
Nejumi LLMリーダーボード Neo の LLMベンチマークの使い方

この入門記事は、「Weights & Biases」のご支援により提供されています。Weights & Biases JapanのNoteでは他にも多くの有用な記事が掲載されていますので是非ご覧ください。

1. Nejumi LLMリーダーボード Neo
「Nejumi LLMリーダーボード Neo」は、日本語LLMの能力評価ランキングです。「llm-jp-eval」「MT-Bench」という2つのLLMベンチマークで評価します。

2. 評価項目
評価項目は、次のとおりです。
2-1. llm-jp-eval
「llm-jp-eval」は、一問一答形式の言語理解を評価するベンチマークです。12種類のデータセットを100問ずつ全1200問で正解・不正解 (0 or 1) を評価し、平均値を算出します。
・NLI (自然言語推論): Jamp(exact), JaNLI(exact), JNLI(exact), JSeM(exact), JSICK(exact)
・QA (質問応答): JEMHopQA(char f1), NIILC(char f1)
・RC (読解): JSQuAD (char f1)
・MC (多肢選択QA): JCommonsenseQA(exact)
・MR (数学的推理): MAWPS(exact)
・EL (エンティティリンク) : chABSA(set f1)
・FA (ファンダメンタル分析): Wikipedia Annotated Corpus (wiki_reading (char f1), wiki_ner(set f1), wiki_dependency(set f1), wiki_pas(set f1), wiki_coreference(set f1))
【例】
文章:梅雨 [SEP] 梅雨(つゆ、ばいう)は、北海道と小笠原諸島を除く日本、朝鮮半島南部、中国の南部から長江流域にかけての沿海部、および台湾など、東アジアの広範囲においてみられる特有の気象現象で、5月から7月にかけて来る曇りや雨の多い期間のこと。雨季の一種である。
質問:日本で梅雨がないのは北海道とどこか。2-2. MT-Bench
「MT-Bench」は、プロンプト対話形式でテキスト生成を評価するベンチマークです。8カテゴリを10問ずつ全80問を回答し、「GPT-4」がスコアリング (1〜10) し、平均値を算出します。
・coding (コーディング)
【例】
ディレクトリ内の全てのテキストファイルを読み込み、出現回数が最も多い上位5単語を返すPythonプログラムを開発してください。・extraction (情報抽出)
【例】
以下の映画のレビューを1から5のスケールで評価してください。1は非常に否定的、3は中立、5は非常に肯定的とします:
1. 2019年11月18日に公開されたこの映画は素晴らしい。撮影、演技、プロット、すべてが一流でした。
2. 映画にこんなに失望したことは今までにない。ストーリーは予測可能で、キャラクターは一次元的だった。私の意見では、この映画は2022年に公開された映画の中で最悪の一つだ。
3. 映画はまあまあだった。楽しめた部分もあったが、物足りないと感じた部分もあった。これは2018年2月に公開された、かなり平凡な映画のようだ。
答えを整数のJSON配列として返してください。:・humanities (人文科学)
【例】
経済成長率、消費者物価指数、失業率などの経済指標と日本銀行の金融政策との関係性を説明してください。その経済指標に影響を与える主な政策手段を示し、それぞれの効果について考察してください。・math (計算問題)
【例】
三角形の頂点が点 (0, 0)、(-1, 1)、(3, 3) にあるとき、その三角形の面積は何ですか?・resoning (推論)
【例】
あなたが人々と一緒にレースをしていると想像してみてください。あなたがちょうど2番目の人を追い越したとしたら、あなたの現在の位置は何番目でしょうか? あなたが追い越した人の位置はどこでしょうか?・roleplay (ロールプレイ)
【例】
あなたが宮崎駿であると思い込んで、可能な限り彼のように話してみてください。なぜ私たちはアニメが必要なのでしょうか?・stem (STEM)
【例】
量子物理学の中で、重ね合わせ状態とは何ですか?それはどのようにして量子もつれ現象と関連していますか?・writing (テキスト生成)
【例】
京都の四季をテーマにした詩を書いてください。各季節の美しさと過ぎゆく時間の感慨を表現してください。3. 評価コードの実行
今回は、Colabで人気のある日本語LLM「elyza/ELYZA-japanese-Llama-2-7b-fast-instruct」を評価します。「OpenAI API」の使用料金は $4ほど かかりました (生成する文章の長さに応じて変動するかと思います)。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
今回は、「Google Colab Pro/Pro+」で利用可能なA100を利用しています。
(2) パッケージのインストール。
「Nejumi LLMリーダーボード Neo」の評価コードは「wandb/llm-leaderboard」リポジトリで公開されています。
# パッケージのインストール
!git clone --recurse-submodules https://github.com/wandb/llm-leaderboard
%cd llm-leaderboard
!pip install -r requirements.txt(3) 環境変数の準備。
左端の鍵アイコンで「OPENAI_API_KEY」に自分のOpenAI APIキーを設定してからセルを実行してください。「MT-Bench」によるLLM出力の評価は「GPT-4」が行うため必要になります。
文字コードの設定も行なっています。

