
顔LoRAで好きな顔の生成画像を作る

自分の好きな顔で生成画像が作れれば楽しいはず。
今回は好きな画像で顔LoRAを作る方法です。
顔LoRAを作ってしまえばあとはいつものように画像生成するだけ。
今回はsd-script v0.8.7を使用したローカルでの環境構築です。
<必須環境>
GPU(VRAM 4GB以上)
Python 3.10.6(anaconda)
git for windows
CUDA(11.8)
cuDNN
上記環境が必須ですのでインストールされていない場合は、先にインストールしてください。
インストール手順
(1)インストールディレクトリ(フォルダ)の作成
上記のディレクトリを作成してください。
c:\deepfake
(2)sd-scriptのダウンロード
anaconda promptを開き、カレントを先のディレクトリに移動します。
cd c:\deepfake
(base) c:\deepfake>
カレントがc:\deepfakeになったら以下コマンドを実行します。
(コピペしてください)
git clone https://github.com/kohya-ss/sd-scripts.git
※少し時間がかかります
(3)python仮想環境の作成
先のanaconda prompt上で以下コマンドを入力します。
cd sd-script
(base) c:\deepfake\sd-script>
カレントがsd-scriptになったら以下を実行します。
python -m venv venv
sd-scriptフォルダ配下にvenvというフォルダが作成されていればOK
(4)python仮想環境のアクティベート
同じプロンプト上で以下コマンドを実行
.\venv\Scripts\activate
表示が以下のように(venv)が付けばOKです。
(venv)(base)c:\deepfake\sd-script>
(5)torchのインストール
プロンプト上で以下コマンドを実行
pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu1183GB弱のファイルをダウンロードするので少し時間かかります。
(6)sd-scriptのインストール
プロンプト上で以下コマンドを実行
pip install --upgrade -r requirements.txt諸々のライブラリをダウンロードしながらインストールされるため、
ここも少し時間がかかります。気長に待ちましょう。
最後に以下が出る場合ありますが気にしなくてOKです。
pipというライブラリをアップデートできるよという通知です。
[notice] A new release of pip available: 22.3.1 -> 24.2
[notice] To update, run: python.exe -m pip install --upgrade pip
(7)xformersのインストール
プロンプト上で以下コマンドを実行
pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu118ここもダウンロードしてからインストールが行われます。
(8)tritonのインストール
ここからWindows builds of triton 2.1.0のPython 3.10のファイルを以下フォルダにダウンロードしてください。

