
無料でできる「AIリネーム1.5」生成AIで画像ファイルに中身のわかるファイル名をつけよう! Google Geminiがお役にたちます。ソースコード公開中

こんにちは!
ノーリーです。ClaudeやChatGPT、Gemini使ってますか?
折角の生成AIを日頃のイライラ解消に使ってみませんか?
AIがあなたの画像ファイルに中身がわかるファイル名をつけてくれますよ。
私は自分のPCにある、記号の羅列の画像ファイルが気に食いません。
ファイル名では中身がわからず、整理できないからです。
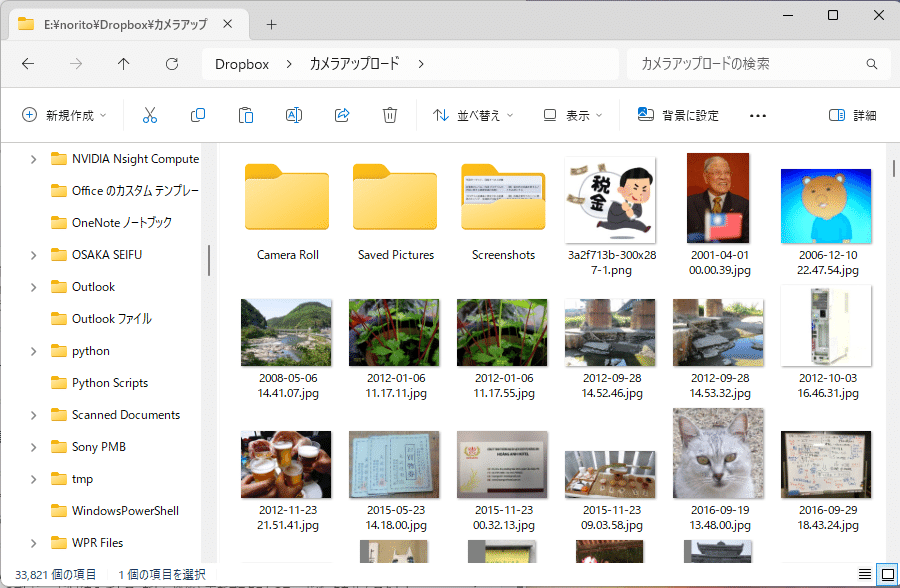
しかし、いちいち開けて確認するのも面倒過ぎ。
まして、その中身に沿ったファイル名をつけるのなんか気が遠くなります。
そういうわけで、何百何千ものファイルが放置されていました。
このイライラを生成AI Gemini で解決します。
なんと、無料で1日1500枚まで名付けできます。
ようやく、Geminiが役に立ちました!
この記事は、大阪のIT専門学校「清風情報工科学院」の校長・平岡憲人(ノーリー)がお送りします。
清風情報工科学院では、情報処理系の講師を急募しております。
ご興味のある方はこちらの記事を御覧ください。
1.「AIリネーム1.5」でできること
指定したフォルダーの中にある画像ファイルを、生成AIの画像キャプション能力を使って、中身のわかるファイル名にリネームしていくこと。

今回は、Google Geminiバージョンです。
Claude Haikuは有料でしたが、Geminiは無料で動きます。
取り急ぎ公開するので、開発環境がないと動きません。
時間に余裕がある時に、アプリにするつもりです。
まずは、生成AIに興味ある方にお届けします。
必要なもの
・Google Gemini のAPIキー
(・ClaudeのAPIキー)
・Python
・CursorまたはVSCodeの開発環境
処理内容
処理の冒頭で対象フォルダの選択と、利用する生成AIモデルの選択を行う。
フォルダ内の画像ファイルを生成AIのAPI(Gemini API)に送り、制限付きながら無料の生成AIであるGemini 1.0 Pro Vision のビジョン機能を使って、画像のキャプションを片っ端からつけていく。
そのフォルダに「processed_files.csv」というファイルでリネームの記録を残す。
Gemini 1.0 Pro Vision には、毎分15回までというリクエスト制限がある。
わざわざウェイトを入れて4秒に1回動作するようになっている。
100分で1500枚処理可能。
なお、Geminiを有料モードで使えば、1秒間に最大360枚処理できる(ソースコードの改良が必要)。
実行結果
Gemini 1.0の場合
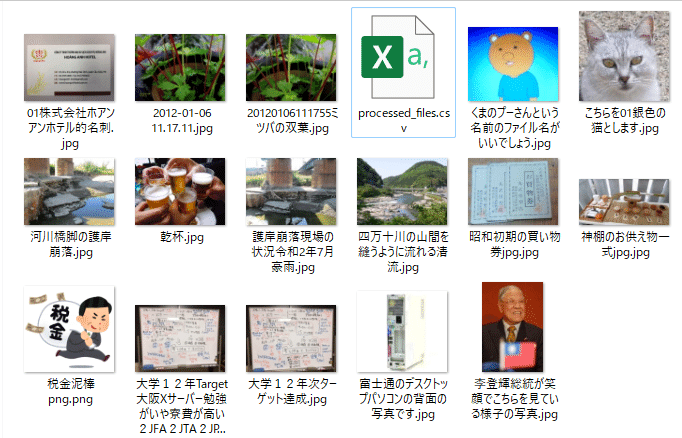
Gemini 1.5の場合

Claude Haikuの場合

見比べると、全般的にはClaude Haikuのほうが優秀かなと思われます。
下手な決めつけがないところが謙虚でよいです。
もっとも、税金泥棒の解釈は逆になっており、台湾の李登輝総統のことは知らないようです。
Gemini 1.0は全般的にハルシネーション気味です。
パソコンの背面画像を勝手に「富士通の」としたり、護岸崩落現場の状況の「令和2年7月豪雨」は誤りです。
昭和初期の買い物券も誤りです。
「くまのプーさんという名前のファイル名がいいでしょう」とか「大学12年Target大阪Xサーバー勉強がいや寮費が高い2JFA2JTA2JPR」とか、中途半端なファイル名も見られます。
無料なんでしょうがない、数字のファイル名よりはマシと割り切りましょう。
Gemini 1.5は、おおむねClaude Haikuと同等のクオリティです。
Gemini 1.0のハルシネーション癖はましになったと言えます。
結論として、より正確につけたいなら Claude Haiku、コスト重視なら Google Gemini 1.0です。
2.ソースコード
このプログラムは、自由に使うことができます。
改変も自由です。
CC BY-SA 表示 - 継承 4.0 国際 に従って下さい。
ここにソースコードを貼りますね。
言語は、Pythonです。
生成AIは、Anthropic Claude 3 Haiku、Google Gemini 1.0 Pro Vision、Google Gemini 1.5 Proに対応しています。
一番コアなプロンプトは
「この画像に日本語で50字程度のファイル名をつけて」
というシンプルなものです。
"""
AIリネーム 生成AIで画像ファイルに中身のわかるファイル名をつけよう! 生成AIがイライラを解消
指定されたフォルダ内の画像ファイルに、AIを使用してキャプションを生成し、ファイル名をリネームする
