
画像生成AI関連の覚書

はじめに
ふんわりとした知識のまま大雑把にまとめてしまった故に、ある程度の知識がついた状態でまとめ直そうとすると最初から書き直しレベルになってしまいそうだったので、新たに記事を作ることにしました。
上の記事は非公開にしたいところですが、参考サイトとして引用されている可能性を考えてそのままにしておきます。
この記事は生成AIや法律について知識がある方との会話や、自分なりに検索したり、本を読んだ上でまとめたものです。
2024年11月までの知識であることを留意して読んで頂ければと思います。
この記事はあくまでnote主の覚え書きであって、正しい知識を収集したものではありません。
最初に言いますが、note主はAI推進(生成AIユーザー、文字通りの推進)ではないし反AI(生成AI絶滅)や規制派でもございません。あくまでフラットな立場(中立派ともいう)。
この記事は調べるきっかけや、とっかかりを得るための参考記事と思って下さい。
なんもわからん~って方は、まず何が理解出来ていないか文章にするなどをして言語化してみてください。
著作権、生成AIそのもの、画像生成AI、それ関連の単語の意味や仕組みが分からない。
クリエイターの問題のきっかけ、何故問題になっているか、どう対策すればいいか、法律は何故細かく区別出来ないのか分からない。
自分は何故生成AIor画像生成AIに対して嫌悪感があるか?
この辺を切り分けましょう。
①著作権を調べる
②著作権、ガイドライン、(因習)ルールの違いを理解する
③二次創作は何故許されてるのかを学び、理解する
④無断転載、無断学習の違いを学ぶ
⑤サイン、ウォーターマーク、電子透かしの違いを理解する
⑥何故無断学習やAI学習禁止を拡散するクリエイターはバカにされるか考える
⑦ノイズ、データポイズニングの違いを理解する
⑧AI(人工知能)の仕組みを学ぶ
⑨生成AIの仕組みを学ぶ
⑩画像生成AIの仕組みを学ぶ
⑪文化庁や赤松健議員のやろうとしていることを知る
⑫法律は何故人間(手描き)と機械(AI)で区別出来ないのかを考える
⑬画像生成AIは排除すべきか考える
の順番でやっていけば何とかなると思います。
僕は画像生成AIの使い方と著作権と因習ルールの違いを知った上で、感情を切り離したらすぐ受け入れました。
個人的に、規律とルールの違いを知ること、自分の感情を切り分けることが大事だと思います。
法律は細かく分類するのはよくないんだと、性犯罪の改正を見て何となく理解はしました。
こういう記事を読んで、何から調べるか?のきっかけになれたら幸いです。
間違った情報は出来るだけ載せないようにしていますが、覚え間違いしたり誤読している可能性はあります。
まとめが中途半端な内容もあるかもしれません。
意味が違うものや誤字脱字はコメントで遠慮なく指摘して頂ければ助かります。
新しい知識が入ったら本記事に追加・加筆するかもしれないし、また別の記事を作って語っているかもしれません。
別記事に関しては最後の記事まとめを更新しておきます。
かなり長くなるため、目次を作っておきますので気になるところ、読みたいところからどうぞ。
ざっくりまとめで簡単にまとめてあります。
最終更新:2024.11.16
・画像生成AIとは?
・生成AIとAIの違い
・AIとは
AIとは人工知能(Artificial Intelligence(アーティフィシャル インテリジェンス))の略称。コンピューターの性能が大きく向上したことにより、機械であるコンピューターが「学ぶ」ことができるようになりました。それが現在のAIの中心技術、機械学習です。
機械学習をはじめとしたAI技術により、翻訳や自動運転、医療画像診断や囲碁といった人間の知的活動に、AIが大きな役割を果たしつつあります。
文部科学省では、AIが私たちの生活にもっと使われて便利になるように、理化学研究所のセンターなどでAIの基本となる数学やアルゴリズムの研究を進めています。
引用サイト:文部科学省
・生成AIとは
ジェネレーティブAIとも呼ばれる生成AIは、ユーザーのプロンプトやリクエストに応じてテキスト、画像、動画、音声、ソフトウェアコードなどのオリジナル・コンテンツを作成できる人工知能(AI)です。
生成AIは、ディープラーニング・モデルと呼ばれる高度な機械学習モデル(人間の脳の学習プロセスと意思決定プロセスをシミュレートするアルゴリズム)に依存しています。
これらのモデルは膨大な量のデータに内在するパターンや関係を識別してエンコードし、その情報を使用してユーザーの自然言語によるリクエストや質問を理解し、新しく適切なコンテンツを作成します。
一般に、生成AIは以下の3つのフェーズで動作します。
トレーニング:複数の生成AIアプリケーションのベースとなる基盤モデルを作成します。
チューニング:特定の生成AIアプリケーションに合わせて基盤モデルを調整します。
生成、評価、再調整:生成AIアプリケーションの出力を評価し、品質と精度を継続的に改善します。
引用サイト:IBM
・AIの歴史
