
Webスクレイピングでlifehackerの新着記事を取得する

1.使用言語・ライブラリ・環境
言語:Python3.9.10
標準ライブラリ:re
外部ライブラリ:BeautifulSoup・requests
端末:mac book air (macOS Monterey 12.3)
エディタ:Visual Studio Code
Google Colaboratoryなら、初めからBeautifulSoupもrequestsも利用可能。環境構築も不要です。
2.抽出方法を考える(検証ツール)
lifehackerのサイトを開いて、GoogleChromeの検証ツールを使って抽出方法を検討します。
今回は新着記事が欲しいので、新着記事ページで考えます。

HTMLのソースコードが出てきますので、これを頼りに記事タイトルとURLを削り取る方法を考えていきます。

なお、いきなりソースコードを抽出してしまって徐々に削り取っていくやり方もあります。(僕は割とそうやってます)
blck_iblock__10Z4- というclass属性を保有するdivタグが一番大きな外枠であるとわかりますが、さらに展開すると・・・
広告や#ホットキーワードなどが並んでいる asideというタグと、block_lBlock_Primary__E7bx7 block_archive__1GKPaというclass属性を保有するdivタグがあることが分かります。

更に掘り下げて見ていくと、articles_pArticles_List__JFPxVというclass属性のdivタグ配下に存在するaタグのhref属性に記事のURLが、更にその下層にあるobjectタグに記事タイトルのテキストが格納されていることが分かります。
では、一旦今読み取った内容をもとに愚直にスクレイピングをしてみます。
3.Pythonでコードを書く
大まかな流れとしては、requestsモジュールでお目当てのURLからレスポンス情報を取得します。
レスポンス情報に含まれるテキスト情報をBeautiful Soupに渡して、HTMLの解析を行い、解析された情報からタグやclass, id等の属性情報で絞り込みをかけていきます。
(1) 記事のURLを取得してみる
class属性がarticles_pArticles_List__JFPxV配下にあるaタグのhref属性を抽出すればURLは取得できそうなので、コードを書いてみます。
import requests
from bs4 import BeautifulSoup
#url変数に文字列でお目当てのWebサイトのURLを格納
url = "https://www.lifehacker.jp/articles/"
#res変数にrequests.getでWebサイトから取得した、レスポンス情報を格納
res = requests.get(url)
#soup変数に、BeautifulSoupにレスポンスのテキストを渡し、html.parserでの解析を指示
soup = BeautifulSoup(res.text, 'html.parser')
#記事のURLを取得(class属性がarticles_pArticles_List__JFPxV配下のaタグを全て取得)
urls = soup.find(class_ = "articles_pArticles_List__JFPxV").find_all("a")
#urlsリストに格納された情報をforループで取り出しつつ、href属性を表示する
for url in urls:
print(url['href'])
print("\n")これで一旦コードを実行してみます。
途中から切ってますが、出力結果は以下のようになりました。
(forscraping) nonstopiida@nonstopiidanoMacBook-Air Documents % python lifehacker_article.py
/article/2203_amazon_kindle_unlimited/
/category/workhacks/
/article/2203_lht_laundry_convenient_tools/
/category/home/
/article/machi-ya-carbontable-review/
/category/home/
/article/machi-ya-avantairmax-start/
/category/home/
/article/2203_7_of_the_best_evernote_alternatives_and_why_you_should/
/category/workhacks/
(2) 取得したURLをWebサイトのアドレスバーに入力してみる
取得したURLでちゃんと記事が開けるか試してみます。
試しに一番上の/article/2203_amazon_kindle_unlimited/というURLで試してみると・・・

