
画像1枚からtiktok動画ような動画生成できるDisPoseのインストール手順

必須環境
(1)ハードウェア
gpu(Nvidia)
※超重要※VRAMたっぷり必要らしく4090でも厳しいらしいです。
(2)ソフトウェア
python(3.10系)
git for windows
visual studio code
CUDA Toolkit(12.4以上)
cuDNN(CUDAに対応したバージョン)
※torch v2.5+cuda12.4を想定
インストール手順
(1)インストールディレクトリの作成
c:\aiを作ります。そしてプロンプトを開き、以下ディレクトリに移動する
cd c:\ai
(base) c:\ai>(2)DisPoseのクローン
以下コマンドでクローンする
git clone https://github.com/lihxxx/DisPose.git完了するとDisPoseフォルダが作成されているのでプロンプトをそのフォルダに移動します。
cd DisPose
(base) c:\ai\DisPose>こんな具合になっていればOKです。
(3)仮想環境の作成
プロンプトにて以下コマンドを入力し仮想環境作成します。
(base) c:\ai\DisPose>
(base) c:\ai\DisPose>python -m venv venv
(venv) c:\ai\DisPose>c:\ai\disposeフォルダ内にvenvフォルダが作成されていれば成功です。
プロンプトは引き続き使うのでそのままにしておいてください。
(4)仮想環境のアクティベート