知能を持つ機械は18~1950年ごろまでにメカニカル・ターク、ジャガード織機、エイダ・ラブレス、チューリング・テストなどで開発されていた。
ジェニー紡績機、水力紡績機、ミュール紡績機など織物が機械化され生産効率が向上してコンピュータのパンチカードの原型といわれるものを組み込んだジャガード織機で繊維産業の革命がもたらされた。
その後にラッダイト運動が行われた記録がある。
AI黎明期は1956~70年代にかけて、1957年には人工ニューラルネットワークが開発された。
AI転換期は1980~2000年代にかけて、第五世代コンピュータの出現で今までの技術ではデータ収集やAI技術の限界を感じ迷走し始める。
1990年代にはジェネラティブ・アートがあった。
2010~20年までの間に深層学習革命期に入り、2022年以降の生成AIの型となる深層学習の開発が進む。
2012年にアレックス・ネットを用いてディープラーニングの認知度を上げていった。
2014年にGAN(生成的敵対ネットワーク)が登場し、2017年以降のAIアートを支える技術になる。
2014年に開発されたAlphaGo(アルファ碁)は改良を重ねて2016年に世界トップクラスの韓国人棋士を破ったことで注目を集めた。
2017年にはトランスフォーマーというニューラルネットワークをGoogle Brainチームが発表し、現在のChatGPTや画像生成AI、音楽生成AIなどの内部で活用され始めた。
同時期にディープフェイク技術が登場し、偽情報が拡散される問題が出始める。
2022年から現在までにさまざまな生成AIが登場した。
4~5月にDALL-E2を発表したことをきっかけに、7月にMidjourney、8月にStable Diffusion、10月にNovelAIが登場し、2022年は画像生成AI元年と呼ばれている。
mimicは8月下旬ごろに登場し、mimic問題として取り上げられ数日後にサービス開始を取り下げた。
現在も集中学習されることを問題視されているLoRAは12月に登場している。
ChatGPTも同じ年の11月下旬に公開されている。
・拡散モデルとは?
生成AIはGPT、VAE、GAN、拡散モデルなどを使って生成されている。
拡散モデルの前にGPT、VAE、GANとはなにかをざっくり解説する。
GPTはOpenAIが開発した自然言語処理モデル。
テキスト系なので今回は省略する。
VAEはVariational Auto-Encoderの略で、変分オートエンコーダーと呼ばれている生成モデルの一つ。
状来のオートエンコーダは潜在変数が存在せず、データを圧縮したものをエンコーダと呼ばれ、そのまま再構築したのをデコーダと呼ばれる。
変分オートエンコーダーでは潜在変数に確率分布を仮定することで、潜在変数を元に再構築する。
GANは2014年に出たGenerative Adversarial Networksの略で、敵対的生成ネットワークと呼ばれている生成モデルの一つ。
ジェネレータという偽物の入力データを作り出し、ディスクリミネーターでその偽物を見破ることから敵対的と言われているそうで、この2つのニューラルネットワークを競わせてデータを学習させたもの。
これによってリアリティなものが生成出来るっぽい。

拡散モデルとは拡散過程で元画像を少しずつガウシアンノイズを当てて、劣化させながら完全なノイズ(乱雑なピクセルの集まり)になったものを、逆拡散過程で徐々にノイズを取り除きながら元の画像の特徴を予測して再構成する技術とのこと。
学習した確率分布から画像を生成しているので、元画像に似たものが出ることはあってもピクセル単位で一致することはほとんど無いそう。
つまり、さまざまなイラストを学習して似たようなイラストが生成されても、元のイラストと完全一致することは難しいとのこと。
サイコロをたくさん振って1の目の確率は何%か調べる。それを1〜6までやって出来たのが確率分布。
サイコロをりんごの画像に例えて、これをたくさん学習して確率分布を作ります。
画像にノイズを加えて、画像がぼやけた状態から徐々に元の形に戻すような作業を繰り返した結果、確率的に「多くの人が見たことのある平均的な特徴」が反映されやすくなる。
そうすると「りんご」というプロンプトを入れれば「みんなが見たことあるようなりんご」が出てくる仕組み。
所謂マスピ顔も、たくさんのイラストから確率分布を使って出来たもので「どこかで見たことあるはずなのに、どのイラストレーターの絵柄か分からないな」みたいなことが起きる。
僕が学習モデルだったとして、今までの人生で赤りんごをよく見かけるイメージあるので、高確率で赤りんごを描きます。一応青りんごも見たことあるので、低確率で青りんごになるかもしれません。
でも赤りんごと青りんごが混ざったものは見たことないので、赤青のまだらなりんごは描けない!
これが生成AIのデメリットで、データにないと自由に想像して作ることが出来ません。
ただしそんな生成AIでも学習、プロンプト次第で偶然とんでもないものが生み出される可能性はある、一例は2022年に流行ったゲーミングチ●●華道部(自主規制)など。
・どうやって画像生成している?

