
PaliGemma の概要

以下の記事が面白かったので、簡単にまとめました。
・PaliGemma – Google's Cutting-Edge Open Vision Language Model
1. PaliGemma
「PaliGemma」は、画像エンコーダーとしての「SigLIP-So400m」とテキスト デコーダーとしての「Gemma-2B」で構成されるアーキテクチャを備えたビジョン言語モデルです。「SigLIP」は画像と文字の両方を理解できる最先端のモデルです。「CLIP」と同様に、共同で学習された画像とテキストのエンコーダーで構成されます。「PaLI-3」と同様に、結合された「PaliGemma」モデルは画像とテキストのデータで事前学習されており、キャプションや参照セグメンテーションなどの下流タスクで簡単にファインチューニングできます。「Gemma」は、テキスト生成のためのデコーダー専用モデルです。リニアアダプターを使用して「SigLIP」の画像エンコーダーと「Gemma」を組み合わせると、「PaliGemma」が強力なビジョン言語モデルになります。

「PaliGemma」のリリースには3種類のモデルが付属しています。
・PT checkpoints : 下流のタスクに合わせてファインチューニングできる事前学習済みモデル。
・Mix checkpoints : タスクの混合に合わせてファインチューニングされたPTモデル。これらは、フリーテキスト プロンプトを使用した汎用の推論に適しており、研究目的でのみ使用できます。
・FT checkpoints : それぞれが異なる学術ベンチマークに特化した、一連のファインチューニングされたモデル。これらはさまざまな解像度で利用でき、研究目的のみを目的としています。
モデルには3つの異なる解像度 (224x224、448x448、896x896) と3つの異なる精度 (bfloat16、float16、および float32) があります。各リポジトリには、特定の解決策とタスクのチェックポイントが含まれており、利用可能な精度ごとに3つのリビジョンが含まれています。各リポジトリのメインブランチにはfloat32チェックポイントが含まれていますが、bfloat16およびfloat16リビジョンには対応する精度が含まれています。HuggingFace Transformersと互換性のあるモデルと、元のJAX実装と互換性のあるモデルには別のリポジトリがあります。
高解像度モデルは入力シーケンスがはるかに長いため、実行に多くのメモリを必要とします。OCR などのきめ細かいタスクには役立つ場合がありますが、ほとんどのタスクでは品質の向上はわずかです。224 バージョンは、ほとんどの目的にまったく問題ありません。
このCollectionにはすべてのモデルとSpacesがあります。
2. モデルの機能
「PaliGemma」は、会話での使用を目的としていないシングルターンビジョン言語モデルであり、特定のユースケースに合わせてファインチューニングする場合に最適に機能します。
「detect」や「segment」などのタスク接頭辞を条件付けすることで、モデルがどのタスクを解決するかを構成できます。事前学習されたモデルは、豊富な機能 (質問応答、キャプション、セグメンテーションなど) を組み込むためにこの方法で学習されました。 ただし、これらは直接使用するように設計されているのではなく、同様のプロンプト構造を使用して特定のタスクに (ファインチューニングによって) 転送されるように設計されています。インタラクティブなテストの場合は、タスクの混合に合わせてファインチューニングされたモデルの「mix」ファミリーを使用できます。
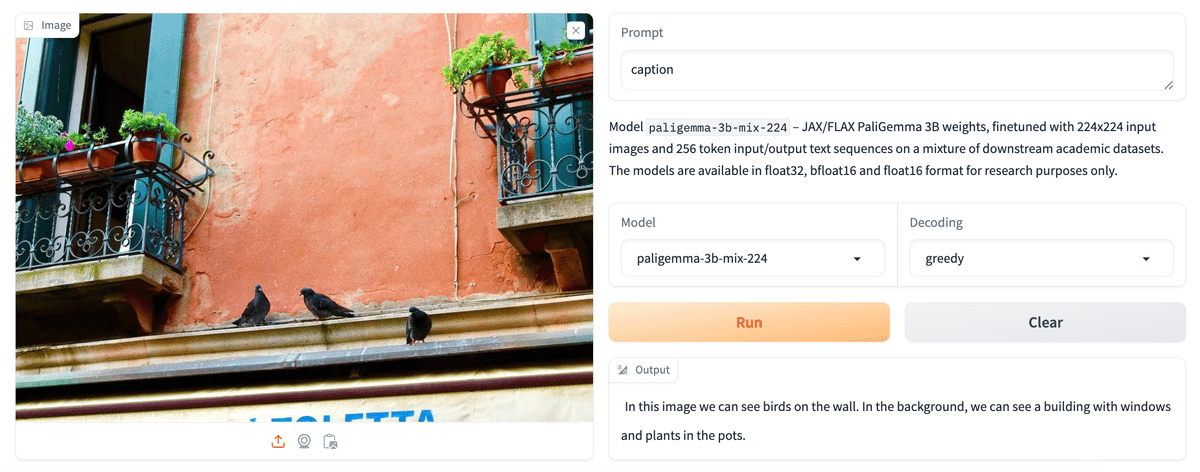
2-1. Image Captioning
「PaliGemma」は、プロンプトに応じて画像にキャプションを付けることができます。 Mix checkpointsでさまざまなキャプションプロンプトを試して、それらがどのように反応するかを確認できます。
2-2. Visual Question Answering
「PaliGemma」は画像に関する質問に答えることができます。質問を画像と一緒に渡すだけで回答できます。