ファイル保存先
c:\deepfake
保存出来たらプロンプトで以下コマンドでインストールしてください。
pip install c:\deepfake\triton-2.1.0-cp310-cp310-win_amd64.whl
必要なソフトウェアのインストールはこれで終わりです。
accelerateのコンフィグ作成
(1)コンフィグ作成
同じプロンプト上で以下コマンドを実行
accelerate config
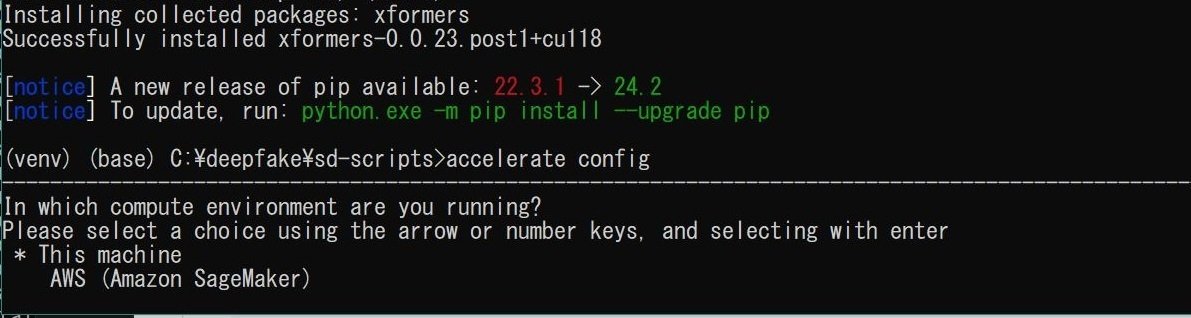
こんな画面表示になります。
各問いは以下のように回答してください
*マークがついているのが選択された回答です。画面ではThis machine
キーボードのカーソルで上下し、エンターで確定です。
This machine
No distributed training
NO
NO
NO
all
fp16
7項目終わるとコンフィグがセーブの表示が出ればOKです。
間違えたらもう一度accelerate configを実行し、やり直してください。
LoRA作業フォルダの作成
(1)LoRAフォルダ作成
c:\deepfake配下に以下のLoRAフォルダ作成
c:\deepfake\LoRA
(2)データや出力用のフォルダ作成
先で作成したLoRAフォルダ配下に以下3つのフォルダを作成
checkpoints
data
output
(3)checkpointsフォルダ配下にSDXLフォルダを作成
checkpointsフォルダにSDXLフォルダを作成します。
SDXL
以下のような形になっていればOKです。
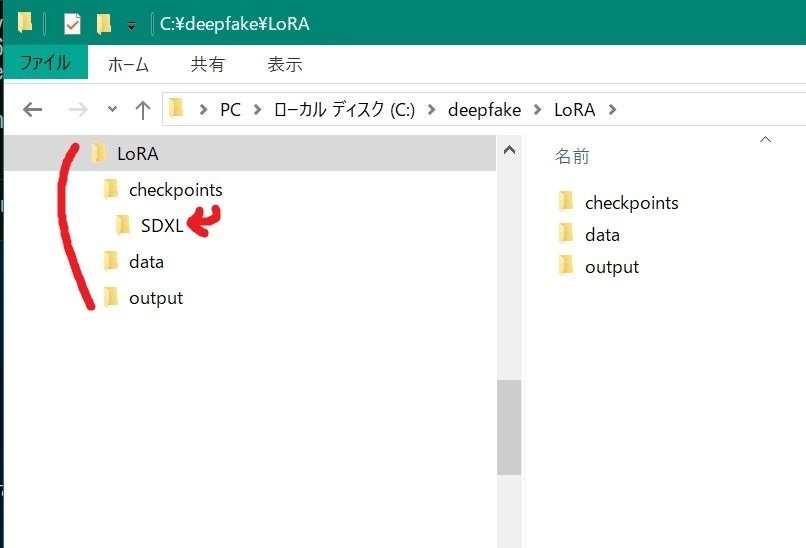
c:\deepfake\LoRA\checkpoints\SDXL
c:\deepfake\LoRA\data
c:\deepfake\LoRA\output
SDXLは学習時に使うSDXLのモデルファイルを保存する場所
dataは学習に使う顔写真を保存する場所
outputはsd-scriptで生成したLoRAファイルを保存する場所
SDXLモデルファイルのダウンロード
SDXLのモデルファイルをダウンロードしてください。
スクロールするとこの項目が出てきます。

sd_xl_base_1.0.safetensors のダウンロードボタンをクリックしてダウンロードしてください。
c:\deepfake\LoRA\checkpoints\SDXL
ここに保存してください。尚、7GB程あるのでダウンロードには時間がかかります。
顔写真の準備
SDXLモデルで学習させるため、顔写真は1024x1024としてください。
また10枚から15枚ほど準備してください。
保存先は先ほど作ったc:\deepfake\LoRA\dataに保存してください。
学習用定義ファイルの作成
以下フォルダに下記内容をコピペしたファイルを保存してください。
c:\deepfake\LoRA\config.toml
UTF-8(ボム無し)で保存
[general]
[[datasets]]
[[datasets.subsets]]
image_dir = 'c:\deepfake\LoRA\data' # 学習用画像を入れるフォルダ
class_tokens = 'faceHANA241026 woman' # identifier class
num_repeats = 10 # 繰り返し回数
class tokensは任意の名前に変更してOKです。
学習開始
プロンプト上で以下コマンドを実行してください。
(長いですが1行で入力してください)
accelerate launch --num_cpu_threads_per_process 1 sdxl_train_network.py --pretrained_model_name_or_path=C:\deepfake\LoRA\checkpoints\SDXL\sd_xl_base_1.0.safetensors --dataset_config=C:\deepfake\LoRA\config.toml --output_dir=C:\deepfake\LoRA\output --output_name=faceHANA241026 --save_model_as=safetensors --prior_loss_weight=1.0 --resolution=1024,1024 --train_batch_size=1 --max_train_epochs=20 --learning_rate=1e-4 --xformers --mixed_precision="fp16" --cache_latents --gradient_checkpointing --network_module=networks.lora --no_half_vae
太字の部分は自身の環境に合わせてください。
パス等をシングルコーテーションで囲うと実行エラーになります。
SDXLモデルで顔写真を11枚で2200ステップをRTX3080で実行すると約半日ほどかかりました・・・
生成されたLoRAファイルの使い方
生成が終了すると
c:\deepfake\LoRA\output
に
というファイルが生成されますのでこのファイルをそれぞれのLoRAフォルダにコピーして使ってください。
尚、SDXL対応しているモデルしか使えないので注意してください。
SD1.5などでは使えません。
この記事が気に入ったらサポートをしてみませんか?