Claude 3 Haiku, Gemini 1.0 Pro Vision, Gemini 1.5 Pro対応
2024/4/16 Version 1.0 HIRAOKA Norito CC BY-SA 表示 - 継承 4.0 国際
2024/4/28 Version 1.5 HIRAOKA Norito CC BY-SA 表示 - 継承 4.0 国際
"""
import anthropic
import google.generativeai as genai
import os
import time
import base64
import csv
from PIL import Image
import tkinter as tk
from tkinter import filedialog, messagebox
def get_config(vendor):
configs = {
"CLAUDE": {
"api": "anthropic",
"model_name": "claude-3-haiku-20240307",
"generation_config": {
"max_tokens": 100,
"temperature": 0.0,
"system" : "",
},
"prompt_template": lambda data, media_type: [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": f"image/{media_type}",
"data": data
}
},
{
"type": "text",
"text": "この画像のファイル名を日本語で50字以下でつけて\n"
}
]
}
],
"result_path": lambda response: response.content[0].text,
"requests_per_minute": 5, # 階層2なら1000, 階層1なら50, 無料なら5
"requests_per_day": 1000000, #無料なら7200
},
"GEMINI_1_0_PRO_VISION": {
"api": "genai",
"model_name": "gemini-1.0-pro-vision-latest",
"generation_config": {
"max_output_tokens": 4096,
"temperature": 0.4,
"top_p": 1,
"top_k": 32,
},
"prompt_template": lambda data, media_type: [
f"この画像に日本語で50字程度のファイル名をつけて",
{
"mime_type": f"image/{media_type}",
"data": data
}
],
"result_path": lambda response: response.text,
"requests_per_minute": 15, #無料版15, 従量版360
"requests_per_day": 1500, #無料版1500, 従量版30000
},
"GEMINI_1_5_PRO": {
"api": "genai",
"model_name": "gemini-1.5-pro-latest",
"generation_config": {
"max_output_tokens": 8192,
"temperature": 1,
"top_p": 0.95,
"top_k": 0,
},
"prompt_template": lambda data, media_type: [
{
"role": "user",
"parts": [
{
"inline_data": {
"mime_type": f"image/{media_type}",
"data": data
}
}
]
},
{
"role": "user",
"parts": [f"この画像に日本語で50字程度のファイル名をつけて。手順の説明なし。ファイル名だけ答えて。"]
}
],
"result_path": lambda convo: convo.last.text,
"requests_per_minute": 2, #無料版2, 従量版5
"requests_per_day": 50, #無料版50, 従量版2000
"safety_settings": [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
],
},
}
if vendor is None:
return {"configs": configs}
else:
return configs[vendor]
def get_caption(image_path, model_config):
try:
with Image.open(image_path) as img:
if img.format not in ["JPEG", "PNG", "GIF"] or max(img.size) > 1000:
img.thumbnail((1000, 1000))
temp_image_path = os.path.join(os.path.dirname(image_path), "temp_image.png")
img.save(temp_image_path, "PNG")
media_type = "png"
print("サムネールを作りました")
else:
temp_image_path = image_path
media_type = img.format.lower()
print("サムネールは作りません")
except IOError:
print(f"Error: Unable to open {image_path}")
raise
with open(temp_image_path, 'rb') as file:
data = base64.b64encode(file.read()).decode('utf-8')
print("Base64エンコードしました")
if temp_image_path != image_path:
os.remove(temp_image_path)
print("一時ファイルを削除しました 🗑️")
if model_config["api"] == "anthropic":
client = anthropic.Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
generation_config = model_config.get("generation_config", [])
prompt = model_config["prompt_template"](data, media_type)
response = client.messages.create(model=model_config["model_name"],
**generation_config, messages=prompt)
caption = model_config["result_path"](response)
elif model_config["api"] == "genai":
genai.configure(api_key=os.environ["GEMINI_API_KEY"])
generation_config = model_config.get("generation_config", [])
safety_settings = model_config.get("safety_settings", [])
model = genai.GenerativeModel(model_name=model_config["model_name"],
generation_config=generation_config,
safety_settings=safety_settings)
prompt = model_config["prompt_template"](data, media_type)
if model_config["model_name"] == "gemini-1.5-pro-latest":
convo = model.start_chat(history=prompt)
# print(convo)
convo.send_message("YOUR_USER_INPUT")
caption = model_config["result_path"](convo)
else:
response = model.generate_content(prompt)
# print(response)
caption = model_config["result_path"](response)
return caption[:50]
def main(folder_path, model_name):
model_config = get_config(model_name)
matching_files = [f for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))]
num_files = len(matching_files)
if num_files > model_config["requests_per_day"]:
confirm = tk.messagebox.askokcancel("確認", f"処理対象のファイル数が{num_files}個あります。\n1日のリクエスト制限({model_config['requests_per_day']})を超えますが、続行しますか?")