先のプロンプトで以下コマンドを入力し仮想環境をアクティベートします。
(base) c:\ai\DisPose>
(base) c:\ai\DisPose>.\venv\Scripts\activateプロンプトが以下に変わっていればOKです。
(venv) (base) c:\ai\dispose>(5)ライブラリバージョンの変更
c:\ai\dispose配下の「requirements.txt」を開き、以下のように書き換えてください。
変更前
accelerate
torch
torchvision
Pillow
numpy
omegaconf
decord
einops
matplotlib
diffusers==0.27.0
scipy
av==12.0.0
imageio
opencv_contrib_python
transformers
huggingface_hub==0.25.2
onnxruntime
変更後
--extra-index-url https://download.pytorch.org/whl/cu124
--extra-index-url https://files.pythonhosted.org/packages/d6/54/e2fb1eadc21b6f8347860e9d53ad0ed34fec462cf51ab1b4303027503706/onnxruntime_gpu-1.20.1-cp310-cp310-win_amd64.whl
accelerate
torch==2.5.0
torchvision==0.20.0
torchaudio==2.5.0
Pillow
numpy
omegaconf
decord
einops
matplotlib
diffusers==0.27.0
scipy
av==12.0.0
imageio
opencv_contrib_python
transformers
huggingface_hub==0.25.2
onnxruntime-gpu==1.20.1(6)ライブラリインストール
以下コマンドでライブラリのインストールを行います。
(venv) (base) c:\ai\dispose>pip install -r requirements.txt環境によりますが数ギガサイズのファイルダウンロード等もあり30分ほどかかる場合あります。気長にお待ちください。
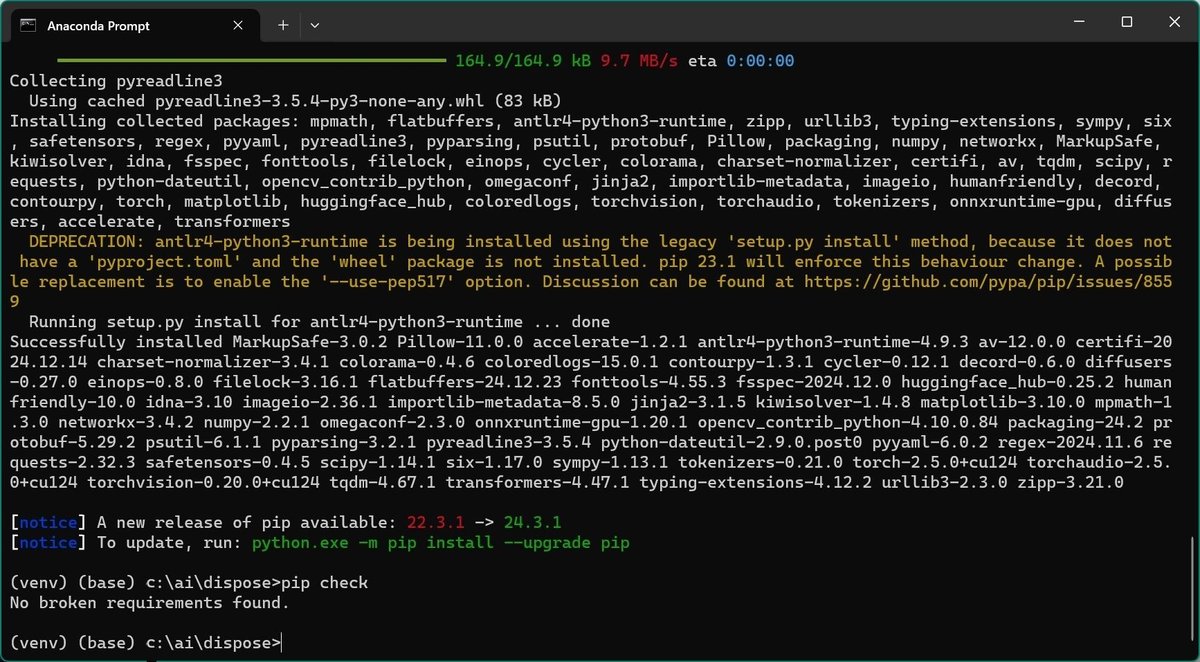
※最後にエラーが無いか確認(pip check)していますがこんな画面になっていればOKです。
(7)モデルファイル用のフォルダ作成
(a)pretrained_weightsフォルダ作成
Disposeフォルダ配下にpretrained_weightsという名前でフォルダを作成します。
(b)dwposeフォルダ作成
次に今作成したpretrained_weightsフォルダの下にdwposeという名前でフォルダを作成します。
2つのフォルダが作成出来たら以下になっていることを確認してください。
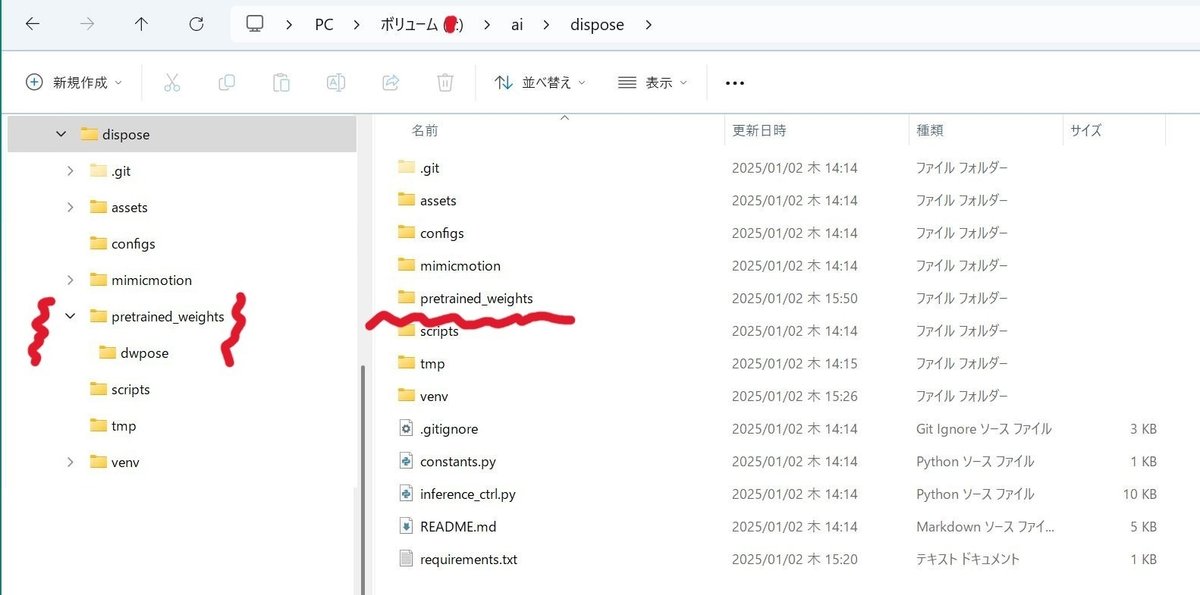
(8)チェックファイル用フォルダの作成
