
【第176回】 Marketing Cloud SQL 超入門(4)- JOIN、AND、OR

これまでに Markeitng Cloud SQL の基本 と SELECT、FROM、WHERE 、そして、Dataview の使用 や 日付関数、IN(NOT IN)や IS NULL の使い方について学習しました。
そこでは Marketing Cloud で SQL を使用する目的について触れました。以下のような事例に沿って学習すると良いという話でしたね。
① データエクステンション内のデータを調査したい
② データビューを使用して、エンゲージ(関与)した顧客を知りたい
③ データビューを活用して、別の配信リストを作りたい
④ 2 つ以上のデータエクステンションを組み合わせて、別のデータエクステンションを作成したい
そして、これまでの記事では ①②③ まで学習しました。今回は、最後の ④「2 つ以上のデータエクステンションを組み合わせて、別のデータエクステンションを作成したい」について学習します。
2 つ以上のデータエクステンションを結合して、それぞれのデータを活用することで、より高度なデータエクステンションに転化することができます。まずは、結合のために使用される INNER JOIN と LEFT OUTER JOIN から学習します。
■ INNER JOIN について
まず、結合の中で最も使用されるのが INNER JOIN です。INNER の部分を省略して、JOIN とだけ記載しても INNER JOIN として実行されます。
この INNER JOIN では、データエクステンション A と データエクステンション B があった場合、それぞれのデータエクステンションに共通のキー項目 ○○ が含まれる場合のみレコードを取得することができます。下のベン図ですと、5 のベン図に該当します。
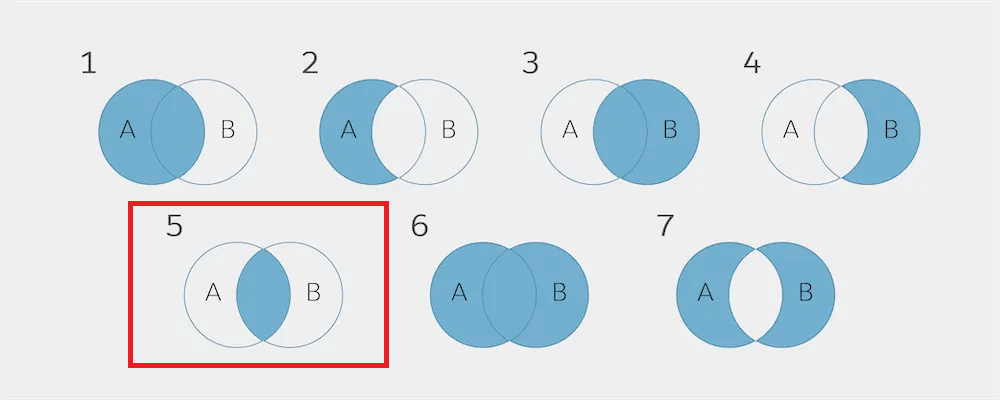
この共通のキー項目 ○○ は、同じ名前である必要はありません。例えば、Id という名前と Subscriberkey という名前であっても、それぞれが共通のキー項目を指していれば OK です。
まず、主側となるデータエクステンションを FROM で書きます。
FROM DataExtension_Aそして今回は、複数のデータエクステンションを使用する予定のため、各データエクステンションの「短縮名」を決めておくと便利です。この短縮名の設定方法は、データエクステンションの後ろに「半角スペース」を設けて、短縮名を記載するだけです。
今回、以下のような「短縮名」を設定しておきます。
DataExtension_A ➡ a
DataExtension_B ➡ b
これを反映させると、以下のような形になります。この短縮名の設定ですが、項目名に名付けた別名の時のような「AS」の記載は不要です。単純に「半角スペース」を設けて、その後ろに短縮名を記載してください。
FROM DataExtension_A a続いて、従側のデータエクステンションに対して INNER JOIN を使います。ここでも短縮名 b を入れます。
FROM DataExtension_A a
INNER JOIN DataExtension_B bさて、ここまで書けたら、ON という結合条件を使用して、データエクステンションの共通のキー項目を設定します。書き方は、それぞれを =(イコール)で結びます。そして、ここでも先ほどの「短縮名」が効いてきます。