if not confirm:
return
processed_files = []
csv_file_path = os.path.join(folder_path, 'processed_files.csv')
try:
with open(csv_file_path, 'r', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
processed_files = [row['original_filename'] for row in reader if row['new_filename'] != 'Skipped']
with open(csv_file_path, 'r', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
processed_files = processed_files + [row['new_filename'] for row in reader if row['new_filename'] != 'Skipped']
print("以前にRenameした記録がありました")
print(processed_files)
except FileNotFoundError:
processed_files = []
with open(os.path.join(folder_path, 'processed_files.csv'), 'a', newline='', encoding='utf-8') as csvfile:
fieldnames = ['original_filename', 'new_filename', 'remarks']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
print("新たにRename記録を作成します")
print("---------------------------------------------")
print("Selected folder: "+ folder_path)
print("---------------------------------------------")
print("対象ファイル数: " + str(len(matching_files)))
print("---------------------------------------------")
with open(os.path.join(folder_path, 'processed_files.csv'), 'a', newline='', encoding='utf-8') as csvfile:
fieldnames = ['original_filename', 'new_filename', 'remarks']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
i = 0
for filename in matching_files:
i = i+1
if filename not in processed_files:
try:
if not any(char >= '\u4e00' and char <= '\u9fff' for char in filename):
image_file_path = os.path.join(folder_path, filename)
print("■" + str(i) + " File: " + filename)
caption = get_caption(image_file_path, model_config)
new_filename = "".join(e for e in caption if e.isalnum()) + os.path.splitext(filename)[1]
print("修正候補: " + new_filename)
renamed_filename = new_filename
renamed_file_path = os.path.join(folder_path, new_filename)
if os.path.exists(renamed_file_path):
print("同名のファイルがありました")
i = 1
while True:
renamed_filename = f"{os.path.splitext(new_filename)[0]}({i}){os.path.splitext(new_filename)[1]}"
renamed_file_path = os.path.join(folder_path, renamed_filename)
if not os.path.exists(renamed_file_path):
break
i += 1
os.rename(os.path.join(folder_path, filename), renamed_file_path)
writer.writerow({'original_filename': filename, 'new_filename': renamed_filename, 'remarks': 'Renamed'})
else:
os.rename(os.path.join(folder_path, filename), renamed_file_path)
writer.writerow({'original_filename': filename, 'new_filename': renamed_filename, 'remarks': 'Renamed'})
print(filename + " -> " + renamed_filename)
time.sleep(60 / model_config["requests_per_minute"])
continue
else:
print(str(i) + f" Skipping kanji file name: {filename}")
writer.writerow({'original_filename': filename, 'new_filename': 'Skipped', 'remarks': 'Kanji file name'})
continue
except Exception as e:
if "Rate limit exceeded" in str(e):
print(f"Error: Rate limit exceeded for {filename}")
writer.writerow({'original_filename': filename, 'new_filename': 'Untitled', 'remarks': 'Rate limit exceeded'})
time.sleep(60 * 60) # 1時間待機
continue
else:
print(f"Error: {str(e)}")
writer.writerow({'original_filename': filename, 'new_filename': 'Skipped', 'remarks': 'Skipped due to error'})
continue
else:
print(str(i) + f" Skipping already processed file: {filename}")
writer.writerow({'original_filename': filename, 'new_filename': filename, 'remarks': 'Already processed'})
continue
print("---------------------------------------------")
print("Rename finished.")