ディープラーニングされた学習用のデータセットを使って学習してモデルデータを作る。
モデルデータは画像生成AIのサイトなどで配布されているので、ユーザーはそれを入手するか購入して使う。
学習済みのデータセットをLoRA(追加学習)させてファインチューニング(微調整)することが出来る。
やりすぎると過学習を起こす。
プロンプト(魔法でいう呪文)を使って文章を入力し、そこからノイズを固定しつつ、理想に近づくようにプロンプトを入力し直したり、理想に近づいた状態で生成ガチャしまくる。
PCのスペックやグラフィックボードによって生成時間に左右される。
Web上で生成出来るもの(ImageFXなど)ではプロンプトを入力するだけで生成することも出来る。
ただし無料だと生成数など制限があるため、課金して制限を緩めることも可能。
知り合いから生成中の動画を提供してくださったので載せておきます。
使用ソフト:Stable Diffusion t2i、Stable Diffusion i2i
動画、画像提供者:ざれさん
・t2i(txt2img)→テキスト→画像(text to image)

上がプロンプト(出力したいものを入れる)
下はネガティブプロンプト(除外ワードのようなもの)

プロンプトに生成したいキーワードを入れる。
ネガティブプロンプトとパラメーター設定で調整して生成。
・i2i(img2img)→画像→画像(image to image)
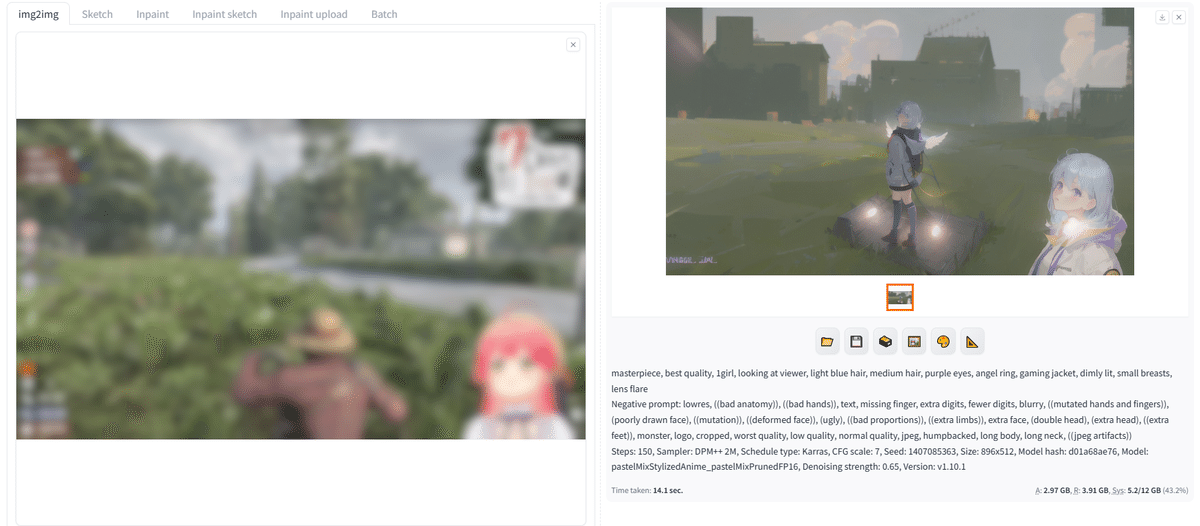
生成された画像の下はプロンプトとその他パラメータが出力されている。
・著作権法について
・著作者の権利とは

AI生成作品が著作物に当たるかどうかの判断は、人間が思想又は感情を創作的に表現するための道具として生成AIを使用したと認めれば、著作物に該当し、 生成AIユーザーは著作者となる。
人間の創作意図があるか、人間が創作的寄与と認められる行為を行ったかによって判断される。
生成AIが人間の介入なしに自律的に生成したものは著作物に当該されない。
生成AI作品は一律で著作物に該当するか否かを決められず、事情に応じて判断される。
権利者、AI開発者、AI提供者、AI利用者それぞれで著作権法の対応の範囲が変わるため、開発や提供、利用する場合は権利侵害していないか確認すること。
・イラストに対して著作権侵害される要件
①著作物性(創作性)
侵害が問題となる創作物において、作成者の思想または感情が創作的に表現されていることが必要です。自由度の低すぎる表現やありふれた表現には、著作物性(創作性)が認められない可能性が高いです。
②依拠性(いきょせい)
オリジナルの著作物に依拠して利用行為がなされたことが必要です。たまたまオリジナルと似ているにすぎない場合は、依拠性が認められないため著作権侵害は成立しません。
③同一性または類似性
オリジナルの著作物と完全に同一であるか、またはオリジナルの表現上の本質的な特徴を直接感得できる程度に似ていることが必要です。
④利用行為
著作権によって保護された行為(前述)を、著作権者に無断でしたことが必要です。
2-1. イラストの著作権に対する直接侵害の要件
引用サイト:刑事事件に強い元検事の弁護士へ相談 上原総合法律事務所

・生成AIに対する著作権侵害の要件

生成したものをSNSなどにアップロードしたり複製物を販売した場合は、通常の著作権侵害と同様の基準で判断される。
あるコンテンツの作成や利用(インターネット上での公開など)した場合、既存の著作物の著作権侵害しているかどうかは、そのコンテンツを人が作成したか、AIにより生成されたかに関わらず類似性及び依拠性があるか否か判断される。
生成された画像等に既存の著作物との類似性及び依拠性が認められた場合、著作権違法となる。
類似性の立証
既存の著作物と創作的表現が共通しているかどうかで判断する。
絵柄や画風等のアイデアなどが共通しているだけの場合、類似性は認められない。
創作的表現が一部共通または完全一致した場合、類似性と認められる。
依拠性の立証
AI利用者が権利者の作品を認識していたかどうかを権利者が主張・立証しなければいけない。
・i2i(image to image)で既存の著作物そのものを生成AIに入力した
・学習データや生成AI作品にタイトルや作者などの固有名詞を入力した
・既存の著作物を認知、入手する機会があったこと
・生成AI作品が既存の著作物と高確率で類似していること 等

・二次著作物とは?
