
StackLLaMA : RLHFでLLaMAを学習するための実践ガイド

以下の記事が面白かったので、簡単にまとめました。
1. はじめに
この記事では、「SFT」「RM」「RLHF」の組み合わせで、「Stack Exchange」の質問に答える「StackLLaMA」の学習の全ステップを紹介します。
・SFT (Supervised Fine-tuning) : 教師ありファインチューニング
・RM (Reward / preference modeling) : 報酬 / 嗜好モデリング
・RLHF (Reinforcement Learning from Human Feedback) : ヒューマンフィードバックからの強化学習

「StackLLaMA」は、以下でデモを試すことができます。
ベースモデルとして「LLaMA 7B」、データセットとして「StackExchange」データセットを使用しています。
2. Stack Exchange データセット
「StackExchange」データセットは、「StackExchange」プラットフォームの質問応答のデータセットで、「賛成票の数」と「受け入れられた回答」も含まれています。
Askell et al.2021 に従い、各回答にスコアを付与しています。
score = log2 (1 + upvotes) rounded to the nearest integer, plus 1 if the questioner accepted the answer (we assign a score of −1 if the number of upvotes is negative).「報酬モデル」では、比較するために1問につき2つの答えが常に必要です。1問あたり最大10個の回答ペアでサンプリングしました。そして、モデル出力をより読みやすくするために、HTMLをMarkdownに変換しています。
3. 効率的な学習戦略
大規模なモデルの学習には、膨大な量のメモリが必要です。半精度学習など、いくつかのトリックを使えば、メモリを節約できますが、遅かれ早かれ使い果たしてしまいます。
3-1. PEFT
メモリ対策の1つとして、8bitで読み込んだモデルに対して「LoRA」を実行できる「PEFT」を利用する方法があります。
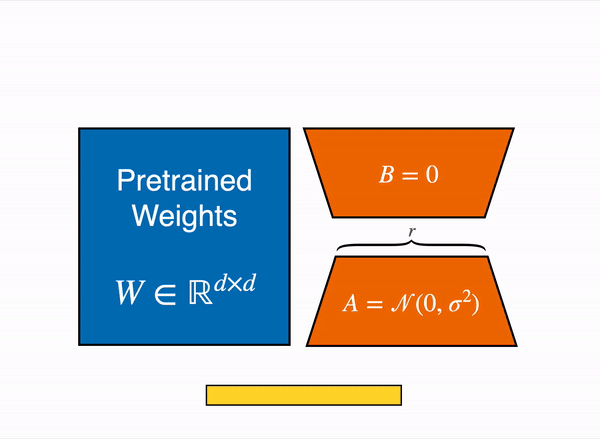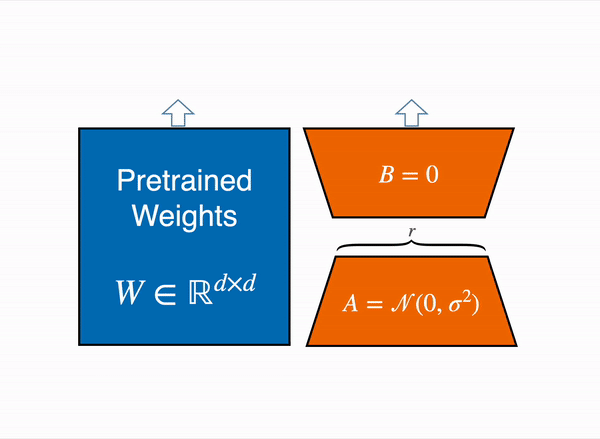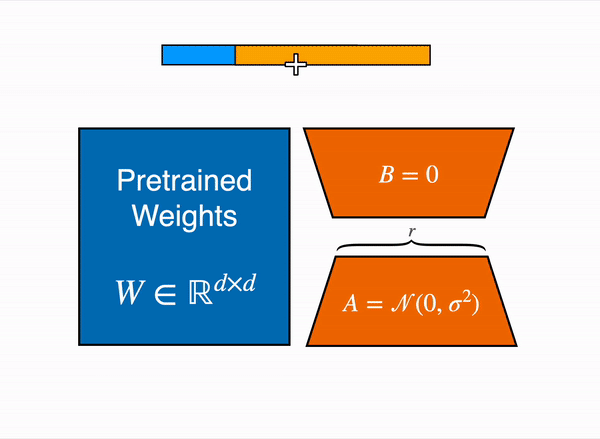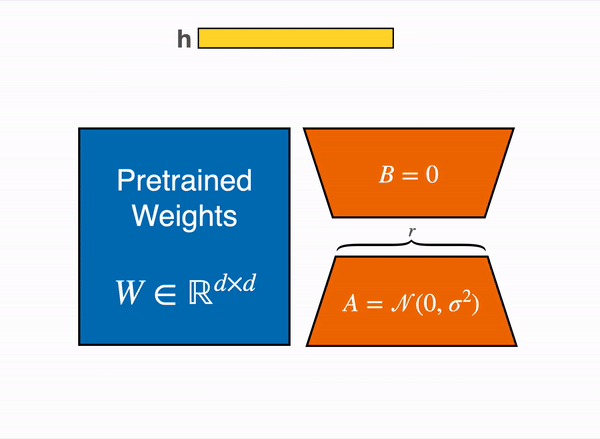
モデルを8bitでロードすると、重みのパラメータごとに1バイトしか消費しないため、メモリが大幅に削減されます (LlaMa 7Bのメモリは 7GB)。 元の重みを直接学習する代わりに、LoRA はいくつかの特定のレイヤーの上に小さなアダプターレイヤーを追加します。そのため、学習可能なパラメータの数は大幅に減少します。
3-2. 並列処理
大規模なモデルを1つのGPUに収めることができるようになりましたが、学習は依然として遅くなる傾向があります。このシナリオの最も単純な戦略は「並列処理」です。同じ学習を別々のGPUに複製し、異なるバッチを各GPUに渡します。これにより、モデルの前方/後方パスを並列化し、GPUの数に応じて拡張できます。