開けません。
取得したURLは相対パスと行って、https://lifehacker.jp/内で移動するためのURLなので完全体ではないためです。
頭にhttps://lifehacker.jpをつけてhttps://lifehacker.jp/article/2203_amazon_kindle_unlimited/で開いてみると・・・
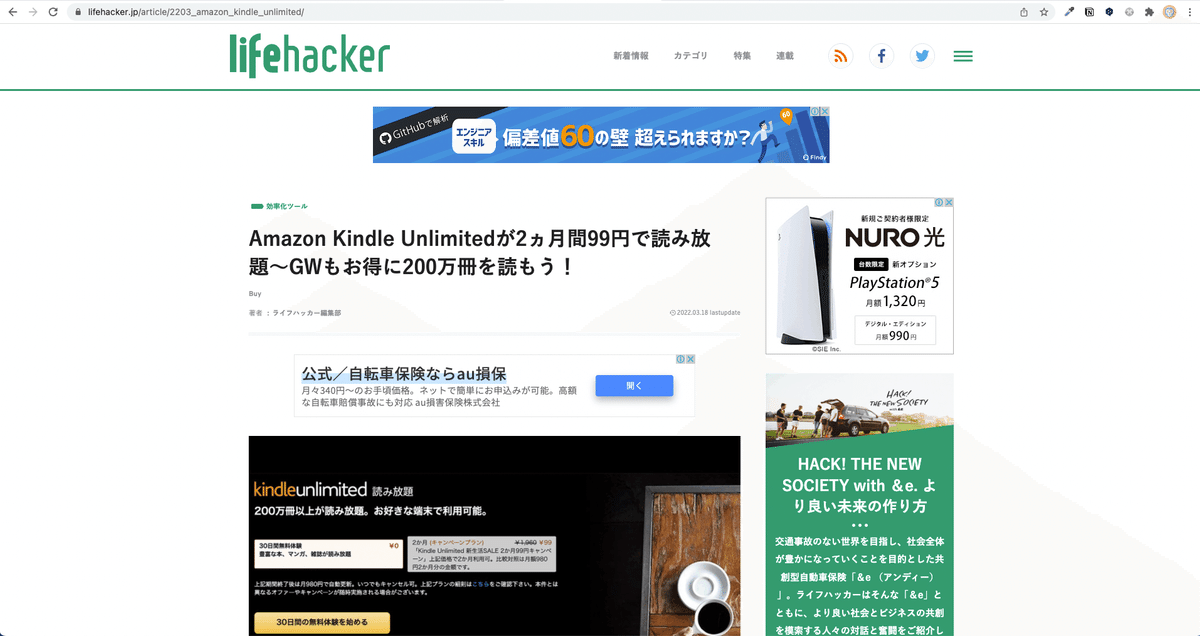
今度はきちんとアクセスできました。気になった方は相対パスと絶対パスについて調べて見てください。
スクレイピングをする際も、自分でサイトを作る際も、他のプログラムを書く際も覚えておくと良い知識です。
次にcategoryから始まる相対パスもあるので試してみます。

