
異常検知の要因分析 (Ver.3.9.9)

時系列データ分析ツール Node-AI スクラムマスターの 中野 です!
今回のアップデートでは、異常検知の要因分析機能や関連するUX改善のリリースをしています!
Node-AIにおける異常検知機能の基本的な使い方は以下の記事で紹介しているので、初めての方はぜひご確認ください!
今回の記事は以下の構成となっています。
異常検知のシナリオ
ダミーデータの作成
Node-AIでの異常検知モデル作成
異常検知の要因分析
1. 異常検知のシナリオ
要因分析の使い所や効果のイメージをつかんでもらうため、この記事で扱う異常検知のシナリオを設定してみました(内容はフィクションです)。
(ここからシナリオ)
ある製造工場では複数の機械を稼働させており、機械ごとに温度、振動、電力消費などの複数のセンサーデータを収集しています。
これまで、機械の故障は突発的に発生することが多く、そのたびに生産ラインが停止し、生産効率が大幅に低下するという問題がありました。
また、予防保全を行おうとしても、過剰な点検やメンテナンスにコストがかかり、最適なメンテナンスサイクルがわからない状況にありました。

そこであなたはAIモデルにより異常度を可視化し、異常度が高くなればアラートを上げてメンテナンスを行うという業務フローを考えました。
しかし、ある機械には100個のセンサーが設置されており、どのセンサーが異常な振る舞いをしたのか特定する必要がありました。
異常度が高い時刻のセンサーデータを1個ずつ細かく確認していくと、70個目のセンサーに異常がありそうなことがわかり、ようやく原因を特定しメンテナンスに取り掛かることができました。
※実際の原因特定のフローはもっと複雑な場合があります。あくまでイメージとして簡略化した内容であることをご了承ください。
(シナリオは以上)
いかがでしょうか。異常の可視化をAIで実現できたところまではよいのですが、その活用段階で課題が生じていそうです。
この課題を解決するのが異常検知の要因分析機能となります。
2. ダミーデータの作成
このようなシナリオ設定で取得されそうなデータを実際に作成してみます。
最近は生成AIにお願いすればデータもすぐに作れるので便利ですよね。
シナリオではセンサーは100個としましたが、わかりやすさのため10個にしています。
異常検知用のダミーの時系列データをPythonでCSV出力するコードを作成してください。
作成するデータは次の条件を満たしてください。
- 10系列の多変量データ
- サンプリング間隔は1分
- 30日分のデータ
- 各系列それぞれに異なる周期性(10分~30分)があり、全体を通してわずかなノイズが含まれる
- 正常時データ(normal.csv)と異常時データ(anormal.csv)を出力する
- 異常時のデータには、正常時のデータには含まれない突発的なスパイクノイズが特定の1つの系列に稀に含まれる
出力されたコードがこちらです。
このコードを適当なPython環境で実行して手元にCSVファイルをダウンロードしておきます。
import numpy as np
import pandas as pd
# パラメータ設定
np.random.seed(42)
num_series = 10 # データの系列数
num_samples = 30 * 1440 # 30日分のデータ(1日1440サンプル、1分ごと)
sampling_rate = '1T' # サンプリング間隔1分
anomaly_prob = 0.01 # 異常値(スパイクノイズ)の発生確率
anomaly_series = 0 # スパイクノイズを入れる特定の系列(0番目の系列)
# 周期をランダムに設定(10分~30分の範囲)
periods = np.random.randint(10, 30, size=num_series) # 各系列ごとに異なる周期性(10分~30分の範囲)
# 正常時データの生成
time_index = pd.date_range(start="2024-01-01", periods=num_samples, freq=sampling_rate)
normal_data = pd.DataFrame(index=time_index)
for i in range(num_series):
# サイン波 + ランダムノイズを各系列に生成
normal_data[f'series_{i+1}'] = np.sin(2 * np.pi * np.arange(num_samples) / periods[i]) + np.random.normal(0, 0.1, num_samples)
# 異常時データの生成(正常時データをコピー)
anormal_data = normal_data.copy()
# 特定の1つの系列にスパイクノイズの挿入
spike_indices = np.random.choice(num_samples, int(num_samples * anomaly_prob), replace=False)
anormal_data.iloc[spike_indices, anomaly_series] += np.random.normal(5, 1, len(spike_indices)) # 突発的なスパイクノイズ
# CSVファイルに出力
normal_data.to_csv("normal.csv")
anormal_data.to_csv("anormal.csv")
print("正常時データ(normal.csv)と異常時データ(anormal.csv)を出力しました。")3.Node-AIでの異常検知モデル作成
作成したダミーデータのCSVファイルをNode-AIにアップロードします。
実際にどのようなデータになっているのか確認しておきましょう。
まずは正常時のデータ(一部を拡大しています)。

各センサーデータが「series_1」「series_2」のような名称となっており、各データがそれぞれ異なる周期で変動していることがわかります。
続いて異常時のデータ。

「series_1」の途中に突発的なスパイクノイズが生じていることがわかります。
ここまであからさまだと「目で見ればわかる」と言われそうですが、実際にはセンサーが大量にあることや異常が埋もれてしまうことを考えると目視で発見するのは難しくなってきそうです。
また文字が小さくてわかりにくいのですが、このスパイクノイズは「2024/1/1 03:07」にあるということを覚えておいてください(後で使います)。
さて、このデータに対して異常検知のモデル作成と異常度の可視化、要因分析まで行うツリーを作成してみましょう。