2-3. Detection
「PaliGemma」は、detect [entity] プロンプトを使用して画像内のエンティティを検出できます。境界ボックスの座標の位置を特殊な <loc[value]> トークンの形式で出力します。ここで、value は正規化された座標を表す数値です。 各検出は、y_min、x_min、y_max、x_max の順で4つの位置座標と、その後にそのボックスで検出されたラベルによって表されます。値を座標に変換するには、まず数値を1024で割ってから、y に画像の高さを、x に画像の幅を掛ける必要があります。これにより、元の画像サイズを基準とした境界ボックスの座標が得られます。

2-4. Referring Expression Segmentation
「PaliGemma」Mix checkpoints では、segment [entity] プロンプトが表示された場合に、画像内のエンティティをセグメント化することもできます。 自然言語記述を使用して対象エンティティを参照するため、これは参照式セグメンテーションと呼ばれます。出力は、位置トークンとセグメンテーショントークンのシーケンスです。位置トークンは、上で説明したように境界ボックスを表します。セグメンテーショントークンをさらに処理して、セグメンテーションマスクを生成できます。

2-5. Document Understanding
「PaliGemma」 Mix checkpoints は、文書の理解と推論に優れた機能を備えています。

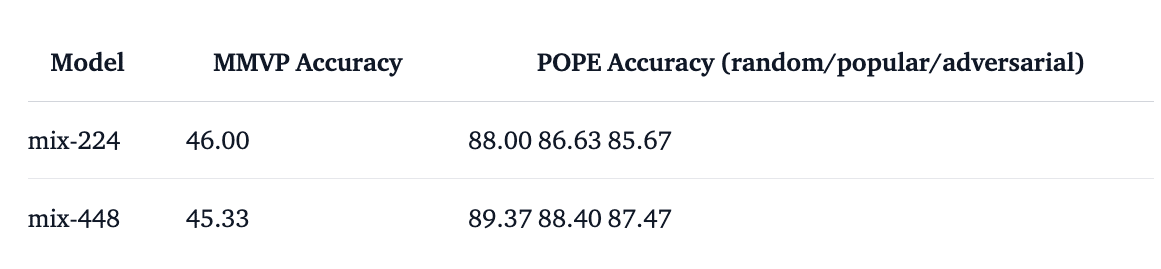
2-6. Mix Benchmarks
以下に Mix checkpoints のスコアを示します。
2-7. Fine-tuned Checkpoints