今度はかなり深い場所ですが以下にcheckpointsという名前でフォルダを作成してください。
c:\ai\dispose\mimicmotion\modules\cmp\experiments\semiauto_annot\resnet50_vip+mpii_liteflow以下のような構成にしてください。

(9)モデルウェイトのダウンロード
(a)dispose.pthのダウンロード
以下サイトに移動し、Files and Versionsタブに移動します。
以下画面になるのでDisPose.pthをダウンロードしてください。

ダウンロード出来たら(7)で作成したpretrained_weightsフォルダに保存してください。
(b)stable-video-diffusion-img2vid-xt-1-1のダウンロード
以下サイトに移動してください。
モデルファイル利用のために同意が必要なため、まずhuggingfaceにログインしてください。なお、アカウントが無い方は無料で作成できますのでアカウント作成を行ってください。

ログインすると画面中央のライセンス内容が読めるようになるので
Expand and review and accessをクリックし内容確認(飛ばして)してください。

submitするとFilesに移動します。

一括ダウンロード出来ればいいんですがgit cloneできなかったので手間ですが1つずつフォルダ構成はそのままで全ファイルをダウンロードしてください。
ダウンロード出来たらこのファイルも(7)で作成したpretrained_weightsフォルダに保存してください。
(c)dwposeのダウンロード
以下から2つのファイルをダウンロードしてください。
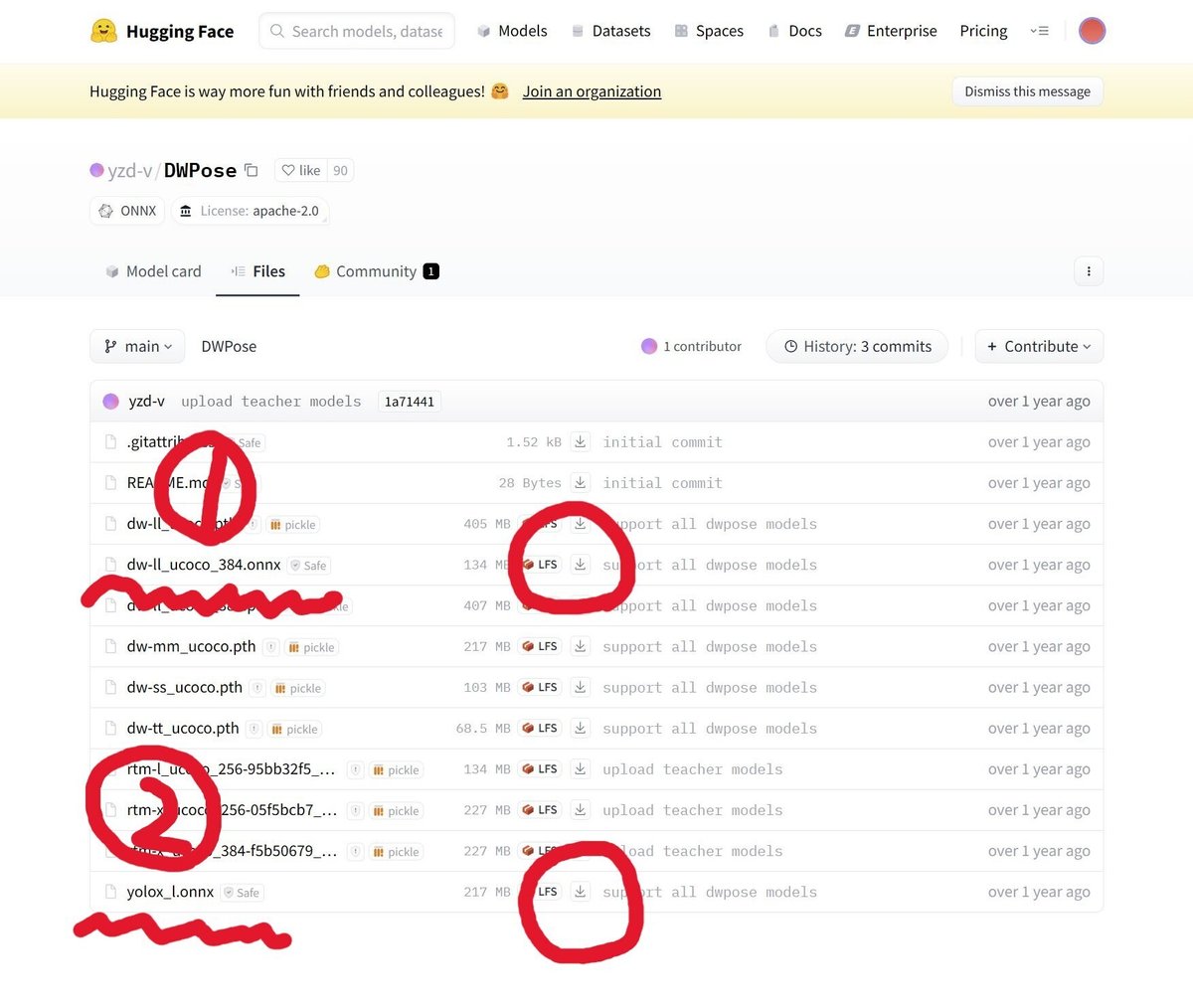
2つダウンロード出来たらこのファイルも(7)で作成したdwposeフォルダに保存してください。
(d)stable-diffusion-v1-5のダウンロード
プロンプトからダウンロード(クローン)します。
まずプロンプトのカレントをpretrained_weightsにしてください。
(venv) (base) E:\ai\dispose>cd pretrained_weights
(venv) (base) E:\ai\dispose\pretrained_weights>以下コマンドでクローンしてください。
git clone https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5環境によりますが場合によっては完了するまで1時間ほどかかる場合ありますので気長にお待ちを・・・(完了するとプロンプトが返ってきます)
(e)MimicMotion_1-1.pthのダウンロード
以下サイトに移動し、MimicMotion_1-1.pthをダウンロードします。
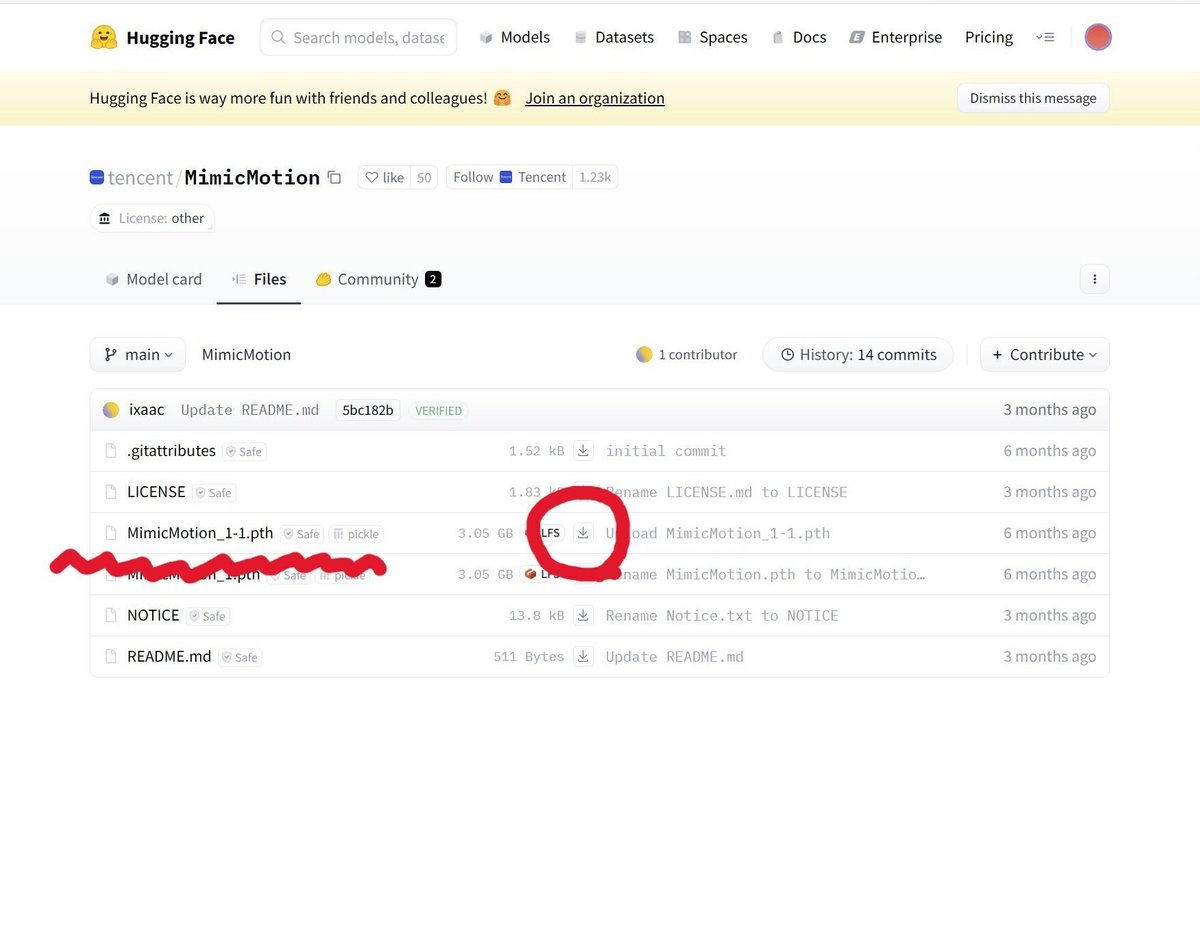
ダウンロード出来たらこのファイルも(7)で作成したpretrained_weightsフォルダに保存してください。
(f)checkpointsファイルをダウンロード
以下からckpt_iter_42000.pth.tarをダウンロードします。