ここでは、「transformers.Trainer」または「Accelerate」のいずれかを使用します。どちらも、「torchrun」または「Accelerate launch」でスクリプトを呼び出すときに引数を渡すだけで、コードを変更せずに並列処理をサポートします。
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py
torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py4. 教師ありファインチューニング
「RLHF」を行う前にモデルをファインチューニングすることは、特別なことではありません。事前学習による因果関係言語モデリングの目的を適用しているだけになります。データを効率的に使用するために、パッキングと呼ばれる手法を使用しています。バッチ内のサンプルごとに1つのテキストを用意し、最長テキストにパディングする代わりに、EOSトークンを挟んで多くのテキストを連結し、パディングなしでバッチを埋めるためにコンテキストサイズのチャンクを切り分けます。

このアプローチでは、モデルを通過する各トークンが学習されるため、学習がより効率的に行われます。
パッキングは「ConstantLengthDataset」によって処理され、PEFTでモデルをロードした後にTrainerを使用できます。モデルをint8でロードし、学習用に準備してから、LoRAアダプタを追加します。
# 8bitモデルのロード
model = AutoModelForCausalLM.from_pretrained(
args.model_path,
load_in_8bit=True,
device_map={"": Accelerator().local_process_index}
)
model = prepare_model_for_int8_training(model)
# LoRAアダプタの追加
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)5. 報酬 / 嗜好モデリング
人間のアノテーションをそのまま使って「RLHF」を使ったモデルのファインチューニングを行うことができます。しかし、この場合、最適化の繰り返し後に、いくつかのサンプルを人間に送り、評価を受ける必要があります。これは、高価で時間がかかります。
直接的なフィードバックの代わりに有効なのが、人間のアノテーションをもとに学習した「報酬モデル」を使用する方法です。「報酬モデル」は、プロンプト x と2つの回答候補 (y_k, y_j) から、人間のアノテーションによってどちらが高く評価されるかを予測します。
これは、次の損失関数で表現できます。

「StackExchange」データセットを使用すると、スコアをもとに2つの回答のうちどちらがユーザーに好まれたかを推測できます。その情報と上で定義した損失を使用して、カスタム損失関数を追加して「transformers.Trainer」を変更できます。
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return loss100,000組の候補のサブセットを利用し、保持された50,000組の候補で評価します。 適度なバッチサイズ4 で、BF16 精度のAdamオプティマイザを使用して単一エポックに対してLoRA PEFTアダプタを使用して LLaMA モデルを学習します。
LoRA の構成は次のとおりです。
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)学習は8-A100 GPU で数時間かかり、モデルは最終精度67%を達成しました。これはスコアが低いように思えますが、このタスクは人間にとっても非常に難しいものになります。
6. 人間のフィードバックからの強化学習
「RLHF」のステップは、次のとおりです。
(1) プロンプトから応答を生成。
(2) 報酬モデルを使用して応答を評価。
(3) 評価を使用して強化学習ポリシー最適化ステップを実行。