# 環境変数の準備 (左端の鍵アイコンでOPENAI_API_KEYを設定)
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
os.environ["PYTHONIOENCODING"] = "utf-8"
os.environ["LANG"] = "ja_JP.UTF-8"(4) 「configs」フォルダ直下に、設定ファイル「config.yaml」を準備して、設定項目を編集。
今回は、「llm-leaderboard」のwandbプロジェクトで公開されている「elyza/ELYZA-japanese-Llama-2-7b-fast-instruct」の「config.yaml」(v38)をベースにします。

「wandb: entity」に自分のwandbアカウントを指定し、「model: use_wandb_artifacts:」にfalseを指定してください。
wandb:
log: True
entity: "<wandbのアカウント>"
:
model:
:
use_wandb_artifacts: false
各項目について詳しくは、「5. config.yaml の設定項目」で説明します。
(5) LLMベンチマークのテスト実行。
「config.yaml」に「testmode: true」を設定して、LLMベンチマークをテスト実行します。本実行前に、テストモードで、少ないデータ数で最後まで実行できることを確認します。
# 評価コードの実行
!python scripts/run_eval.py次のような指示がでたら「2」を入力します。wandbのアカウントが必要です。

次のような指示がでたら、「wandbのAPIキー」を入力します。

完了したら、「View run」のリンクをクリックして結果を確認します。
完了まで11分ほどかかりました。


8つのテーブルが生成されています。
・leaderboard_table : リーダーボードテーブル
・jaster_leaderboard_table : llm-jp-evalのリーダーボードテーブル
・jaster_radar_table : llm-jp-evalのレーダーテーブル
・jaster_output_table : llm-jp-evalの出力テーブル
・jaster_output_table_dev : llm-jp-evalの出力テーブル(dev)
・mtbench_leaderboard_table : MT-Benchのリーダーボードテーブル
・mtbench_radar_table : MT-Benchのレーダーテーブル
・mtbench_output_table : MT-Benchの出力テーブル
(6) LLMベンチマークの実行。
「config.yaml」に「testmode: false」を設定して、LLMベンチマークをテスト実行します。完了したら、「View run」のリンクをクリックして結果を確認します。完了まで2時間ほどかかりました。
会話能力は「mtbench_radar_table」が参考になります。数学とコーディングが苦手であることがわかります。