ダウンロードできたら(8)で作成したcheckpointsフォルダに保存します。
ダウンロードしたファイルはtar形式になっているため、tar展開を行います。
エクスプローラでckpt_iter_42000.pth.tarを右クリックします。
メニューから「すべて展開」を選び、展開します。

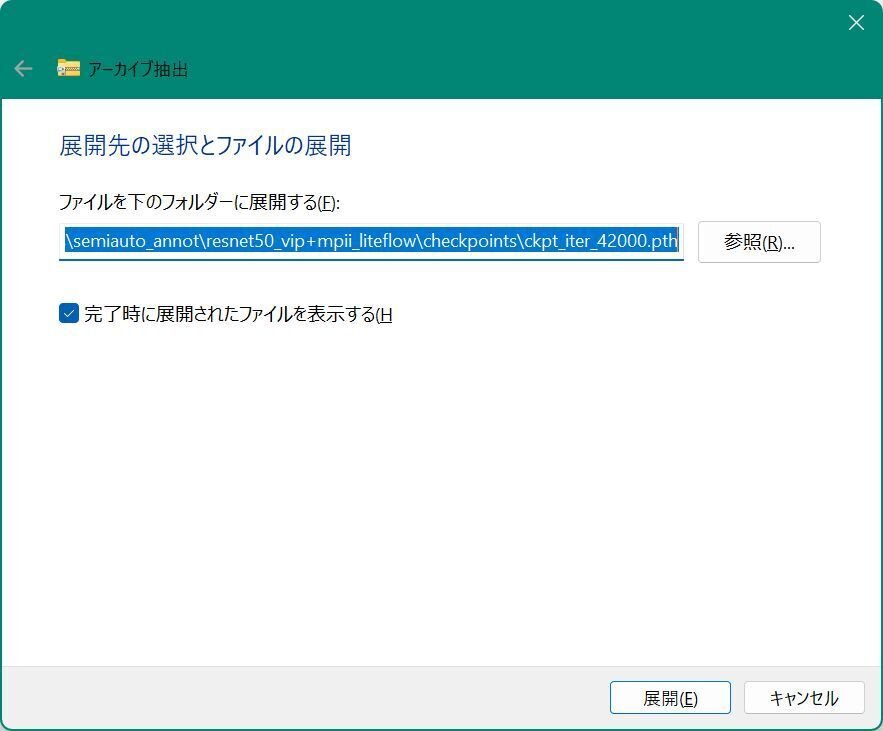
展開が終わるとckpt_iter_42000.pthというフォルダが出来、その中に「ckpt_iter_42000.pth」展開されます。(少しややこしいですが)
「ckpt_iter_42000.pth」フォルダにある「ckpt_iter_42000.pth」ファイルをcheckpointsフォルダに移動させる必要がありますが、そのままやろうとするとエラーになるため、まず「ckpt_iter_42000.pth」フォルダをtmpにリネームしてください。
tmpフォルダ内にある「ckpt_iter_42000.pth」をcheckpointsに移動させます。
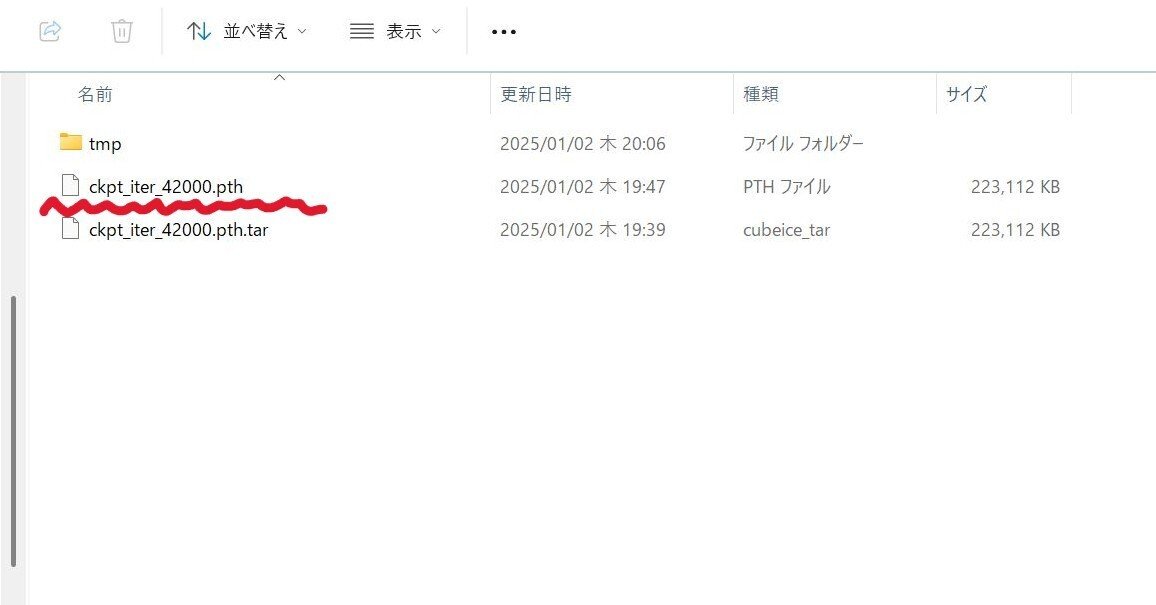
この状態になっていると思うので、ckpt_iter_42000.pth以外は不要なので削除してください。

多分環境は出来た・・・
でもここからの使い方がワカラナイ笑
github見ると4090でもVRAM足りないらしく3080では到底動かないんだろうな・・・VRAM低減?するオプションdecode_chunk_sizeを入れるとよいらしいけどどうなんだろうね。。。