
metadata={'source': 'data/bocchi.txt'}
)
],
'answer': 'ギターヒーローの正体は、後藤ひとりです。'
}6. RAGの評価
RAGの評価手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install ragas datasets(2) 質問・正解・コンテキスト・回答の準備。
今回は10セット用意しました。質問と正解のペアは独自に作成し、コンテキストと回答は、LangChainのRAGチェーンで生成します。
# 質問
question = [
"後藤ひとりの得意な楽器は?",
"後藤ひとりの妹の名前は?",
"後藤ひとりが加入したバンド名は?",
"ギターヒーローの正体は?",
"喜多郁代の髪の色は?",
"伊地知虹夏が通う学校の名前は?",
"山田リョウの趣味は?",
"廣井きくりが所属するバンド名は?",
"ライブハウス「STARRY」の店長の名前は?",
"ぼっちちゃんが文化祭で披露した演奏法は?",
]
# 正解
ground_truth = [
"ギター",
"後藤ふたり",
"結束バンド",
"後藤ひとり",
"赤",
"下北沢高校",
"廃墟探索と古着屋巡り",
"SICKHACK",
"伊地知星歌",
"ボトルネック奏法",
]
# コンテキストと回答の生成
contexts = []
answer = []
for q in question:
print("question:", q)
response = rag_chain_with_source.invoke({"input": q})
contexts.append([x.page_content for x in response["context"]])
answer.append(response["answer"])
print("contexts:", contexts)
print("answer:", answer)context: [
[
'後藤ひとり(ごとうひとり):秀華高校に通う女子。...',
'佐藤愛子(さとうあいこ):フリーライターとして活動する女性。...'
],
:
]
answer [
'後藤ひとりの得意な楽器はギターです。彼女は中学時代からギターを始め、毎日練習した結果、プロ級の腕前を持っています。',
'後藤ひとりの妹の名前は「後藤ふたり」です。',
'後藤ひとりが加入したバンド名は「結束バンド」です。',
'ギターヒーローの正体は、後藤ひとりです。',
'喜多郁代の髪の色は赤いです。',
'伊地知虹夏が通う学校の名前は「下北沢高校」です。',
'山田リョウの趣味は廃墟探索と古着屋巡りです。',
'廣井きくりが所属するバンド名は「SICKHACK(シックハック)」です。',
'ライブハウス「STARRY」の店長の名前は、伊地知星歌(いじちせいか)です。',
'ぼっちちゃん(後藤ひとり)が文化祭で披露した演奏法は、ボトルネック奏法です。'
](3) データセットの準備。
from datasets import Dataset
# データセットの準備
ds = Dataset.from_dict(
{
"question": question,
"answer": answer,
"contexts": contexts,
"ground_truth": ground_truth,
}
)(4) 評価の実行。
今回は、「faithfulness」「answer_relevancy」「context_precision」「context_recall」の4つのメトリックスを使いました。
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
# 評価の実行
result = evaluate(ds, [faithfulness, answer_relevancy, context_precision, context_recall])
print(result){'faithfulness': 0.5000, 'answer_relevancy': 0.9904, 'context_precision': 1.0000, 'context_recall': 1.0000}7. メトリックス
7-1. コンポーネントごとの評価
他の機械学習システムと同様に、LLMおよびRAGパイプライン内の個々のコンポーネントのパフォーマンスは、全体的なエクスペリエンスに大きな影響を与えます。「Ragas」は、RAGパイプラインの各コンポーネントを個別に評価するためのカスタマイズされたメトリックを提供します。
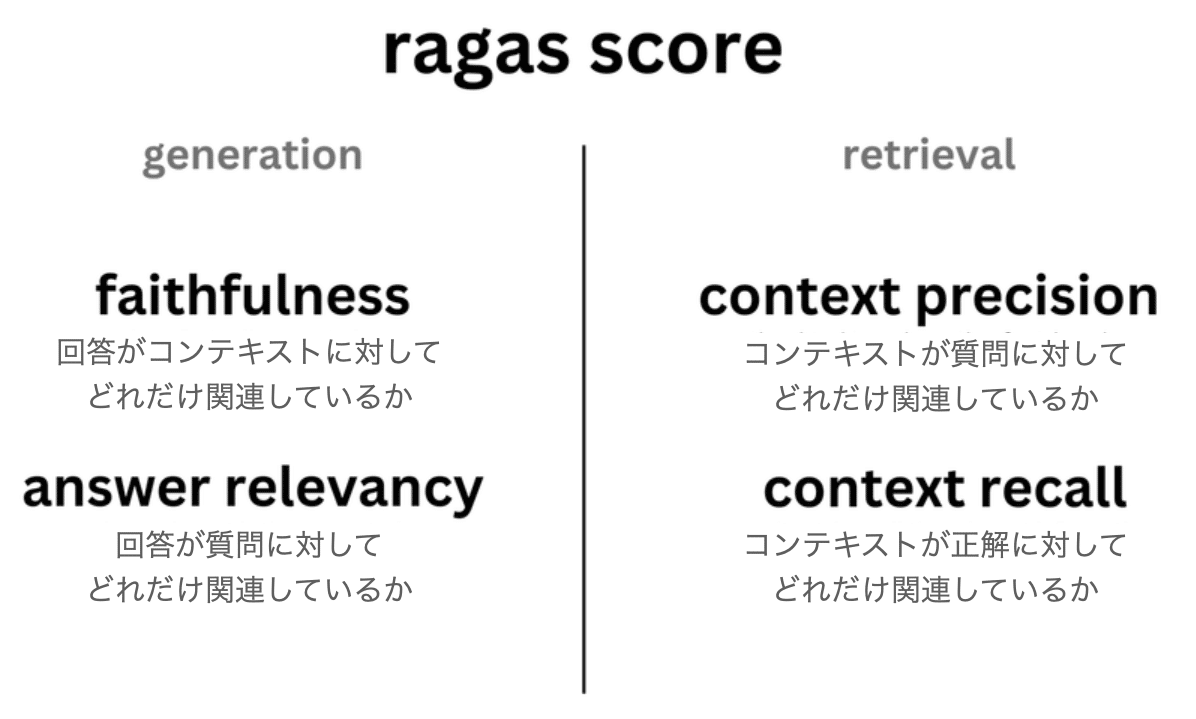
・Faithfulness
・Answer relevancy
・Context recall
・Context precision
・Context relevancy
・Context entity recall
7-2. エンドツーエンドの評価
パイプラインのエンドツーエンドのパフォーマンスを評価することも重要です。これはユーザーエクスペリエンスに直接影響するためです。「Ragas」は、パイプラインの全体的なパフォーマンスを評価するために使用できるメトリックを提供し、包括的な評価を保証します。
関連
この記事が気に入ったらサポートをしてみませんか?