4. 評価結果の比較
「Nejumi LLM リーダーボード Neo」のレポートを自分のwandbプロジェクトにコピーしてから、新規モデルの評価結果を追加します。
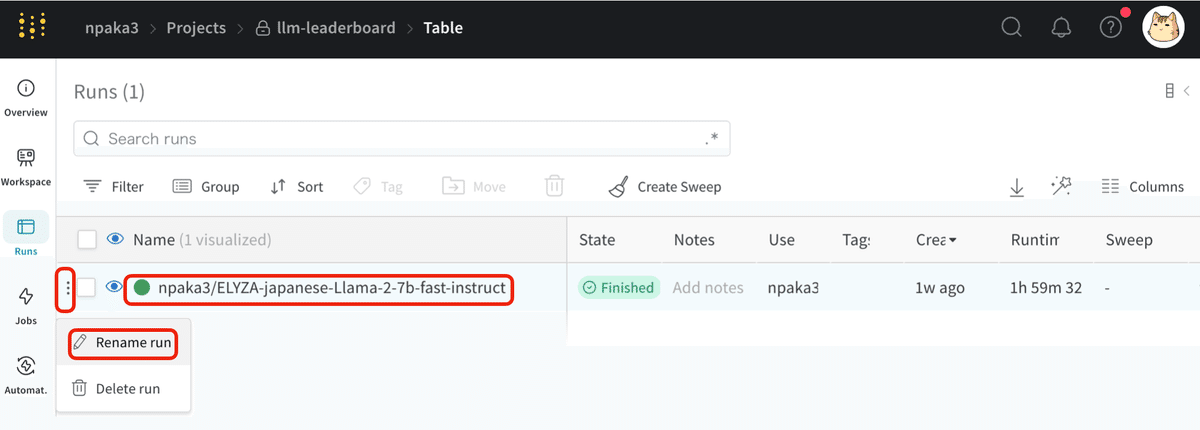
(1) 「左端のメニュー→ Rename run」でRun (評価結果) の名前を変更。
元のElyzaモデルと区別できるように、「elyza/」を「wandbのアカウント名/」に変更しています。
(2) 「Nejumi LLMリーダーボード Neo」のレポート を開き、「左上のメニュー → Make Copy」を選択。
wandbにログインしてない場合は、ログインしてから選択してください。

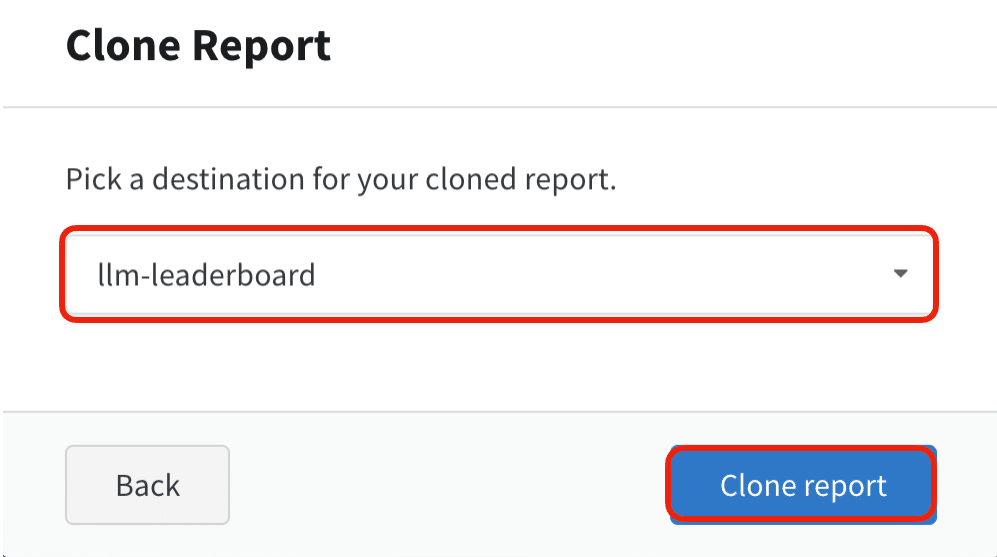
(3) コピー先のwandbプロジェクトを選択して「Clone repot」ボタンを押す。
(4) レポートが自分のwandbプロジェクトにコピーされてることを確認。

(5) 「総合評価」おわりのモデル一覧までスクロールし、「Model list」タブの左の「+」をクリック。
wandbプロジェクト内のRun一覧が表示される「Run set」タブが追加されます。