二次創作に関しては二次著作物の著作権は外部委託者含む二次創作者全員にある。
・二次創作は何故許されている?
二次創作に関しては公式の二次創作ガイドラインを出すことで黙認してくれているだけで、基本は著作権侵害されていると思った方がいい。
二次創作ガイドラインを出している企業もあるが、あくまで方針(お願い)であることを留意すること。
ガイドラインを出していない企業にお問い合わせ、ガイドラインに書いていないものを問い合わせても本来は著作権侵害であるため、Noとしか答えられない。
公式がNGと判断して注意された場合、内容が健全でも取り下げた方が良いでしょう。
従わない場合訴訟される可能性が高くなります。
・企業が外部委託者に依頼する場合
外部委託者側に一次著作権として著作権と著作者人格権を持つ。
依頼側は外部委託者から著作権のみ譲渡などすることが可能(著作権の扱いは企業側の契約内容次第)
著作者人格権は著作権法第59条(著作者人格権は、著作者の一身に専属し、譲渡することができない)により基本譲渡など出来ないので、依頼側が「著作人格権を行使しない(著作者人格権の不行使条項)」などの契約を結ぶ必要がある(コンテンツの取り扱い的な意味で契約破棄をしないのが基本)
・著作権法第30条の4とは?
2018年に改正して追加された著作権。
著作物に表現された思想又は感情の享受を目的としない利用
著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。
ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
引用サイト:e-Gov 法令検索
享受は受け入れて自分のものにしたり、楽しむことではなく、著作物の視聴などを通じて、視聴者の知的・精神的欲求を満たすという効用を得ることに向けられた行為を指すと文化庁の見解あり。
生成AIにイラストなどを学習させるなどの情報解析に使われる場合、原則許諾が必要ない。
ただし既存の著作物を同一、類似に寄せるために学習させる場合は享受目的に当たるため、許諾が必要となる。私物利用
学習段階では著作権侵害に適用される可能性は低い。
生成されたイラストにも著作権はあり、創作的寄与がなされた場合は二次著作権として認められる。創作的な加工をされた場合も同様。
自作と呼べる範囲に制限はないため、生成されたAIイラストを公開して自作と称することは違法にあたらない。
他人が生成したAIイラストを無断転載したり、模写や贋作、構図を丸パクリした上で「自作です」と言えば違法になる可能性がある。
出力されたAIイラストが著作権侵害に適用される可能性があるのは類似性と依拠性の二つ。
画像生成AIに関しては画像→画像(image to image)の生成でもしかしたら同一性に触れる可能性はある。
学習データセットの再配布は著作権違反になる可能性がある。
ここまでは文化庁や一般の見解であり、違法しているかどうかは弁護士や裁判官の判断に左右される可能性あり。
・生成AI関連の疑問など
・ディープラーニングとは?
ディープラーニングとは、コンピューターが自動で大量のデータを解析して、データの特徴を抽出する技術です。
深層学習、またはDLと呼ばれることもあります。
人工知能技術の中には機械学習が含まれており、ディープラーニングは機械学習の一つです。
ディープニューラルネットワーク(DNN)を使った学習で、十分なデータ量があれば人間の力がなくてもデータから特徴を抽出できます。
DNNは、パターン認識をするように設計されたニューラルネットワーク(NN)が基になっています。
これは、人間や動物の脳神経回路(ニューロン)を模して作られており、アルゴリズムを多層構造化したものです。
ディープラーニングは、機械学習技術の中の一部であり、別物というわけではありません。
ニューラルネットワーク(NN)の中間層が複数になっているため、ディープ(多層)ラーニングと呼ばれています。
多層化することで、データの特徴をさらに深く学習することが可能です。
通常、NNでは中間層が2~3層程度ですが、DNNではさらに多くの層を持たせられます。
多層になることで情報伝達と処理を増やすことができ、情報量をコンピューターが判断できるようになります。
これにより多くのデータがあれば、従来の機械学習では難しかった複雑で扱いづらいデータの処理が可能になり、分析精度が向上するのです。
・ニューラルネットワークとは?