FROM DataExtension_A a
INNER JOIN DataExtension_B b ON a.Id = b.Subscriberkey上の通りに記述することになりますが、共通のキー項目名を「a.○○」と記述すると、「a」テーブル の「Id 」項目であることを示すことができます。
もし短縮名を持たない場合は、「DataExtension_A.Id」と記載する必要があるので、少し見た目が複雑なものになってしまいますね。
上記の設定で「a」データエクステンションの項目「Id」と、「b」データエクステンションの項目「Subscriberkey」が、共通のキー項目として結合に使われ、その共通の値が含まれた場合に、レコードが取得されます。
これで 2 つのデータエクステンションは無事、結合されました。
この結合により、「a」データエクステンションの項目も使用できますし、「b」データエクステンションの項目も使用できるようになりました。
この「使用できる」とは、SELECT で取得することもできるし、WHERE で条件にすることもできるという意味になります。
SELECT や WHERE で使用される例を示すと、以下のような形です。この SELECT や WHERE においても「短縮名」をお忘れなく記載してください。
SELECT a.Id
, a.Email
, b.Name
, b.Birthday
FROM DataExtension_A a
INNER JOIN DataExtension_B b ON a.Id = b.Subscriberkey
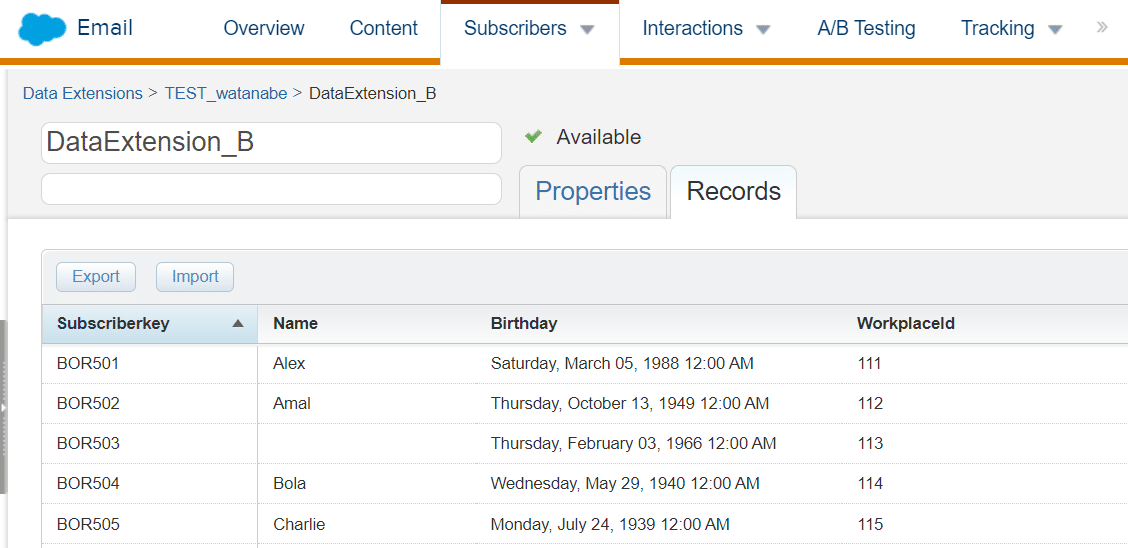
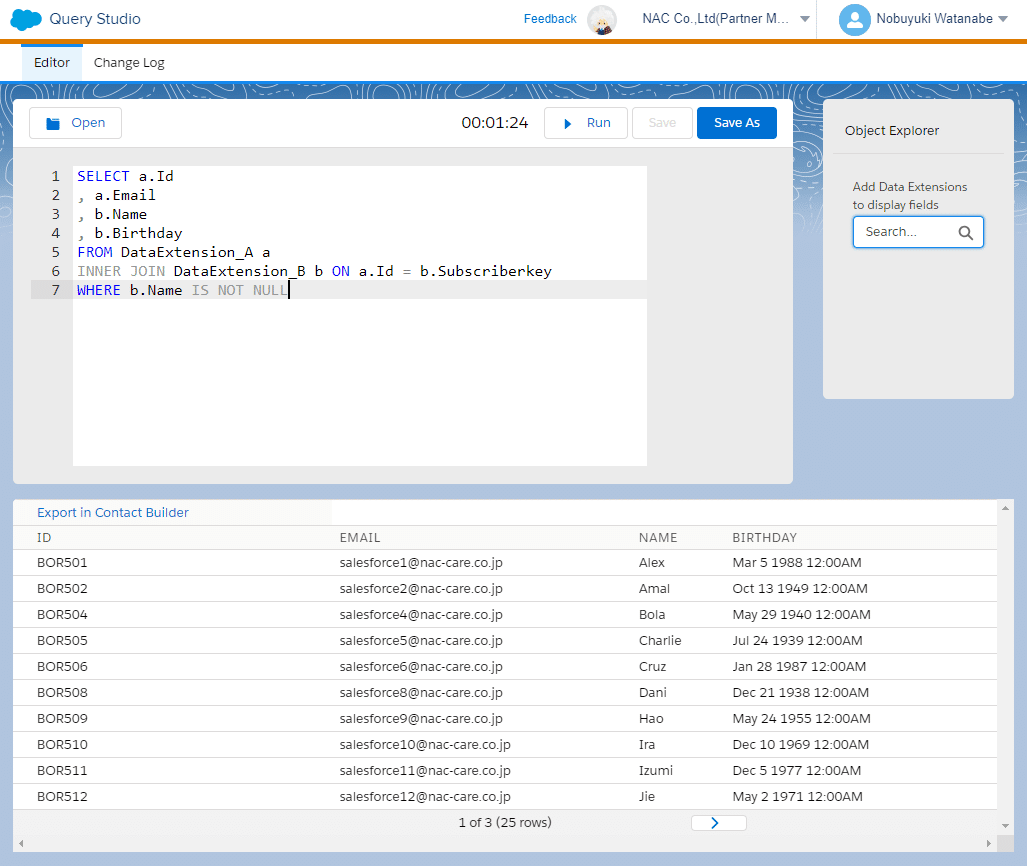
WHERE b.Name IS NOT NULLさて、今回サンプルで使うデータですが、DataExtension_A 側には「Id」の他、「メールアドレス」だけが格納されていて、DataExtension_B 側には「SubscriberKey」の他、「名前」と「誕生日」などが格納されています。
DataExtension_A の「Id」と DataExtension_B の「SubscriberKey」は名前こそ違いますが、共に、購読者キーが格納されていて共通のキー項目です。

上記のクエリで、この 2 つのデータエクステンションが組み合わされ、以下のような新しいデータエクステンションを作成することができます。

では、3 つ目のデータエクステンションを結合する場合は、どのように記述すれば良いかと言うと、以下のように記述します。
SELECT a.Id
, a.Email
, b.Name
, b.Birthday
, c.Name COLLATE Japanese_CS_AS_KS_WS AS [WorkplaceName]
FROM DataExtension_A a
INNER JOIN DataExtension_B b ON a.Id = b.Subscriberkey
INNER JOIN DataExtension_C c ON b.WorkplaceId = c.Id
WHERE b.Name IS NOT NULL