(6) 「Run set」タブ内からリーダーボードに追加したい「Run」を選択。
チェックと目を両方有効にします。

(7) リーダーボードに新規モデルが追加されていることを確認。
元のElyzaモデルとほぼ同じ位置にいることがわかります。

5. config.yaml の設定項目
「config.yaml」の設定項目は、次のとおりです。
5-1. 基本設定
・wandb: wandbに使用される情報
・entity: wandbのエンティティの名前 (wandbのユーザー名 or チーム名)
・project: wandbのプロジェクトの名前
・run_name: wandbのRunの名前
・github_version: githubバージョン (記録用)
・testmode: デフォルトはfalse。trueに設定すると、各カテゴリから1・2問のみのテストモードで実行
・api: APIを使用しない場合は「false」。使用する場合は「openai」「anthropic」「google」「cohere」から選択
・model: モデルの情報
・_target_: transformers.AutoModelForCausalLM.from_pretrained
・pretrained_model_name_or_path: モデルの名前
・trust_remote_code: デフォルトはtrue
・device_map: デバイスマップ。デフォルトはauto
・load_in_8bit: 8bit量子化。デフォルトはfalse
・load_in_4bit: 4bit量子化。デフォルトはfalse
・tokenizer: トークナイザーの情報
・pretrained_model_name_or_path: トークナイザーの名前
・use_fast: 高速トークナイザーの使用。デフォルトはtrue
・generator: 生成に関する設定。
・ top_p: top-p サンプリング。デフォルトは1.0
・top_k: top-k のサンプリング。デフォルトはコメントアウト
・temperature: サンプリングの温度。デフォルトはコメントアウト
・repetition_penalty: 反復ペナルティ。デフォルトは1.0
5-2. llm-jp-eval
・max_seq_length: 入力の最大長。デフォルトは2048
・dataset_artifact: 評価データセットのwandb アーティファクトの URL
・v1.0.0: "wandb-japan/llm-leaderboard/jaster:v0"
・v1.1.0: "wandb-japan/llm-leaderboard/jaster:v3"
・dataset_dir: 評価データセットの配置フォルダ
・target_dataset: 評価するデータセット。
{all, jamp, janli, jcommonsenseqa, jemhopqa, jnli, jsem, jsick, jsquad, jsts, niilc, chabsa}
・log_dir: ログの配置フォルダ。デフォルトは./logs
・torch_dtype: fp16、bf16、fp32の設定。デフォルトはbf16
・custom_prompt_template: カスタムプロンプトテンプレート。デフォルトはnull (Alpaca形式)
・custom_fewshots_template: カスタムFewShotテンプレート。デフォルトはnull (Alpaca形式)
・metainfo: メタ情報
・model_name: モデルの名前 (記録用)
・model_type: モデルのカテゴリ名 (記録用)
・struction_tuning_method: モデルのチューニング方法 (記録用)
・struction_tuning_data: モデルのチューニングデータ (記録用)
・num_few_shots: FewShotの数。デフォルトは0
・llm-jp-eval-version: llm-jp-evalのバージョン情報
5-3. MT-Bench
・mtbench: MT-Benchの情報
・question_artifacts_path: 評価データセットのwandb アーティファクトのURL
・referenceanswer_artifacts_path: 参照回答のwandbアーティファクトのURL
・judge_prompt_artifacts_path: Judgeプロンプトのwandb アーティファクトのURL
・bench_name: {japanese_mt_benct, mt_benct}
・japanese_mt_benct: 日本のデータセットを評価
・mt_benct: 英語のデータセットを評価
・model_id: モデルの名前
・max_new_token: 入力の最大長。デフォルトは1024
・num_gpus_per_model: モデルごとのGPUの数。デフォルトは1
・num_gpus_total: 合計GPUの数。デフォルトは1
・max_gpu_memory: GPUメモリの最大値。デフォルトはnull
・dtype: データ型。{None、float32、float16、bfloat16}
・judge_model: 評価に使用するモデル。デフォルトは「gpt-4」
・question_begin, question_end,mode, baseline_model, parallel, first_n: 元のFastChatのパラメータ。デフォルト値を使用
・custom_conv_template: trueの場合、カスタムconvテンプレートを使用。モデルがFastChat と互換性がない場合に役立つ。以降の変数で設定したカスタムconvテンプレートが使用される。デフォルトはfalse
具体的な例は、「llm-leaderboard」のwandbプロジェクトのArtifactで公開されている「config.yaml」を参照してください。
6. おわりに
「Nejumi LLMリーダーボード Neo」の「LLMベンチマーク」を使うことで、日本語LLMの能力評価を簡単に行うことができることを紹介しました。独自モデルを作成した際には、ぜひLLMベンチマークで評価してみてください。