異常度可視化(正常時)では「異常と検知されないようにしたい」わけなので、閾値を異常度(Reconstruction Error)に触れないギリギリのラインに設定してみます(閾値設定の考え方の一例です)。

異常度可視化(正常時)と異常度可視化(異常時)をコンフィグリンクで接続することで、この閾値が異常度可視化(異常時)に引き継がれます。
さて、異常度可視化(異常時)はどうなるでしょうか。
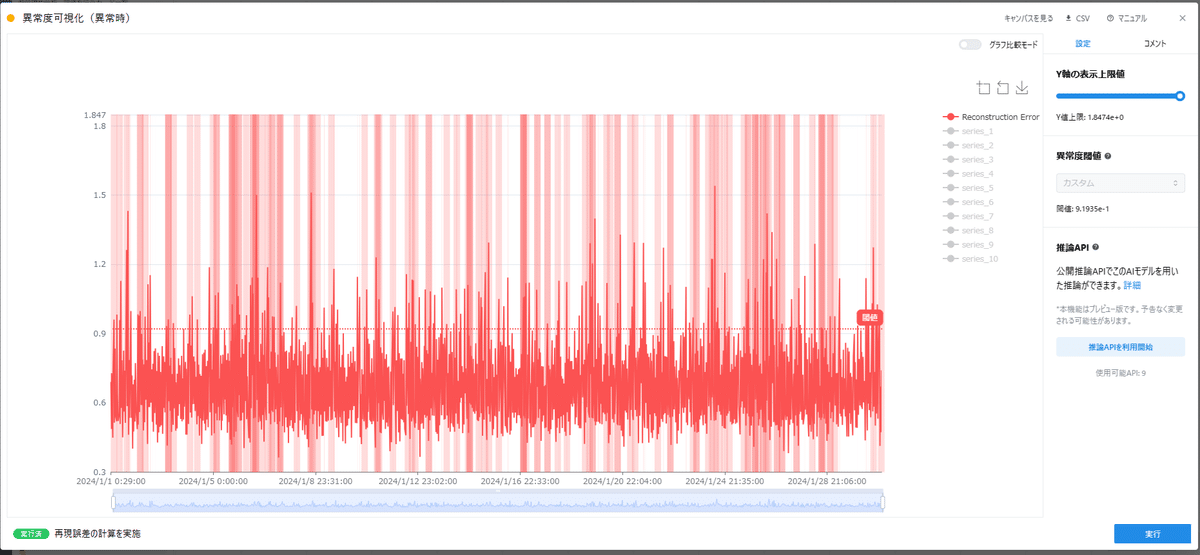
異常度が閾値を上回る箇所は赤い帯が表示されます。
これだと異常のエリアが多すぎて少しわかりにくいので、拡大してseries_1のデータと比較してみましょう。

若干時刻のズレはありますが、series_1でスパイクノイズが重畳した箇所の周辺で異常度が高くなっていることがわかります。
つまり、想定したデータの異常はこの学習モデルで検出できていそうです。
※時刻のズレはモデルの設計や時間窓切り出しの窓幅などに依存します。
※実際にモデルの精度を評価するには定量的な判断が必要です。
4. 異常検知の要因分析
お疲れ様です。ようやく本記事のメインテーマにたどり着きました!
ここまでは要因分析機能がなくても実現できていたことですが、大量にセンサーがあったり異常が埋もれている場合は「series_1に異常がある」ことは特定できていないわけです。
そのため、実際にはここからが「異常度が高い箇所で異常を示しているのはどのセンサーなのか」を特定する流れとなります。
学習したモデルと時間窓切り出しのデータ(異常時)を要因分析カードに接続し、実行してください。
※データ量や時間窓切り出しの設定によって、要因分析カードの設定と実行時に長いロードが発生します。また場合によっては実行や表示に失敗することがあります。その際はデータ量を削減したり時間窓切り出しの設定(窓幅Mやストライド幅S)を見直してください。
異常度が高くなっている2024 1/1 03:20 付近を表示してみます。
(下部のスライダーを移動すると結果を表示する時刻を変更できます。)

series_1の一箇所だけ赤色になっています!
詳細に説明すると、今回は時間窓切り出しの窓幅Mを30で設定しているのである時刻の異常度の値(Reconstruction Error)を出力するために30分のデータをモデルにインプットしていることになります。
学習済みモデルは、その30分のデータ全ての再構成誤差(の元)を計算し、足し合わせることで最終的な異常度としているので、要因を確認するには足し合わせる前の誤差を表示すればよいという理屈となっています。
3:20の要因分析結果を見ると、右端(最新の時刻)から13個手前のセルで大きな要因が出ていることから、ちょうど3:07でseries_1のセンサーに異常の要因が存在すると特定できました!
おわりに
いかがでしたか?
異常度を可視化するところまで完成しても、実際に異常の要因を特定しないと業務改善に至らなかったり時間がかかりすぎることがあります。
今回の記事を参考に、異常の要因を特定してみてください!