Google Colab で Japanese InstructBLIP Alpha を試す

「Google Colab」で「Japanese InstructBLIP Alpha」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. Japanese InstructBLIP Alpha
「Japanese InstructBLIP Alpha」は、「Stability AI」が開発した日本語向け画像言語モデルです。画像から説明を生成できる画像キャプションに加え、画像についての質問応答も可能です。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install transformers accelerate bitsandbytes
!pip install sentencepiece einops(3) モデルとプロセッサーとトークナイザーの準備
from transformers import LlamaTokenizer, AutoModelForVision2Seq, BlipImageProcessor
# モデルとプロセッサーとトークナイザーの準備
model = AutoModelForVision2Seq.from_pretrained(
"stabilityai/japanese-instructblip-alpha",
trust_remote_code=True
).to("cuda")
processor = BlipImageProcessor.from_pretrained(
"stabilityai/japanese-instructblip-alpha"
)
tokenizer = LlamaTokenizer.from_pretrained(
"novelai/nerdstash-tokenizer-v1",
additional_special_tokens=['▁▁']
)(4) 画像の準備。
今回は、提供されているサンプル画像を使います。
from PIL import Image
import requests
# 画像の準備
url = "https://images.unsplash.com/photo-1582538885592-e70a5d7ab3d3?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=1770&q=80"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
image
(5) プロンプトの準備。
# プロンプトの準備
prompt = """以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。
### 指示:
与えられた画像について、詳細に述べてください。
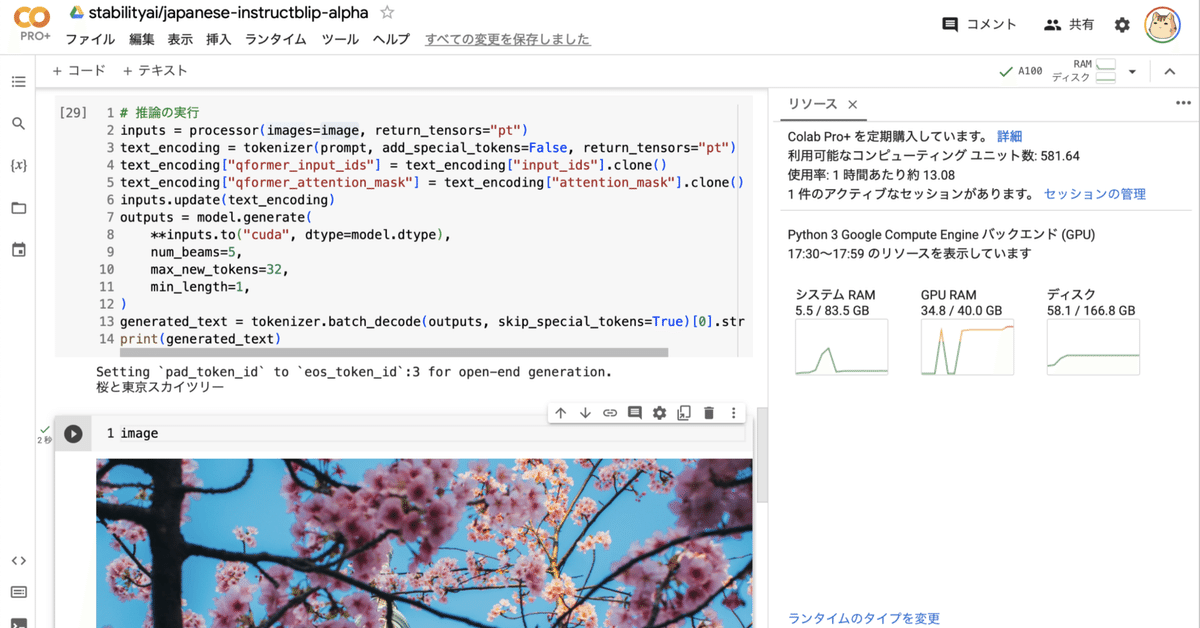
### 応答:"""(6) 推論の実行。
# 推論の実行
inputs = processor(images=image, return_tensors="pt")
text_encoding = tokenizer(prompt, add_special_tokens=False, return_tensors="pt")
text_encoding["qformer_input_ids"] = text_encoding["input_ids"].clone()
text_encoding["qformer_attention_mask"] = text_encoding["attention_mask"].clone()
inputs.update(text_encoding)
outputs = model.generate(
**inputs.to("cuda", dtype=model.dtype),
num_beams=5,
max_new_tokens=32,
min_length=1,
)
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0].strip()
print(generated_text)桜と東京スカイツリー