Google Colab で Stable Video 3D を試す

「Google Colab で「Stable Video 3D」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. Stable Video 3D
「Stable Video 3D」は、マルチビュー合成のためのImage-to-Videoモデルです。同じサイズの1つのコンテキストフレーム (理想的には1つのオブジェクトを含む白い背景の画像) を与えて、解像度576x576で21フレームを生成するように学習しています。
「Stable Zero123 」と比較して、品質とマルチビューが大幅に改善され、「Zero123-XL」などの他のオープンソースの代替製品よりも優れています。
このモデルには2つのバリアントが提供されています。
・SV3D_u : カメラ軌道なしで単一画像から軌道動画を生成
・SV3D_p : 単一画像とカメラ軌道から3D動画を生成
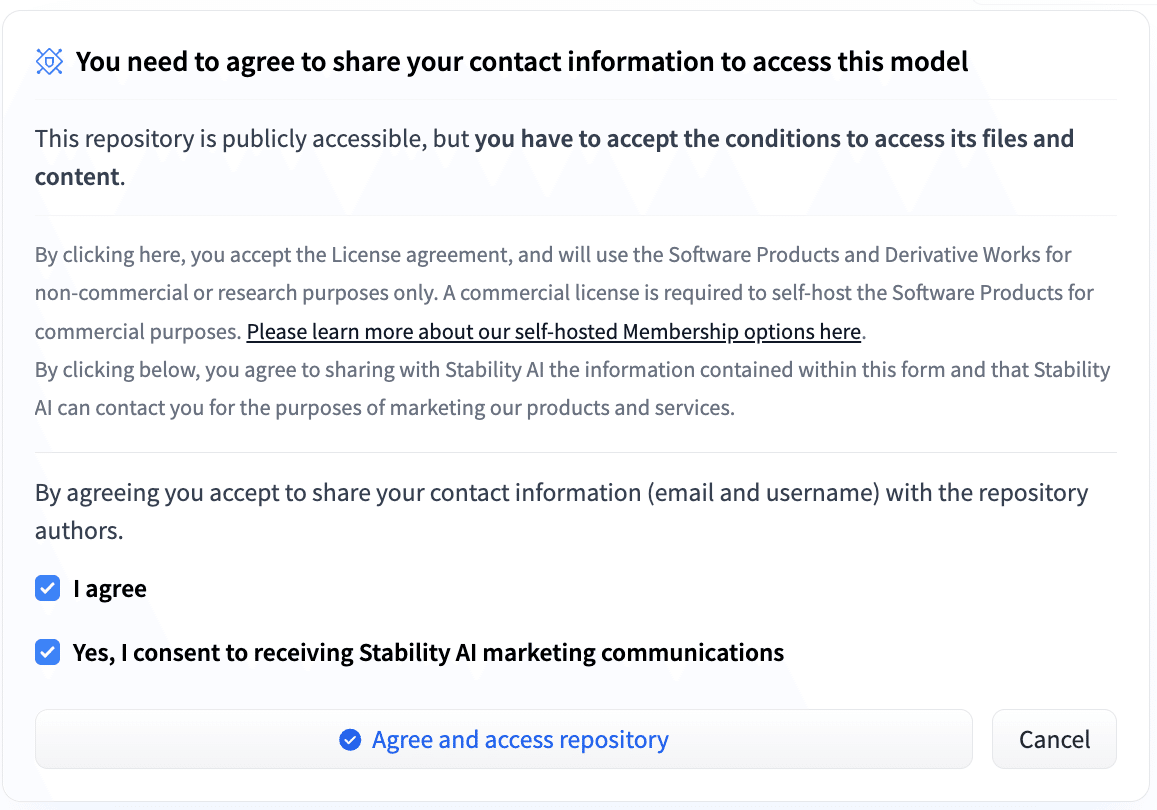
2. 利用許諾の確認
HuggingFaceのモデルカード「stabilityai/sv3d」を開き、「Agree and access repository」ボタンを押してください。
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
3-1. SV3D_u
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/Stability-AI/generative-models
%cd generative-models
!pip install -r requirements/pt2.txt
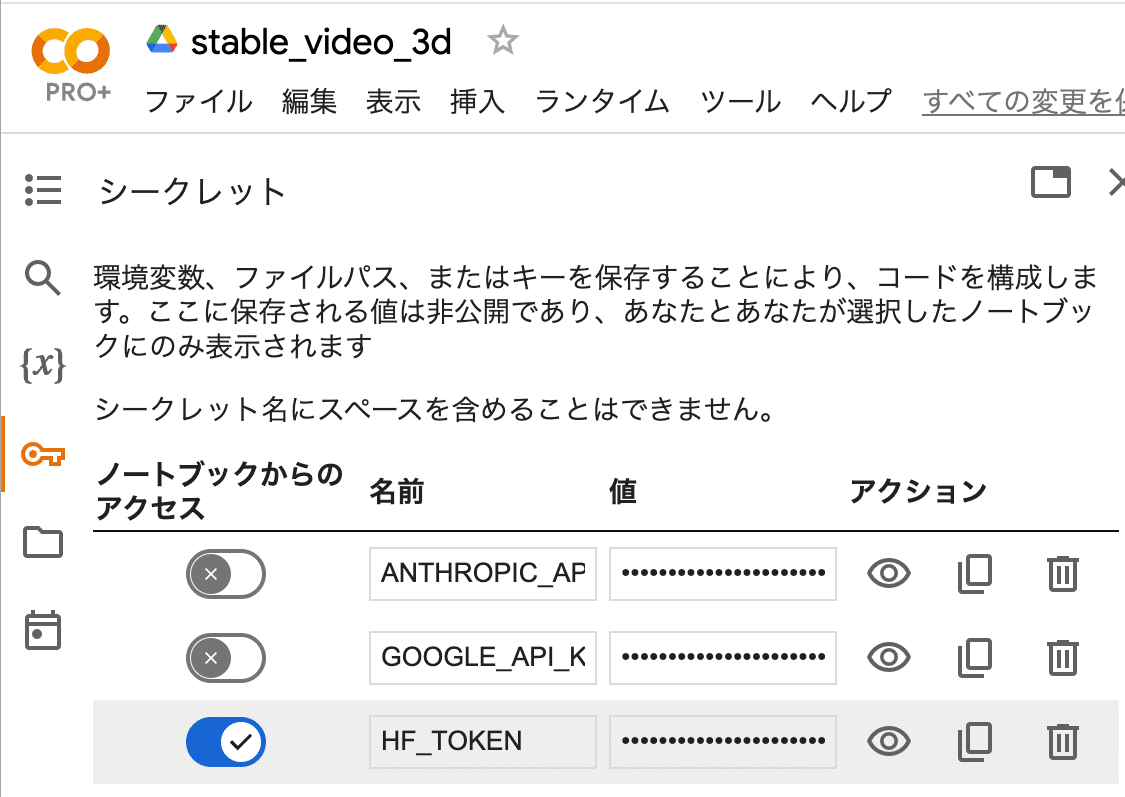
!pip install .(3) 「HuggingFace」からAPIキー (Access Token) を取得し、Colabのシークレットマネージャーに登録。
キーは「HF_KEY」とします。
(4) モデルを「generative-models/checkpoints」に配置。
「sv3d_u.safetensors」と「sv3d_p.safetensors」を「checkpoints」にダウンロードします。
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="stabilityai/sv3d", filename="sv3d_u.safetensors", local_dir="checkpoints")
hf_hub_download(repo_id="stabilityai/sv3d", filename="sv3d_p.safetensors", local_dir="checkpoints")(5) 画像を「generative-models」に配置。
・girl.png