3. デモ
このリリースの一部として、big_vision リポジトリ 内のリファレンス実装をラップし、Mixモデルを試す簡単な方法を提供するデモが用意されています。
PaliGemma transformers API の使用方法を示す、Transformersと互換性のあるバージョンのデモも用意しています。
4. 推論
「PaliGemma」モデルにアクセスするには、「Gemma」のライセンス契約条件に同意する必要があります。すでにHuggingFaceで他の「Gemma」モデルにアクセスできる場合は、そのまま使用できます。それ以外の場合は、「PaliGemma」モデルのいずれかにアクセスし、同意する場合はライセンスに同意してください。アクセスできるようになったら、notebook_login または huggingface-cli login ログインを通じて認証する必要があります。
このノートブックで推論をすぐに試すこともできます。
4-1. Transformers の使用
PaliGemmaForConditionalGeneration クラスを使用して、リリースされたモデルのいずれかを推論できます。内蔵プロセッサを使用してプロンプトと画像を前処理し、前処理された入力を生成のために渡すだけです。
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
prompt = "What is on the flower?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(prompt, raw_image, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
# bee次のようにモデルを4bitでロードすることもできます。
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = PaligemmaForConditionalGeneration.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map={"":0}
)4bit (または8 bit) の読み込みに加えて、transformersの統合により、HuggingFace エコシステム内の次のような他のツールを利用できるようになります。
・学習および推論のスクリプトと例
・Safe Fileへのシリアル化 (safetensor)
・PEFT などのツールとの統合 (パラメータの効率的な微調整)
・モデルを使用して生成を実行するためのユーティリティとヘルパー
4-2. 詳細な推論プロセス
独自の前処理または学習コードを作成したい場合、または「PaliGemma」がどのように機能するかをより詳細に理解したい場合は、入力画像とテキストが通過するステップを以下に示します。
入力テキストは通常どおりトークン化されます。<bos> トークンが先頭に追加され、さらに改行トークン (\n) が追加されます。この改行トークンは、モデルが学習された入力プロンプトの重要な部分であるため、明示的に追加することで常にそこに存在することが保証されます。トークン化されたテキストには、固定数の <image> トークンが接頭辞として付けられます。いくつかは、入力画像の解像度と SigLIP モデルで使用されるパッチサイズによって異なります。「PaliGemma」モデルは3つの正方形サイズ (224x224、448x448、896x896) のいずれかで事前学習されており、常にパッチサイズ14を使用します。したがって、先頭に付加する <image> トークンの数は224モデルの場合256 (224/ 14 * 224/14)、448モデルの場合は1024、896モデルの場合は4096になります。
画像が大きくなると入力シーケンスが非常に長くなるため、モデルの言語部分を処理するためにより多くのメモリが必要になることに注意してください。どのモデルを使用するかを検討する際には、この点に留意してください。OCR などのきめの細かいタスクの場合、画像を大きくするとより良い結果が得られる可能性がありますが、大部分のタスクでは品質の増分はわずかです。より大きな解像度に移行する前に、タスクをテストしてください。
この完全な「プロンプト」は、言語モデルのテキスト埋め込み層を通過し、トークンごとに 2048 次元のトークン埋め込みを生成します。
これと並行して、bicubic resampling を使用して入力画像のサイズが必要な入力サイズ (最小解像度モデルの場合は 224x224) に変更されます。次に、SigLIP Image Encoder を通過して、パッチごとに 1152 次元の画像埋め込みを生成します。ここでリニア プロジェクターが登場します。画像の埋め込みが投影されて、テキスト トークンから取得されるものと同じ、パッチあたり 2048 次元の表現が取得されます。その後、最終的な画像埋め込みが <image> テキスト埋め込みとマージされ、これが自己回帰テキスト生成に使用される最終入力になります。生成は自動回帰モードで通常どおり機能します。完全な入力 (画像 + bos + プロンプト + \n) に対して完全なブロックアテンションを使用し、生成されたテキストに対して因果的アテンションマスクを使用します。
これらの詳細はすべてプロセッサーとモデルのクラスで自動的に処理されるため、前の例で示した使い慣れた高レベルのtransformer API を使用して推論を実行できます。
5. ファインチューニング
5-1. big_vision の使用
「PaliGemma」は big_vision コードベースで学習しました。同じコードベースは、BiT、オリジナルの ViT、LiT、CapPa、SigLIP などのモデルの開発にすでに使用されていました。
プロジェクト設定フォルダ configs/proj/paligemma/ には README.md が含まれています。事前学習されたモデルは、transfers/ サブフォルダ内の構成ファイルを実行することで転送できます。すべての転送結果は、そこに提供されている構成を実行することによって取得されました。独自のモデルを転送する場合は、サンプル構成 transfers/forkme.py をフォークし、コメントの指示に従ってユースケースに適応させます。
無料のT4 GPUランタイムで動作する簡素化されたファインチューニングを実行する Colab finetune_paligemma.ipynb もあります。 限られたホストおよび GPU メモリに適合するために、Colabのコードはアテンションレイヤー (170M パラメータ) の重みのみを更新し、(Adam の代わりに) SGD を使用します。
5-2. transformers の使用
@「PaliGemma」のファインチューニングは、transformersのおかげで非常に簡単です。QLoRA または LoRA のファインチューニングを行うこともできます。この例では、デコーダーを簡単にファインチューニングしてから、QLoRA のファインチューニングに切り替える方法を示します。最新バージョンのtransformersライブラリをインストールします。