ニューラルネットワークは、人間の脳の働きを模した方法でデータを処理するようにコンピュータに教える人工知能の一手法です。
これは、深層学習と呼ばれる一種の機械学習プロセスであり、人間の脳に似た層状構造で相互接続されたノードやニューロンを使用します。
そこから適応型システムが作成され、コンピュータはそれを使用して過ちから学び、継続的に改善することができます。
したがって、人工ニューラルネットワークは、ドキュメントの要約や顔の認識などの複雑な問題をより正確に解決しようとします。
引用サイト:AWS
・ディープラーニングと機械学習の違い
ディープラーニングと人工知能・機械学習の意味合いの違い
ディープラーニングは、人工知能や機械学習と同じではありません。
人工知能の中に機械学習があり、機械学習の中にディープラーニングがあります。
つまり、ディープラーニングは、人間が行っているタスクをコンピューターに学習させる機械学習の一つという位置づけです。
人工知能(AI)が急速に発展しているため、それを支えるための技術として重要度が高まっています。
ディープラーニングと機械学習の違いと使い分け
ディープラーニングは機械学習の中の1つですが、その中でも特殊な形といえるでしょう。
機械学習は一般的に特徴量と分類器を人間の手で選択します。
一方、ディープラーニングではモデリングや特徴量の抽出などは自動で行われます。
このような違いがあるため、ディープラーニングと機械学習は使い分けることが重要です。
大量のデータとそれを処理するためのGPUがあるなら、ディープラーニングを用いるといいでしょう。片方のみの場合は機械学習となります。
・学習データとは
クローラーやスクレイピングを用いてインターネット上の画像を収集して画像+画像についているタグ群を集めたものを学習データと呼ぶ。
モデルデータには画像そのものが億枚入っているわけではなく、データとして変換されているので10GBなど容量が少ない。
画像1枚3MBとして10億枚は約3PB以上らしく、仮に10億枚のデータが10GBに圧縮されていたとして、1枚10B(換算するとアルファベット10文字分)になり、画像として形に残るのは難しいだろう。
※2,400万画素のデジタル一眼レフカメラで撮影した写真の容量は1枚あたり約10MBが目安(容量は1B→1KB→1MB→1GB→1TB→1PB)
StabilityのCEOが話していたsquishedを機械翻訳で圧縮と誤訳したことから誤解されているのではないか。
squishedは潰されるという意味になり、パソコンなどでデータを圧縮する時に使われるのはCompressである。
前後の会話からして恐らく抽出というニュアンスでsquishedを使った可能性がある。
・クローラー・スクレイピングとは
クローリングとは、クローラーというプログラムがWeb上を、WebページのリンクをたどりながらWebサイトを巡回し、Webページにある情報を保存・収集することを指します。
Webスクレイピングとは、Web上の特定の情報を自動的に抽出する技術を指します。スクレイピング(Scraping)とは「Scrape(こする・かき出す)」からきている言葉であり、情報をこするようにかき出すといった意味合いを持ちます。
Webスクレイピングは、大きく「Webクローラー」と「Webスクレイパー」の2つで構成されており、それぞれの工程によって成り立ちます。
Web上を循環するクローリング作業を担うWebクローラーが自動的に情報を収集・保存した後、Webスクレイパーがスクレイピングを行います。WebページはHTMLという言語で構築されていますが、そのHTML内から不要な情報を削った上で、必要なテキストや画像、動画などを自動で抽出するのがWebスクレイピングです。
クローリングは、あくまでWebサイト全体の情報を収集してリストアップしていくことを目的とする一方で、スクレイピングは必要な情報にしぼって抽出することを目的とします。
引用サイト:Webクローリング&WebスクレイピングサービスShtockData
クローリングは英語で巡回という意味になる。
OpenAIはGPTBot、Stable DiffusionはCommon Crawlと呼ばれるクローラーで巡回している。
クローラーはログインしないと閲覧出来ない、およびフォロワーや課金限定で閲覧出来るサイトでないと収集出来ない。
スクレイピングはAPI配布やAPI制限がなければ収集される可能性がある。
ログインしなくても閲覧出来るサイトでは真面目なクローラーであればrobots.txtで拒否の指示をすれば弾いてくれる。
URLで「https://○○○○.co.jp」の後に「/robots.txt」を入れればどのような指示を出しているか見れる。
ただし、あくまで指示(お願い)なので無視してクロールされる可能性はある。
GooglebのreCAPTCHA Enterprise、Cloudflareで今年リリースした新機能AI Scrapers and Crawlers、noaiフラグなど、スクレイピングやクローラーに対して拒否するシステムや設定を埋め込んでいる。