クエリと応答のプロンプトは、トークン化されてモデルに渡される前に、次のようにテンプレート化されます。
Question: <Query>
Answer: <Response>「SFT」「RM」「RLHF」には同じテンプレートを使用しています。
強化学習を使用して言語モデルを学習する場合の一般的な問題は、モデルが意味不明な内容を生成することで高い報酬を得る方法を学習してしまうことです。この対策のため、報酬にペナルティを追加します。
学習していないモデルの参照を保持し、「KL-divergence」を計算することで新しいモデルの生成を参照モデルと比較します。
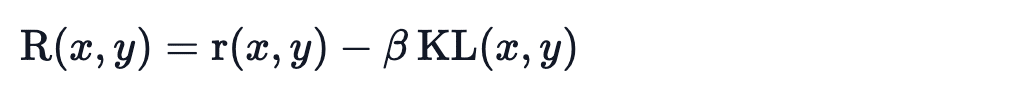
ここで、r は報酬モデルからの報酬、KL(x,y) は現在のポリシーと参照モデル間の「KL-divergence」です。
もう一度、記憶効率の高い学習PEFTを利用します。これは、RLHF のコンテキストでさらなる利点を提供します。ここで、参照モデルとポリシーは同じベースであるSFTモデルを共有しており、これを8bitでロードし、学習中にフリーズします。 基本モデルの重みを共有しながら、PPOを使用してポリシーの LoRA 重みを排他的に最適化します。
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# ポリシーからサンプリングして応答を生成
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
)
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# 感情スコアを計算
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
# PPOステップの実行
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
# 統計を W&B に記録
ppo_trainer.log_stats(stats, batch, rewards)3x8 A100-80GB GPUで20 時間学習しました。

モデルの性能は1000ステップ程度で頭打ちになります。
学習後のモデルはどんなことができるのか見てみます。

アドバイスはまだ信用できませんが、この回答は首尾一貫しており、Googleへのリンクも用意されていることがわかります。
7. 課題
「LLM」の強化学習は、常に順風満帆というわけではありません。今回紹介したモデルは、多くの実験、失敗、ハイパーパラメータ調整の結果です。それでも、このモデルは完璧とは言い難いです。
以下では、このモデルを作る過程で遭遇した観察結果や頭痛の種をいくつか紹介します。
7-1. 報酬が高いということは、パフォーマンスが高いということ?

強化学習では、できるだけ高い報酬を得たいと考えます。「RLHF」では「報酬モデル」を使用していますが、これは不完全なもので、チャンスがあればPPOはこの不完全さを利用しようとします。これは、報酬の急激な増加として現れます。生成されたテキストを見ると、ほとんどが ``` という文字列の繰り返しの場合がありました。コードを含む回答は、ないものよりも通常高くランクされることを、「報酬モデル」が発見したのです。幸いなことに、この種の問題はあまり観察されず、KLペナルティの対策が効いているようです。
7-2. KLは常にプラスの値?
前述したように、モデルの出力を基本方針の出力に近づけるために、KLペナルティが使用されます。一般に、「KL-divergence」は2つの分布間の距離を測定し、常に正です。しかし、「trl」ではKLの推定値を使用し、期待値として実際の「KL-divergence」と等しくなります。

明らかに、トークンが「SFT」モデルよりも低い確率でポリシーからサンプリングされる場合、これは負のKLペナルティにつながりますが、平均的には正の値になります。しかし、生成戦略によっては、一部のトークンを強制的に生成させたり、一部のトークンを抑制したりすることができます。例えば、バッチで生成する場合、完成したシーケンスはパディングされ、最小長を設定する場合、EOSトークンは抑制されます。モデルは、これらのトークンに非常に高い確率や低い確率を割り当てることができ、これが負のKLにつながる。PPOアルゴリズムは報酬を最適化するため、これらの負のペナルティを追い求めることになり、不安定になります。

7-3. 継続的な課題
現在も、より深く理解し、解決していかなければならない問題が数多く存在します。例えば、損失が急増することがあり、それがさらなる不安定さを引き起こす可能性があります。
