MediaPipe LLM Inference API による LLM のオンデバイス推論を試す

「MediaPipe LLM Inference API」による「LLM」のオンデバイス推論を試したので、まとめました。
1. MediaPipe LLM Inference API
「MediaPipe LLM Inference API」は、LLMをオンデバイスで実行するためのAPIです。現在は、実験リリースの段階です。
・サポートするプラットフォーム
・Web
・Android
・iOS
・サポートするモデル
・Gemma 2B
・Phi 2 2B
・Falcon 1B
・Stable LM 3B
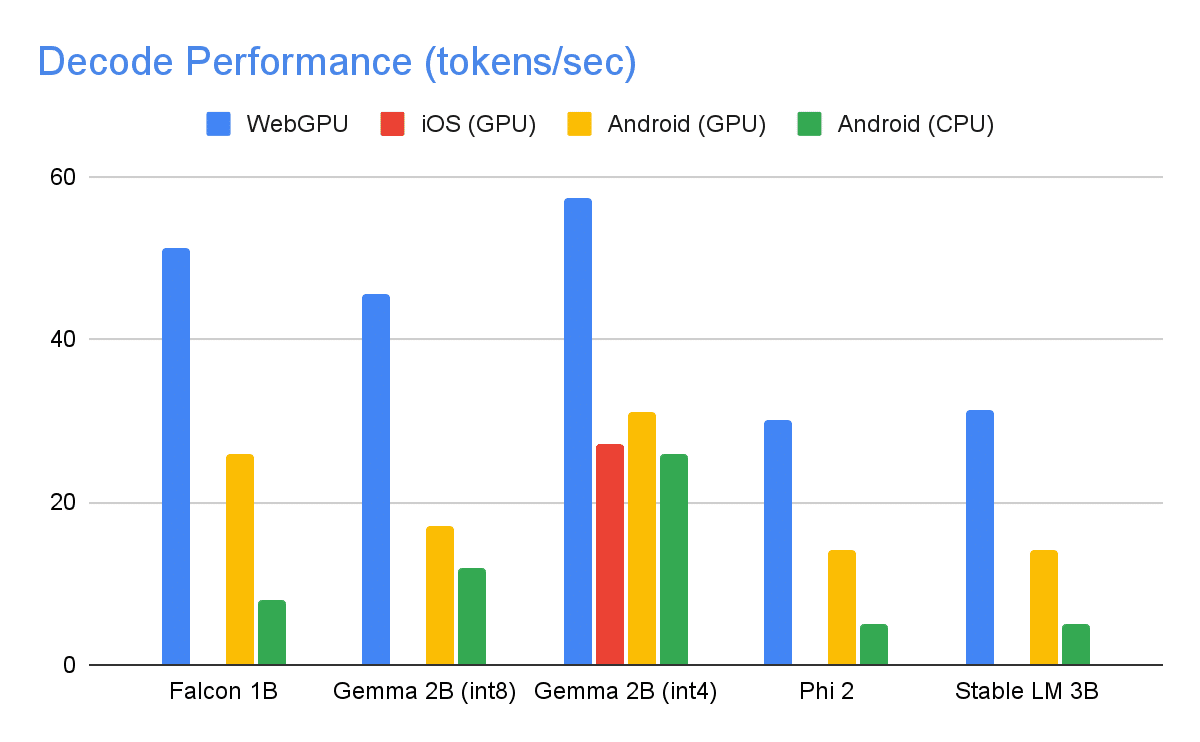
・推論速度のベンチマーク

2. Androidのデモアプリの実行
Androidのデモアプリの実行手順は、次のとおりです。
(1) Androidのデモアプリのプロジェクトをダウンロード。
(2) 「Android Studio」でAndroidのデモアプリのプロジェクト (mediapipe/examples/llm_inference/android) を開く。
(3) 「Gradle Sync」の実行を求められたら「OK」をクリック。
(4) Androidを開発者モードにしてPCと接続。
(5) サイトから「gemma-2b-it-gpu-int4.bin」をダウンロード。
(6) メニュー「View → Tool Windows → Device Explorer」で「Device Explorer」 を開き、「/data/local/tmp/llm/」に「gemma-2b-it-gpu-int4.bin」を配置。
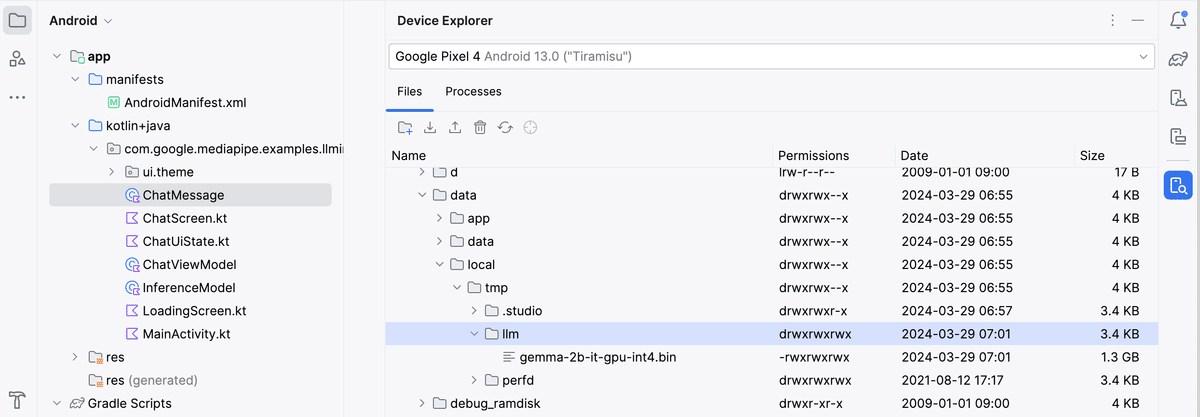
(7) 「InferenceMode」のMODEL_PATHに「/data/local/tmp/llm/gemma-2b-it-gpu-int4.bin」を指定。

(8) Android Studioの実行ボタン (▶) をクリック。
メッセージ入力するとレスポンスが出力されます。

コーディングについては、以下を参照。
3. iOSのデモアプリの実行
iOSのデモアプリの実行手順は、次のとおりです。
(1) iOSのデモアプリのプロジェクトをダウンロード。
(2) CocoaPodsをインストール。
(3) iOSのデモアプリのプロジェクトフォルダで、「pod install」を実行。
(4) 「Xcode」でiOSのデモアプリのプロジェクト (InferenceExample.xcworkspace) を開く。
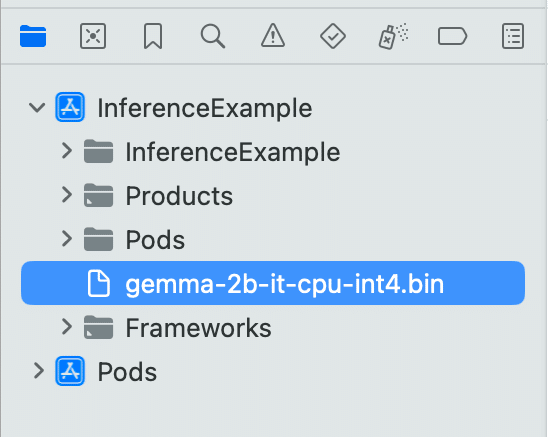
(5) サイトから「gemma-2b-it-cpu-int4.bin」をダウンロード。
(6) 「Xcode」のプロジェクトに「gemma-2b-it-cpu-int4.bin」を追加。
(7) 「Xcode」の実行ボタン (▶) をクリック。
メッセージ入力するとレスポンスが出力されます。

コーディングについては、以下を参照。