その設定によって生成AIに使われる学習データを収集出来なくなる。
SNSや投稿サイトでクローラー・スクレイピング対策をしているかどうかを確認しながら投稿しましょう。
・ウォーターマークとは
「無断学習禁止」などの知覚可能型透かしを入れる手法。
画像の上に大きく文字を入れて、作者自身のオリジナルであることを主張したり、コンテンツの無断転載や複製(不正コピー)などで再利用をさせない目的がある。
素材サイトや販売サイトなどでサンプル画像として使われることが多い。
50%以上の透過、および不透過せずにやった方がよいでしょう。
学習禁止の効果としては自動収集に対して効果は無く、人間による手動収集は善意のもと避けてくれる可能性あり。
Danbouruではタグ付け済みのため、ネガティブプロンプトで削除される可能性あり。
ウォーターマーク単体を配布していれば編集ソフトで除去可能。
単体で公開、無料配布されているものは除去される可能性があるため、出来るだけ使わず、自作した方がよい。
・電子透かしとは
電子透かしはメタデータとは別に任意の情報を埋め込んで、コンテンツ全体を暗号化してコピー防止していて、埋め込まれた後は削除や改ざんが出来ない。
目に見えない情報を埋め込まれるため、専用ソフトを使ってオリジナルか判断出来るらしい。
現在イラストレーターが対策しているウォーターマークは知覚可能型で、知覚困難型はデジタルデータの中に埋め込まれるもので、電子透かしはこの知覚困難型にあたる。
メタデータとは作成日とかサイズとか色々書いているもので、例えば写真なら「作成日時」「画像の解像度」「カメラのメーカー、型番」などが含まれている。
イラストの場合、右クリックしてプロパティの詳細から見れるが、バイナリエディタに通すと16進法に変換される。
AIイラストはメタデータの中にプロンプトやシード値が付与されていて、そのままアップロードすると丸見えになるらしい。
コンピュータは二進法という0と1のデータで出来ていて、インターネットは16進法を使ってバイナリ文字列として構築されていて、文字コードを使って英語や記号、日本語などに変換している(よく聞くアスキーとかUnicode辺り)


ちなみにメタデータがたくさん入っていれば入っているほどデータの容量が増えていく。
ファイルのサイズを削減するため、プロンプトなどの情報を見られないようにあえてメタデータを消すこともあるらしい。
Content CredentialsやAdobe Content Authenticityなどのメタデータを埋め込むツールがある。
・ノイズとは
画像生成AIの学習を防止するツール。
よく見られるのは摂動攻撃とデータポイズニングの二種類。
完成作品をそれぞれのツールで摂動攻撃と呼ばれるノイズを注入してモデルが誤った予測を行うように仕向ける。
不正なデータを意図的に追加することでモデルの学習を妨害するのがデータポイズニング。
どちらも生成AIと同じ仕組みでノイズ生成しているのもあり、生成AI自体に忌避感がない方でないと使えないだろう。
Glaze、emamori、CLIPSTUDIOのノイズパターン、アイビスペイントのAI学習防止機能、Nightshadeなどがある。
Glaze、emamoriなどの学習妨害ツールは、追加学習された際に反映されにくくするようにするために摂動攻撃を用いられている。
文化庁からは当該技術は対応として有効とされる文言あり。
ただし、モデルが訓練して対策することも可能。
Nightshadeは学習するために収集されたものに向けて「毒」を仕込むデータポイズニングと呼ばれるものを埋め込む技術が用られている。
Nightshadeで施された画像は不正データとして排除してくれる可能性。
(2-4)画像に特殊な画像処理(学習を妨害するノイズ)を施すことで学習を妨げる技術
画像にノイズを加えることで、AI 学習において、別の画像として認識したり、画像認識をできなくする技術であり、関連技術が既に公開されている。
意見募集においても、このような技術を用いて、権利者に無断で学習されることをクリエイター側から妨げることができるようなツールが必要であるとの意見や、学習を防ぐための対策をクリエイター側や企業に課す必要があるとの意見が見られた。
当該技術を施された画像を学習することで、同様の作風の画像を新たに生成することはできなくなるため、権利者において自らの作品が AI 学習の用に供される事態を直接的にコントロールすることができるという観点で、当該技術は有用である。
もっとも、AI 側にノイズによる誤認識を引き起こさせるものであるため、AI 開発者や AI 提供者の業務を妨害することを目的とした悪質な行為については、電子計算機損壊等業務妨害罪(刑法 234 条の2)等の刑事罰の対象となる可能性もあり得ることには留意する必要がある。
引用元:首相官邸ホームページ
ノイズを施すことは有用であると見解があるものの、意図的に攻撃することを目的とされているため、電子計算機損壊等業務妨害罪などに当たらないか確認した上で使用してください。
・生成型検索エンジンとは?