(6) 「simple_video_sample.py」で推論実行。
# 推論の実行
!python scripts/sampling/simple_video_sample.py --input_path girl.png --version sv3d_uパラメータは、次の通りです。
--input_path : 入力画像
--version : sv3d_u
「outputs/simple_video_sample/sv3d_u」に動画が出力されます。

Stable Video 3Dをお試し中。https://t.co/C4GR4VdExi pic.twitter.com/TI8Gr4m60f
— 布留川英一 / Hidekazu Furukawa (@npaka123) March 19, 2024
3-2. SV3D_p
(1) 「simple_video_sample.py」で推論を実行。
# 推論の実行
!python scripts/sampling/simple_video_sample.py --input_path girl.png --version sv3d_p --elevations_deg [0,5,10,15,20,25,30,25,20,15,10,5,0,-5,-10,-15,-20,-15,-10,-5,0] --azimuths_deg [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]パラメータは、次の通りです。
--input_path : 入力画像
--elevations_deg : 21個の仰角 ([-90, 90]度)
--azimuths_deg : 21個の方位角 ([0,360]度)
--version : sv3d_p
「outputs/simple_video_sample/sv3d_p」に動画が出力されます。
カメラ軌道付きで動画生成 pic.twitter.com/SHgybBrR3Z
— 布留川英一 / Hidekazu Furukawa (@npaka123) March 19, 2024
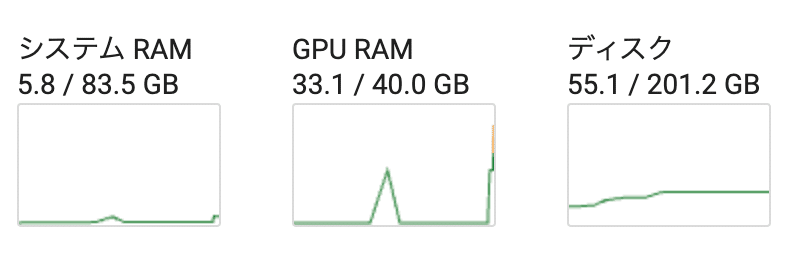
GPUのメモリは最大33.1GB消費しました。