
Genesis 入門 (9) - 強化学習 による移動ポリシーの学習

「Genesis」の「強化学習」による移動ポリシーの学習についてまとめました。
前回
1. 強化学習 による移動ポリシーの学習
「Genesis」は並列シミュレーションをサポートしており、「強化学習」(RL) で移動ポリシーを効率的に学習するのに最適です。今回は、「Unitree Go2」が歩行できるようにする基本的な移動ポリシーを取得するための完全な学習例を説明します。「Genesis」を使用すると、実世界で展開可能な移動ポリシーを26秒未満で学習できます (RTX 4090 でベンチマーク)。
このチュートリアルは、「Legged Gym」のいくつかの基本概念に触発され、それを基に構築されています。
2. 環境
Gymスタイルの環境を作成します。
2-1. 初期化
init() は、シミュレーション環境のセットアップを行います。
・制御周波数
シミュレーションは実際のロボットの制御周波数と同じ50Hzで実行します。sim2real のギャップをさらに埋めるため、実際のロボットに発生する行動遅延 (約20ミリ秒、1dt) も手動でシミュレートします。
・シーンの作成
ロボットと静的平面を含むシーンを作成します。
・PDコントローラのセットアップ
最初にモーターが名前に基づいて識別します。次に、各モーターの剛性と減衰が設定します。
・報酬の登録
ポリシーをガイドするために、コンフィグで定義された報酬関数を登録します。
・バッファの初期化
バッファは、環境の状態・観測・報酬を格納するために初期化します。
2-2. リセット
reset_idx()は、指定環境の初期ポーズと状態バッファをリセットします。これにより、ロボットが事前定義された構成から開始されることが保証され、一貫した学習に不可欠なものとなります。
2-3. ステップ
step()は、行動を受け取り、新しい観測値と報酬を返します。
・行動実行
入力された行動は切り取り、再スケールし、、デフォルトのモーター位置の上に追加します。目標関節位置を示す変換した行動は、1ステップ実行のためにロボットコントローラに送信します。
・状態更新
関節位置や速度などのロボット状態を取得し、バッファに保存します。
・終了チェック
環境は、「エピソード長が最大許容値を超える場合」、「ロボットのボディ方向が大幅に逸脱した場合」に終了します。終了した環境は自動的にリセットされます。
・報酬計算
・観測計算
学習に使用される観測には、基本角速度・投影された重力・命令・自由度位置・自由度速度・以前の行動が含まれます。
2-4. 報酬
報酬関数はポリシーガイダンスにとって重要です。
今回は、次のものを使用します。
・tracking_lin_vel : 直線速度命令の追従(xy軸)
・tracking_ang_vel : 角速度命令の追従(yaw)
・lin_vel_z : z軸方向の線形速度のペナルティ化
・action_rate : 行動の変化率のペナルティ化
・base_height : ベース高さが目標値から外れた場合のペナルティ化
・similar_to_default : 姿勢がデフォルトから大きく外れた場合のペナルティ化
3. 学習
「rsl-rl」での学習手順は、次のとおりです。
(1) パッケージのインストール。
git clone https://github.com/leggedrobotics/rsl_rl
cd rsl_rl && git checkout v1.0.2 && pip install -e .
cd ..
pip install tensorboard(2) 学習の実行。
python examples/locomotion/go2_train.py(3) 学習プロセスを「TensorBoard」で確認。
tensorboard --logdir logs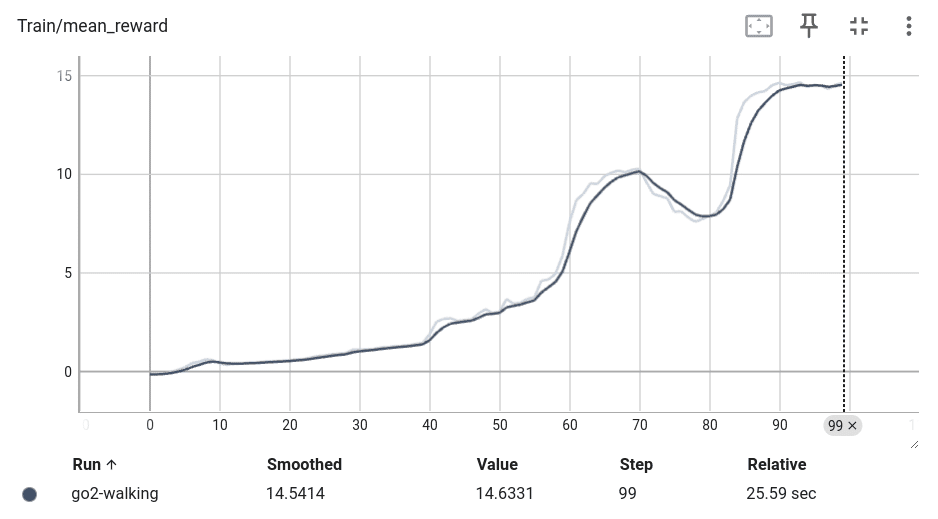
4. 評価
評価の実行手順は、次のとおりです。
(1) 評価の実行。
python examples/locomotion/go2_eval.py4足歩行ロボットが歩いてる様子を確認できます。
実際のロボットを持っている場合は、ポリシーを展開することもできます。