プロンプト(検索したい情報)を打つと代わりに検索したり学習データの中から文章を生成してくれるサービス。
スマートフォンのGoogleで「AIとは」で検索すると、AIによる概要が出てきます。

最後に🔗(引用元)が付いているので情報の正確さはそれなりにある模様。
ただし平気で嘘をつく可能性があるので、参考程度に使うと良いだろう。
Yahooでも似たような機能はあるものの、文章は生成されない。
他にBingとかperplexityあたりも同じことが出来るとのこと。
生成型検索エンジンは、入力クエリに対する応答をインライン引用とともに直接生成することで、ユーザーの情報ニーズを満たす。
クエリはデータの検索などの処理を行うように求める命令文。検索エンジンでキーワードを入れることを検索クエリと言うらしい。
インライン引用は文章を引用して、回答やコメントを挿入する方法。
2024年現在、画像系の生成型検索エンジンはないと思われる。
・Danbooruというサイトについて
アメリカで運営しているアップロードされた画像をタグ付けして分類、これにより検索しやすいようにしてくれるサイトという認識らしい。
引用元のソースが掲載されており、日本の著作権法では第32条第1項の引用に則っており、かつ自国のフェアユース法で「引用」問題ないとされているため、無断転載サイトではないという認識。
画像転載サイトというより、少し前にあったTwitterのイラストをタグ付けして管理していた蒼天画廊と似た位置付けだろう。
オープンソースを公開しているため、類似サイトもある模様。
Danbooruタグというのが優秀で、検索しやすい故にいくつかの生成AIサービスが学習として利用されている。
削除申請をすれば3日程度で削除することは出来るが、作品がどこで掲載されていたかのURLをリストアップする必要がある。
ただし検索エンジンから検索除外されるだけでサイト自体は検索すれば出てくるそう。
DMCA申し立ては弁護士を仲介しないと個人情報が出てしまうので注意されたし。
この手順で仮に作品が消えたとして、既に学習されたものに対してはどうにもならないことは留意すべきである。
我々がNovelAIに関係していないことと、彼らがしてることを、支持はおろか容認もしていないことをはっきりさせたく存じます。
ご自身の描いた絵をNovelAIに利用されたくない絵師様にとって最も効率的な手段は、NovelAIに直接問い合わせをして、 同社の学習データから自分の絵を削除、そしてAIアートを生成する際にユーザーが入力する「プロンプト」(指示文)から自分の名前やハンドルネームを除外するよう、要求することです。
現時点ではNovelAIの学習データはすでに完成しており、AIモデルの構造上、例えDanbooruから絵を削除したところで、その絵から学習された情報がNovelAIの手元から勝手に無くなるわけではありませんので、ご注意ください
・bioに書かれている注意など、同人誌の奥付にある注意書き、個人イラストレーターが掲げているガイドラインについて
法律に関わらない内容はあくまでお願い以上の拘束力が無い。
拘束力を持たせるには、規約を読ませた上で同意したことを示すサインやチェックなどをして双方同意出来る仕組みでなければいけないそう。
X(旧Twitter)のbioはbiographyの略で人物紹介=プロフィールという意味で、契約書の代わりにはならない。
同人誌の注意文にある「オークションサイトやフリマサイトなどの出品を禁じる」「違法行為に対して1ページor1冊につき○万円」について、売る行為に関しては個人による処分行為のため、法律的に問題ないとされている。
違法行為〜云々に関しては金額が適当ではないことから、不当条項にみなされる可能性があるので、書くなら「無断転載については閲覧数×販売価格の金銭を請求させていただく場合があります」辺りなら認められやすいそう(海賊版サイトでの転載や電子書籍のコピー販売など)
「購入をもって○○禁止に同意したものとみなします」と書いて販売することも不当条項にあたる可能性があり、実質拘束力はないそう。
ガイドラインやルールは違法になるかどうかは弁護士や裁判官が判断するため、作者や利用者が強要するものではない。
周知するくらいでとどめましょう。
・ざっくりまとめ
生成AIは現在テキスト、画像、動画、音声など広く使われている。
ボーカロイドとかの合成ソフトはAIにあたらないらしいが、最近生成AIを用いたボーカロイドソフトも出ているとのこと。
検索エンジンや翻訳でも生成AIが組み込まれた機能も出ており、おそらく無意識にAIや生成AIに手を出していると思われる。
画像生成AIはi2tとi2iでプロンプトやネガティブプロンプトを指定してパラメータで調整してイラストを出力している。
スペックがいいパソコンでないと生成するのに時間がかかる上に、ただ生成するのではなく、100%自分が求めているものを追求するならイラスト編集ソフトなどで加工しなきゃいけない。
Webでも生成出来るが無料は生成数などに制限があるため、課金で制限緩和などをしないと大量出力出来ない。
モデルデータには画像そのものが億枚入っているわけではなく、データとして変換されているので10GBなど容量が少ない。
仮に10億枚を圧縮すれば1枚がアルファベット10文字分になってしまい、画像どころじゃなくなる。