DataExtension_C は、以下のような「勤務地マスター」となっています。
今回、WorkplaceId = 115 のデータを持つ購読者が DataExtension_B の中にいますが、勤務地マスター側には Id = 115 のデータが無いため、INNER JOIN の特性から WorkplaceId = 115 のレコードは取得できません。

また、注意点として、「a」と「b」の INNER JOIN が「b」と「c」よりも先に記述されていないと、エラーが発生します。なぜなら「b」の別名の定義が未だ行われていないからですね。SQL でも記述の順番が大事になってきます。
■ 以下のような順番で記述すると、エラーとなります。
SELECT a.Id
, a.Email
, b.Name
, b.Birthday
, c.Name COLLATE Japanese_CS_AS_KS_WS AS [WorkplaceName]
FROM DataExtension_A a
INNER JOIN DataExtension_C c ON b.WorkplaceId = c.Id ← b の別名が未だ定義されていない
INNER JOIN DataExtension_B b ON a.Id = b.Subscriberkey
WHERE b.Name IS NOT NULL
ちなみに、前回の記事でデータビューで取得されたデータを活用した配信リストを作成する方法を説明しました。以下のクエリですね。
■ 前回の記事で記載した書き方
SELECT
Id,
Email,
Name COLLATE Japanese_CS_AS_KS_WS AS [Name]
FROM
MasterSubscribers
WHERE
Id IN (
SELECT
SubscriberKey
FROM
_Click
WHERE
TriggeredSendCustomerkey = '88597'
)
こちらは、以下のように INNER JOIN を用いた書き方に変更が可能です。
■ INNER JOIN を使用した書き方
SELECT
a.Id,
a.Email,
a.Name COLLATE Japanese_CS_AS_KS_WS AS [Name]
FROM
MasterSubscribers a
INNER JOIN
_Click b
ON
a.Id = b.Subscriberkey
WHERE
b.TriggeredSendCustomerkey = '88597'
これら 2 つのクエリをしっかり読み解いて、どちらが自分に合っているかを試してみてください。
メリット・デメリットを考える時に 1 つ参考になるのは、JOIN が含まれる場合は、SELECT *(アスタリスク)が使用できないという特性があります。つまり「INNER JOIN を使用した書き方」では SELECT *(アスタリスク)が使用できないということになります。
勿論、Automation Studio の クエリアクティビティには、データエクステンションの項目名を一括で呼び出せる機能があるので、SELECT *(アスタリスク)は使用しなくて大丈夫、という意見もあるのですが、以前の記事でも説明した通り、項目名に from の「予約語」が混ざっている場合など、項目名を [ ] で囲む必要があったりもしますので、少し手間な場合があります。