これはカテゴリ別の記事一覧なので、記事のURLかというとそうではないので余計な情報だということが分かります。
検証ツールに戻ってよくみると、記事のaタグはclass属性を保有していませんが、カテゴリのaタグはarticles_pArticles_ItemCat__1sXygというclass属性を保有しています。
不要なタグを削除する方法はありますが、classの属性で選り分けたい場合はどうすれば良いでしょうか。
(3) 属性値を保有しているかを判定して処理
class属性を保有しているaタグは除外したいのと、先ほどの絶対パスで最後出力をするために以下のように追記しました。
import requests
from bs4 import BeautifulSoup
url = "https://www.lifehacker.jp/articles/"
#base_url変数を定義
base_url = "https://www.lifehacker.jp"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
#記事のURLを取得(class属性がarticles_pArticles_List__JFPxV配下のaタグを全て取得)
urls = soup.find(class_ = "articles_pArticles_List__JFPxV").find_all("a")
#urlsリストに格納された情報をforループで取り出しつつ、href属性を表示する
for url in urls:
#class属性を保有していたら処理スキップ
if url.has_attr("class"):
pass
#class属性を保有していなければbase_urlにaタグのhref属性を加えたものを出力
else:
print(base_url + url.attrs['href'])
print("\n")これで実行してみると・・・
(forscraping) nonstopiida@nonstopiidanoMacBook-Air Documents % python lifehacker_article.py
https://www.lifehacker.jp/article/2203-roomie-twowayverandaslippers/
https://www.lifehacker.jp/article/2203_amazon_kindle_unlimited/
https://www.lifehacker.jp/article/2203_lht_laundry_convenient_tools/
https://www.lifehacker.jp/article/machi-ya-carbontable-review/
https://www.lifehacker.jp/article/machi-ya-avantairmax-start/
https://www.lifehacker.jp/article/2203_7_of_the_best_evernote_alternatives_and_why_you_should/カテゴリを除いた記事のURLだけが取得できました。
(4) 記事タイトルを取得してみる
次に記事タイトルはaタグ配下のpタグ配下にあるobjectタグに格納されていることを先ほど確認したので以下のように抽出してみます。
以下のように、タグ名を繋げて書いていくことで絞り込みをしていき、最後に要素のテキスト情報を抽出することが可能です。
import requests
from bs4 import BeautifulSoup
import re
url = "https://www.lifehacker.jp/articles/"
#base_url変数を定義
base_url = "https://www.lifehacker.jp"
patter1 = re.compile('articles_pArticles_ItemCat__1sXyg')
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
#記事のURLを取得(class属性がarticles_pArticles_List__JFPxV配下のaタグを全て取得)
urls = soup.find(class_ = "articles_pArticles_List__JFPxV").find_all("a")
#urlsリストに格納された情報をforループで取り出しつつ、href属性を表示する
for url in urls:
#class属性を保有していたら処理スキップ
if url.has_attr("class"):
pass
#class属性を保有していなければbase_urlにaタグのhref属性を加えたものを出力
else:
#記事タイトルを出力
print(url.p.object.text)
#記事URLを出力
print(base_url + url.attrs['href'])
print("\n")出力してみましょう。
(forscraping) nonstopiida@nonstopiidanoMacBook-Air Documents % python lifehacker_article.py
トーストに合う、おいしい目玉焼きの焼き方。あの材料を多めに入れるだけ!
https://www.lifehacker.jp/article/2203fry-your-eggs-in-too-much-butte/
山崎実業のコレで「ベランダのスリッパ濡れる問題」を解決!
https://www.lifehacker.jp/article/2203-roomie-twowayverandaslippers/
Amazon Kindle Unlimitedが2ヵ月間99円で読み放題〜GWもお得に200万冊を読もう!
https://www.lifehacker.jp/article/2203_amazon_kindle_unlimited/
洗濯のレベルをワンランク上げてくれる便利アイテム3選【今日のライフハックツール】
https://www.lifehacker.jp/article/2203_lht_laundry_convenient_tools/
屋外テレワークにも便利? 軽くて高さも自由自在な「カーボン三脚テーブル」を使ってみた
https://www.lifehacker.jp/article/machi-ya-carbontable-review/
ハイレゾをワイヤレスで! カーボンナノチューブ採用イヤホンが登場
https://www.lifehacker.jp/article/machi-ya-avantairmax-start/こんな感じで取得できたかと思います。
(5) おまけ
上の出力結果で1番目の記事と4番目の記事タイトルに不要な改行があることに気づいたかと思います。
これを文字列の特定の文字を置き換えるreplaceというメソッドで整えると、以下のようになります。
import requests
from bs4 import BeautifulSoup
url = "https://www.lifehacker.jp/articles/"
#base_url変数を定義
base_url = "https://www.lifehacker.jp"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
#記事のURLを取得(class属性がarticles_pArticles_List__JFPxV配下のaタグを全て取得)
urls = soup.find(class_ = "articles_pArticles_List__JFPxV").find_all("a")
#urlsリストに格納された情報をforループで取り出しつつ、href属性を表示する
for url in urls:
#class属性を保有していたら処理スキップ
if url.has_attr("class"):
pass
#class属性を保有していなければbase_urlにaタグのhref属性を加えたものを出力
else:
#記事タイトルを出力(改行文字を削除)
print(url.p.object.text.replace('\n', ''))
#記事URLを出力
print(base_url + url.attrs['href'])
print("\n")これで不要な改行も無くなりました。
(forscraping) nonstopiida@nonstopiidanoMacBook-Air Documents % python lifehacker_article.py
トーストに合う、おいしい目玉焼きの焼き方。あの材料を多めに入れるだけ!
https://www.lifehacker.jp/article/2203fry-your-eggs-in-too-much-butte/
山崎実業のコレで「ベランダのスリッパ濡れる問題」を解決!
https://www.lifehacker.jp/article/2203-roomie-twowayverandaslippers/
Amazon Kindle Unlimitedが2ヵ月間99円で読み放題〜GWもお得に200万冊を読もう!
https://www.lifehacker.jp/article/2203_amazon_kindle_unlimited/
洗濯のレベルをワンランク上げてくれる便利アイテム3選【今日のライフハックツール】
https://www.lifehacker.jp/article/2203_lht_laundry_convenient_tools/
ハイレゾをワイヤレスで! カーボンナノチューブ採用イヤホンが登場
https://www.lifehacker.jp/article/machi-ya-avantairmax-start/こんな感じでいろんなサイトのこんな情報を取り出すには、というシリーズを何個か書いていこうかと思います。
リクエストがあれば教えてください。