
LangSmith クイックスタートガイド

「Google Colab」で「LangSmith」をはじめる方法をまとめました。
1. LangSmith
「LangSmith」は、LLMアプリケーションのデバッグ、テスト、監視のための統合プラットフォームです。
「LangChain」でLLMアプリケーションのプロトタイプを作成するのは簡単ですが、プロトタイプから本番まで持っていくのはまだまだ困難です。高品質の製品を作成するには、プロンプト、チェーン、その他のコンポーネントを大幅にカスタマイズして、反復する必要があります。このプロセスを支援するために、「LangSmith」は開発されました。
次のような場面で役立ちます。
・新しいチェーン、エージェント、ツールを迅速にデバッグ
・コンポーネント (チェーン、LLM、リトリバーなど) がどのように関係し、使用されるかを視覚化
・単一コンポーネントのさまざまなプロンプトとLLMを評価
・データセットに対して特定のチェーンを数回実行して、品質基準を常に満たしていることを確認
・使用状況をトレースし、LLMまたは分析パイプラインを使用して洞察を生成
2. APIキーの取得
「LangSmith」のサイトで「Waiting List」に登録して招待されるのを待ちます。
「LangSmith」が利用可能になったら、左下の「API Keys」ボタンからAPIキーを取得します。

3. トレースの実行
「LangSmith」のトレース機能の実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install langchain
!pip install openai
!pip install tiktoken
!pip install google-search-results # serpapiで使用(2) 環境変数の準備。
環境変数で、LangSmithのトレース機能を有効化できます。以下の<LangSmithのAPIキー>、<OpenAI_APIキー>、<SerpAPIキー>を自分のAPIキーに書き換えてください。
import os
from uuid import uuid4
# 環境変数の準備
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<LangSmithのAPIキー>"
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIキー>"
os.environ["SERPAPI_API_KEY"] = "<SerpAPIキー>"(3) エージェントの作成。
今回は、ツールとして検索と計算機にアクセスできるReActエージェントを作成します。
from langchain.chat_models import ChatOpenAI
from langchain.agents import AgentType, initialize_agent, load_tools
# エージェントの作成
llm = ChatOpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=False
)(4) エージェントの実行
待ち時間を短縮するために、複数の入力を使って復数のエージェントを同時実行しています。ログ送信はバックグラウンドで行われるため、実行速度は影響を受けません。
import asyncio
# 入力
inputs = [
"How many people live in canada as of 2023?",
"who is dua lipa's boyfriend? what is his age raised to the .43 power?",
"what is dua lipa's boyfriend age raised to the .43 power?",