if __name__ == "__main__":
folder_path = filedialog.askdirectory(title="フォルダーを選択してください")
available_models = list(get_config(None)["configs"].keys())
default_model_index = available_models.index("GEMINI_1_0_PRO_VISION")
print("使用するモデルを選択してください:")
for i, model in enumerate(available_models, start=1):
print(f"{i}. {model}")
while True:
try:
selected_index = input(f"モデルの番号を入力してください (デフォルト: {default_model_index + 1}): ")
if selected_index == "":
selected_index = default_model_index
else:
selected_index = int(selected_index) - 1
if 0 <= selected_index < len(available_models):
model_name = available_models[selected_index]
break
else:
raise ValueError()
except ValueError:
print("正しい番号を入力してください。")
main(folder_path, model_name)Windows環境で動作確認しています。
Macでも動くと思いますが、確認していません。
Gemini 1.5 Proでも利用できますが、おまけとお考え下さい。
1分間に2枚までで、1日50枚までしか処理できないからです。
有料版にすれば、1分間に2000枚まで処理できるようになります。
ClaudeのAPIキーは、環境変数の「ANTHROPIC_API_KEY」に、GeminiのAPIキーは、環境変数の「GEMINI_API_KEY」に、設定しておいて下さい。
動作などに問題がありましたら、コメントにてお知らせ下さい。
3.備考
GeminiのAPIキーの調達方法
GeminiのAPIキーの取得方法は、次のように行います。
Google AI Studio を開いて「Get API Key」から「API keys」の「Create API key」で取得できます。
くわしい方法は、次の記事を御覧ください。
Google AI Studioについては次の記事を御覧ください。
取得したAPIキーは、手元のPCの環境変数の「GEMINI_API_KEY」に設定します。
・「スタート」→検索→「環境変数の編集」を検索して開く
・ユーザーの環境変数→新規を選択
・変数名 にGEMINI_API_KEY、変数値に取得したAPIキーを貼付けOKを押す。
・ログインしなおして環境変数を適用させる。(新規作成した環境変数は、ログインしなおさないと適用になりません)
やり方は、次の記事など参考になさって下さい。
Cursorの導入方法
Microsoftがオープンソースで作って公開しているVisual Studio Code(VSCode)という開発者用のエディタがあります。
これにAI機能を組み込んで、電動アシスト自転車の要領で、AIアシストエディタにしてしまったのがCursorです。
私は、生成AI塾の元木さんに教えてもらい、現在ではCursorなしの開発は考えられないくらい愛用しています。
また、開発に使うだけでなく、企画書など書く時にも使い始めています。
これを機会に、使ってみられてはいかがでしょうか。
Python
Pythonは、MicrosoftがExcelの中に組み込んでしまった注目の言語です。
Pythonは、現代における「BASIC」の位置にあります。
マイコンの黎明期には、BASIC。
その後、Visual Basic。
いま、Pythonです。
インタープリタという共通点があります。
専門家の領域では、AI関係の開発、データ分析などに使われています。
生成AIに興味のある方は、この際、Pythonに挑戦なさって下さい。
この動画では、開発環境として上に述べたVSCodeが使われています。
VSCodeの設定とCursorの設定はほぼ同じなので、VSCodeの説明をCursorに読み替えてご覧ください。
コスト
1枚あたりいくらくらい費用がかかるか。
Google Gemini 1.0を使えば無料です。
ただし、次のような制限があります。
1分間あたり15枚まで
1日あたり1500枚まで
そして、送った画像はGeminiの学習に使われます。
ですので、秘密の写真など送らないで下さいね。
有料モードにすると、送った画像はGeminiの学習に使われなくなります。
費用は画像1枚$0.0025です。1000枚で$2.5=400円、1枚0.4円です。
Gemini 1.5でも、画像1枚$0.00265とほとんど変わりません。
ただし、Gemini 1.0 Proの品質であれば、課金する価値は低いです。
無料モードで何回かに分けて実行していけばよいのではないでしょうか。
そう遠くない内に、こういう機能はOSの標準機能になると予想します。
4.まとめ
以上、「AIリネーム1.5」の簡単な説明でした。
役に立ったら「いいね」お願いします!
本校・清風情報工科学院では、生成AIを活用した教育に取り組んでいます。
昨年度は、IT教育の主にシステム開発のところに使っていました。
今年度は、画像生成や日本語教育でも使っていきます。
ご興味がある方、本校で教鞭をおとりになりませんか?
清風情報工科学院では、情報処理系の講師を急募しております。
こちらの記事を御覧ください。
いいなと思ったら応援しよう!