自動収集される学習データにウォーターマークも学習妨害ツールも現状大きく効果はない可能性が高く、ウォーターマークに関しては追加学習する方に対して少し効果がある程度。
それでもやりたい場合はウォーターマークやノイズの仕組みを理解して使いましょう。
サインやウォーターマークを入れる場合、見た人が分かるように目立たせること。ウォーターマークは自作した上で公開、配布はしないこと。
学習妨害ツールは自身の作品に使用することは文化庁は有用であると見解があるものの、違法と見られる可能性があるため、リスクを理解した上で利用すること。
2018年に法第30条の4として法整備されたため、イラストを収集して学習させることは著作権違反にはあたらない。
ただし、生成されたAIイラストで類似性や依拠性があれば違法となる可能性がある。
i2iやLoRAを使う時は注意すること。
二次創作に関しては公式の規約や二次創作ガイドラインを読んだ上でアップロード(公開)すること。
二次創作ガイドラインはあくまでお願いであり、強要するものではないが、権利者から注意された場合はすぐ対応しましょう。
SNSは現状、X(旧Twitter)とMeta社が運営するInstagramなどは自サービスで活用する可能性あり。
外部からのクローラー・スクレイピングを対策しているのはTwitter、Misskey、タイッツー辺り。
BlueSkyは自サービスに利用するかどうかは触れておらず、robots.txtではクロールを許可しているため、生成AIによる学習を拒否したい方はおすすめしない。
Danbooruは蒼天画廊と同じ位置付けで、無断転載サイトではない。
引用元があるものの、画像は転載されているため、嫌ならDMCA申し立てや削除申請をすれば3日程度で削除することは出来る。
もしくは作者自らDanbooruに作品をアップロードしてあげましょう。
引用元のソースがある画像データベースサイトで、タグが優秀なため学習環境が整っているが、運営は生成AIに一切関与していないことに留意されたし。
・おわりに
僕なりに色々調べて記事にしていますが、100%正しい情報かと言われると「そうです」とは言えません。
何故ならこの記事はnote主の見解だし、引用した記事などはまとめた方の見解でしかありません。
文化庁など公式で公開されているのも見解の一つとして読んでおいてください。
特に基本知識がない段階では、この記事を読んで鵜呑みせず、生成AI関連や著作権の本を読んだ方がよいでしょう。
インターネットで誰がまとめたか分からん記事だったり、SNSで反AIやAI推進の言葉を眺めるよりきちんと監修された方の本を読んだ方が正しい知識のすり合わせが出来ると思います。
・その他
・カルフォルニア州AI法案で電子透かしが廃案された話
カルフォルニア州で電子透かしを入れる法案、AB 3211が廃案になったらしい話があったのですが、この方の記事で触れている。
小括を読んでみると、
ここで重要なのは、来歴データ(生成AI製含む)は機械可読な、メタデータで十分であるということであり、そのコンテンツを閲覧もしくは視聴する際に人間に感知できるようにすることまでは求められず、専ら別画面で見れるようにすれば足りるということでしょう。
そもそもAIで生成されたものにも既存の画像と同じようにメタデータがあって、バイナリエディタで見れるから電子透かしはいらないよね。という感じらしい。
ちなみに、Adobeはコンテンツ・クレデンシャルを使ってコンテンツ認証情報を添付したもので、作成者の情報とどう作成され編集されたかの背景情報を成分表示ラベルのようなもので作品に付与できる安全なメタデータが付与出来るものが既にある。
それを活用したAdobe Content Authenticity(アドビ・コンテンツ・オーセンティシティ)という無料のwebアプリを2024年11月〜2025年2月末の四半期中に無料パブリックベータ版を提供予定。
Generative AI Training and Usage Preference(生成AIのトレーニングと使用に関する設定)機能を使って、作品に生成AIモデルのトレーニングに使用されないように意思表示することが出来るとのこと。
・AI関連のテスト
人間か描いたイラストか、生成AIで出力されたイラストかを見分けるかどうかをテストするサイト
・人間かAIか?
URL:https://docs.google.com/forms/d/e/1FAIpQLSdhEpBRnOwiFI-ieNKKu3Y0KcoFbd_ZWod1LeyoV6EEfY78HA/viewform
・人間かAIか?2
URL:https://docs.google.com/forms/d/e/1FAIpQLSenOv7USGsYGqsx8dGaSCCkGlhTY43Puxi9D20a2Q0U3kyZ4g/viewform?pli=1
生成AI関連の著作権についての理解度を調べるサイト
・画像生成AIリテラシー検定問題
・参考にした本やサイト
・本(Amazonサイト)
・AI関連
・著作権関連
・その他
文化庁 AIと著作権Ⅱ(PDF)
https://www.bunka.go.jp>seisaku>chosakuken>pdf
・AI問題の記事(ニュース、ブログ)
星新一賞を受賞したAI小説家葦沢かもめさんインタビュー | 小説もAIで執筆する時代になる? AIが拓く未来とは
・今まで書いた生成AI関連の記事
この記事が気に入ったらサポートをしてみませんか?