"how far is it from paris to boston in miles",
"what was the total number of points scored in the 2023 super bowl? what is that number raised to the .23 power?",
"what was the total number of points scored in the 2023 super bowl raised to the .23 power?",
"how many more points were scored in the 2023 super bowl than in the 2022 super bowl?",
"what is 153 raised to .1312 power?",
"who is kendall jenner's boyfriend? what is his height (in inches) raised to .13 power?",
"what is 1213 divided by 4345?",
]
results = []
# 非同期関数
async def arun(agent, input_example):
try:
return await agent.arun(input_example)
except Exception as e:
return e
# 復数エージェントの同時実行
for input_example in inputs:
results.append(arun(agent, input_example))
results = await asyncio.gather(*results)【翻訳】
"2023年の時点でカナダに住んでいる人は何人ですか?",
"デュア・リパのボーイフレンドは誰ですか?彼の年齢を.43乗すると何になりますか?",
"デュア・リパのボーイフレンドの年齢を.43乗すると何になりますか?",
"パリからボストンまでの距離は何マイルですか",
"2023年のスーパーボウルで獲得された合計ポイント数は何ですか? その数値を 0.23 乗すると何になりますか?",
"2023年のスーパーボウルで獲得された合計ポイント数を .23 乗すると何になりますか?",
"2023年のスーパーボウルでは、2022年のスーパーボウルよりも何点多く得点されましたか?",
"153 の 0.1312 乗は何ですか?",
"ケンダル・ジェンナーのボーイフレンドは誰ですか? 彼の身長 (インチ) を 0.13 乗すると何ですか?",
"1213 を 4345 で割った値は何ですか?",
(5) LangSmithのダッシュボードでエージェントの実行結果を確認。
Projects内に新規プロジェクトが追加されています。

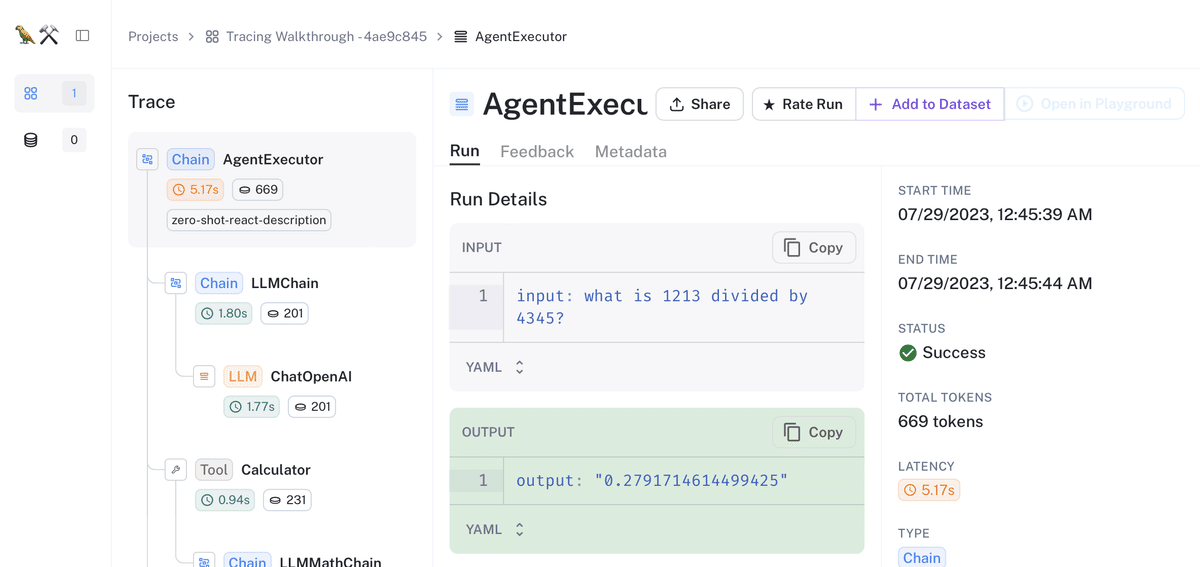
プロジェクトを選択すると、エージェントの実行結果を確認できます。

エージェントの実行結果を選択すると、トレース結果を確認できます。
4. 評価用のデータセットの作成
「LangSmith」の評価用のデータセットの作成手順は、次のとおりです。
(1) LangSmithクライアントの作成。
LangSmith APIと対話するためのクライアントになります。
from langsmith import Client
# LangSmithクライアントの作成
client = Client()(2) データセットの作成。
任意のプロジェクトのトレース入出力を取得し、それらをもとにデータセットを作成します。
# データセットの作成
dataset_name = f"calculator-example-dataset-{unique_id}"