単発で配信リストを作成する場合などは、圧倒的に SELECT *(アスタリスク)を使用した方が楽な場合がありますので、サブクエリを使用するパターンもマスターしておくことをお勧めします。
※ ちなみに Query Studio においては、*(アスタリスク)の使用は、必ずエラーとなってしまいます。
■ LEFT OUTER JOIN について
さて、続いて、LEFT OUTER JOIN について説明します。下のベン図ですと 1 です。( 2 も LEFT OUTER JOIN ですが、今回は説明を割愛します。)
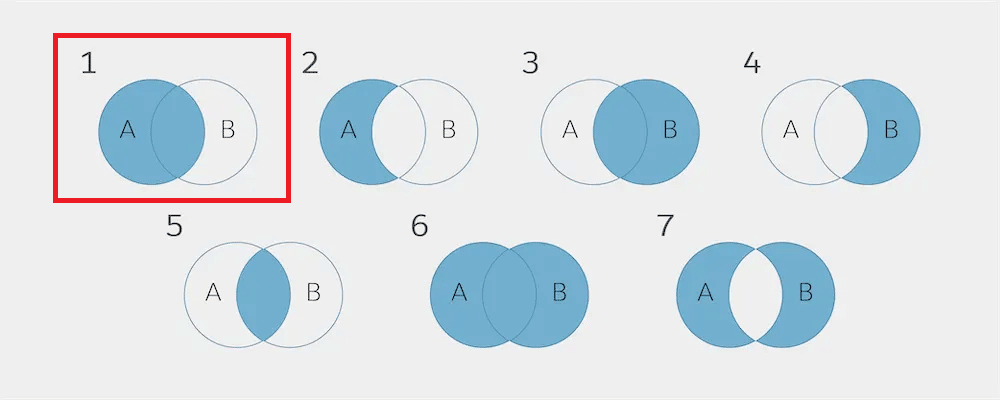
このベン図のイメージを見て分かる通り、LEFT(左側)の A のデータテーブルのすべてのレコードは取得することができます。一方で、RIGHT(右側)の B のデータテーブルでは、共通のキー項目 ○○ が存在する場合だけ、レコードが取得でき、共通のキー項目 ○○ が存在していない場合は、すべて NULL で取得されます。
ここでサンプルとして、先ほどの INNER JOIN のクエリを再掲します。
SELECT a.Id
, a.Email
, b.Name
, b.Birthday
, c.Name COLLATE Japanese_CS_AS_KS_WS AS [WorkplaceName]
FROM DataExtension_A a
INNER JOIN DataExtension_B b ON a.Id = b.Subscriberkey
INNER JOIN DataExtension_C c ON b.WorkplaceId = c.Id
WHERE b.Name IS NOT NULLDataExtension_C の結合に注目すると、INNER JOIN では DataExtension_B に格納されている WorkplaceId に対応する Id のレコードが DataExtension_C 側にも格納されていないと、レコードは取得できませんね。上で説明した通りとなります。
SELECT a.Id
, a.Email
, b.Name
, b.Birthday
, c.Name COLLATE Japanese_CS_AS_KS_WS AS [WorkplaceName]
FROM DataExtension_A a
INNER JOIN DataExtension_B b ON a.Id = b.Subscriberkey
LEFT OUTER JOIN DataExtension_C c ON b.WorkplaceId = c.Id
WHERE b.Name IS NOT NULLしかし、ここで LEFT OUTER JOIN を使用すると、仮に WorkplaceId に対応する Id が格納されてなくても、DataExtension_C に格納されている「c.Name」は、NULL としてレコードを取得してきます。

ユースケースで説明しますと、WorkplaceName(勤務地)をパーソナライズ文字列(%%WorkplaceName%%)で使用し、メール内で掲出している場合、その項目は必須の項目であるべきなので、INNER JOIN になります。