$ pip install git+https://github.com/huggingface/transformers.git推論セクションと同様に、notebook_login() を使用してモデルへのアクセスを認証します。
from huggingface_hub import notebook_login
notebook_login()この例では、VQAv2 データセットを使用し、画像に関する質問に答えるためにモデルをファインチューニングします。データセットをロードします。列 question、multiple_choice_answer、image のみを使用するので、残りの列も同様に削除します。データセットも分割します。
from datasets import load_dataset
ds = load_dataset('HuggingFaceM4/VQAv2', split="train")
cols_remove = ["question_type", "answers", "answer_type", "image_id", "question_id"]
ds = ds.remove_columns(cols_remove)
ds = ds.train_test_split(test_size=0.1)
train_ds = ds["train"]
val_ds = ds["test"]次に、画像処理とトークン化部分を含むプロセッサをロードし、データセットを前処理します。
from transformers import PaliGemmaProcessor
model_id = "google/paligemma-3b-pt-224"
processor = PaliGemmaProcessor(model_id)「PaliGemma」が視覚的な質問に答えるように条件付けるためのプロンプトテンプレートを作成します。トークナイザーは入力をパディングするため、ラベルのパッドをトークナイザーのパッドトークンおよびイメージトークン以外のものに設定する必要があります。
トークン化部分では、改行はプロンプト条件付けに使用され、個別にトークン化する必要があるため、tokenize_newline_ Separately フラグを渡します。推論中、これはデフォルトで True になります。
device = "cuda"
image_token = processor.tokenizer.convert_tokens_to_ids("<image>")
def collate_fn(examples):
texts = ["answer " + example["question"] + "\n" + example['multiple_choice_answer'] for example in examples]
images = [example["image"].convert("RGB") for example in examples]
tokens = processor(text=texts, images=images,
return_tensors="pt", padding="longest",
tokenize_newline_separately=False)
labels = tokens["input_ids"].clone()
labels[labels == processor.tokenizer.pad_token_id] = -100
labels[labels == image_token] = -100
tokens["labels"] = labels
tokens = tokens.to(torch.bfloat16).to(device)
return tokensモデルを直接ロードすることも、QLoRA の 4bitでモデルをロードすることもできます。以下に、モデルを直接ロードする方法を示します。モデルをロードし、画像エンコーダーとプロジェクターをフリーズし、デコーダーのみをファインチューニングします。画像が特定のドメイン内にあり、モデルが事前学習されたデータセットに含まれていない可能性がある場合は、画像エンコーダーのフリーズをスキップすることをお勧めします。
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16).to(device)
for param in model.vision_tower.parameters():
param.requires_grad = False
for param in model.multi_modal_projector.parameters():
param.requires_grad = TrueQLoRA 用に 4bitでモデルをロードする場合は、以下の変更を追加できます。
from transformers import BitsAndBytesConfig
from peft import get_peft_model, LoraConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_type=torch.bfloat16
)
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
#trainable params: 11,298,816 || all params: 2,934,634,224 || trainable%: 0.38501616002417344次に、Trainer と TrainingArguments を初期化します。QLoRA のファインチューニングを行う場合は、代わりにオプティマイザーを paged_adamw_8bit に設定します。
from transformers import TrainingArguments
args=TrainingArguments(
num_train_epochs=2,
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
warmup_steps=2,
learning_rate=2e-5,
weight_decay=1e-6,
adam_beta2=0.999,
logging_steps=100,
optim="adamw_hf",
save_strategy="steps",
save_steps=1000,
push_to_hub=True,
save_total_limit=1,
bf16=True,
report_to=["tensorboard"]
)Trainer を初期化し、データセット、データ照合関数、学習引数を渡し、train() を呼び出して学習を開始します。
trainer = Trainer(
model=model,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=collate_fn,
args=args
)
trainer.train()