dataset = client.create_dataset(
dataset_name,
description="計算機のサンプルデータセット"
)
runs = client.list_runs(
project_name=os.environ["LANGCHAIN_PROJECT"],
execution_order=1, # 最上位の実行のみ
error=False, # 成功した実行のみ
)
for run in runs:
client.create_example(
inputs=run.inputs,
outputs=run.outputs,
dataset_id=dataset.id
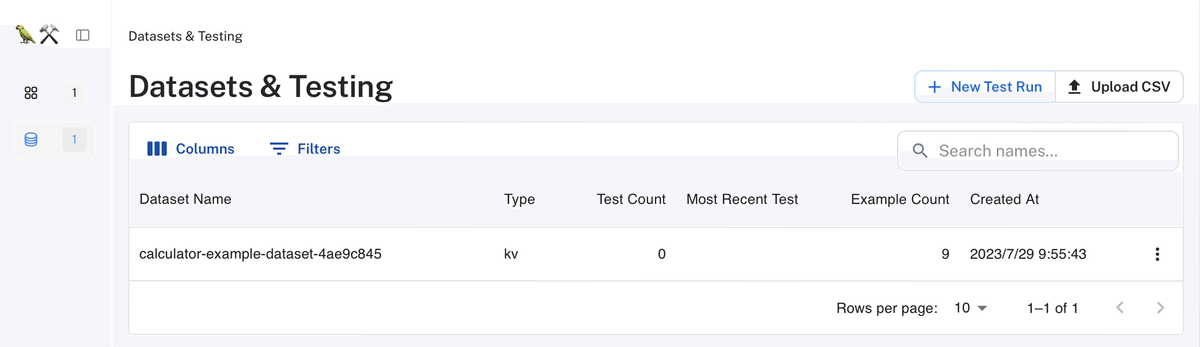
)(3) LangSmithのダッシュボードでデータセットを確認。
Datasets内に新規データセットが追加されています。
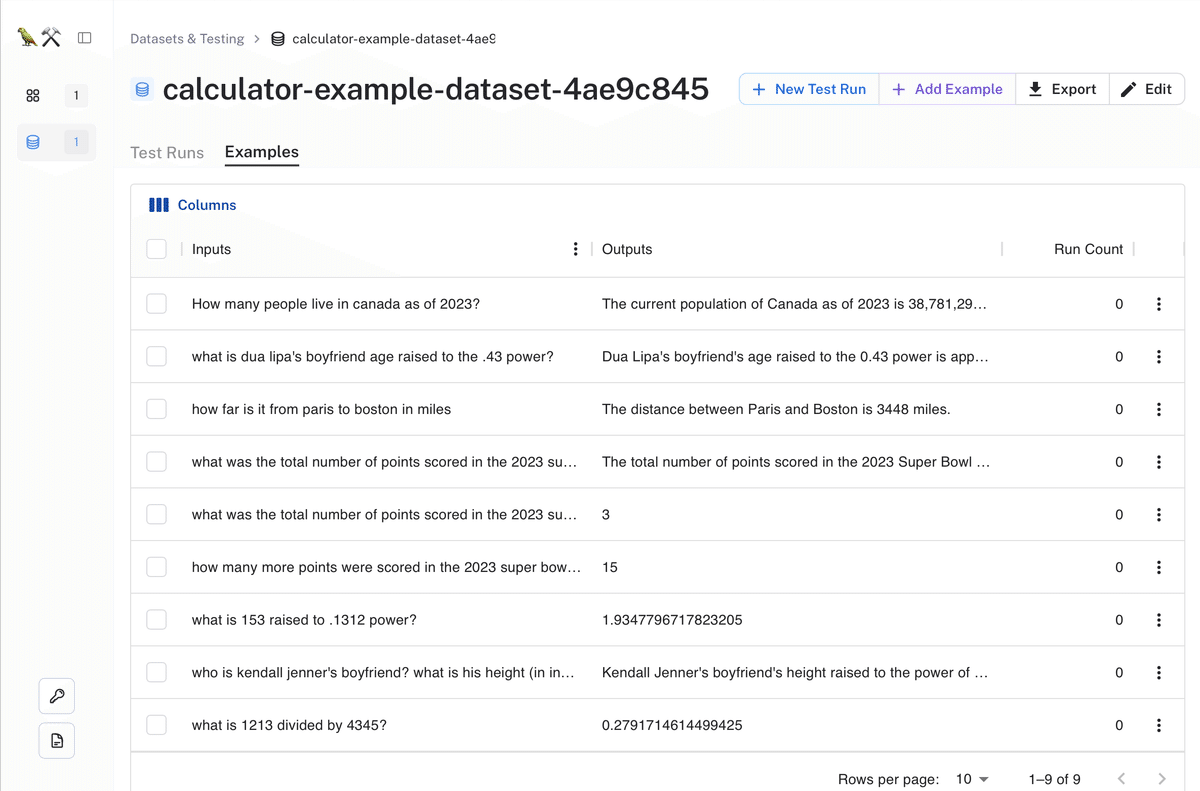
データセットを選択すると、データセットのデータを確認できます。
5. 評価の実行
「LangSmith」の評価の実行手順は、次のとおりです。
(1) 評価用のエージェントの作成
エージェントはステートフルである可能性があるため、評価毎に新しいエージェントを作成するファクトリ関数が必要になります。
from langchain.chat_models import ChatOpenAI
from langchain.agents import AgentType, initialize_agent, load_tools
# 評価用のエージェントの共用オブジェクト
llm = ChatOpenAI(model="gpt-3.5-turbo-0613", temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# 評価用のエージェントのファクトリ関数
def agent_factory():
return initialize_agent(
tools,
llm,
agent=AgentType.OPENAI_FUNCTIONS,
verbose=False
)(2) 評価コンフィグの作成。
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig
# 評価コンフィグの作成
evaluation_config = RunEvalConfig(
evaluators=[
EvaluatorType.QA,
EvaluatorType.EMBEDDING_DISTANCE,
RunEvalConfig.LabeledCriteria("helpfulness"),
RunEvalConfig.Criteria(
{
"fifth-grader-score": "Do you have to be smarter than a fifth grader to answer this question?"
}
),
],
custom_evaluators=[],
)(3) 評価の実行。
from langchain.smith import (
arun_on_dataset,
run_on_dataset,
)
# 評価の実行
chain_results = await arun_on_dataset(
client=client,
dataset_name=dataset_name,
llm_or_chain_factory=agent_factory,
evaluation=evaluation_config,
verbose=True,
tags=["testing-notebook"],
)(4) LangSmithのダッシュボードでエージェントの評価結果を確認。
Datasets内に新規のエージェントの評価結果が追加されています。