一方で、WorkplaceName(勤務地)をメールの中身では使用せず、単に、エントリーソース内にデータとして持っているだけということであれば、とりあえず LEFT OUTER JOIN で良いかもしれません。
以上、理解できましたでしょうか。
少し難しかったかもしれませんね。ただし、運用の 9 割程度においては INNER JOIN を使用することになりますので、まずは INNER JOIN から学習してみて下さい。
さあ、これで INNER JOIN、LEFT OUTER JOIN を扱えるようになりました。次に WHERE 句で使える「AND」と「OR」について簡単に説明します。
■ AND、OR について
この「AND」と「OR」に関しては、Marketing Cloud のフィルター機能を使ったりしていれば、何となく理解できているのではないかと思います。
予想通りかと思いますが、
・AND が「かつ」という条件設定になり、
・OR が「または」という条件設定になります。
ここで重要なのは、しっかりと「()」(カッコ)を使用して優先度を決めることです。「()」(カッコ)の中身の方が優先度が高く評価されます。
もし、A AND ( B OR C ) であれば、( B OR C )側が先に評価され、( B または C )かつ A であるレコードが取得されます。
例えば、下のサンプルクエリでは、勤務地が「東京都」か「神奈川県」であり、「名前」がNULL では無いレコードが取得されます。
SELECT a.Id
, a.Email
, b.Name
, b.Birthday
, c.Name COLLATE Japanese_CS_AS_KS_WS AS [WorkplaceName]
FROM DataExtension_A a
INNER JOIN DataExtension_B b ON a.Id = b.Subscriberkey
LEFT OUTER JOIN DataExtension_C c ON b.WorkplaceId = c.Id
WHERE b.Name IS NOT NULL
AND (c.Name = '東京都' or c.Name = '神奈川県')
では、「()」(カッコ)が使用されなかった場合はどうなるでしょうか?
その場合は、AND が優先され、OR は劣位となります。
つまり、A AND B OR C となっていた場合は、自動的に( A かつ B )または C となります。
上記のクエリ内で「()」(カッコ)が使用されていなかったとしたら、
・「名前の項目に値がある東京都が勤務地」のレコード
または
・「名前に値があるかどうかは問わず、神奈川県が勤務地」のレコード
が取得される感じです。
SELECT a.Id
, a.Email
, b.Name
, b.Birthday
, c.Name COLLATE Japanese_CS_AS_KS_WS AS [WorkplaceName]
FROM DataExtension_A a
INNER JOIN DataExtension_B b ON a.Id = b.Subscriberkey
LEFT OUTER JOIN DataExtension_C c ON b.WorkplaceId = c.Id
WHERE b.Name IS NOT NULL
AND c.Name = '東京都' or c.Name = '神奈川県'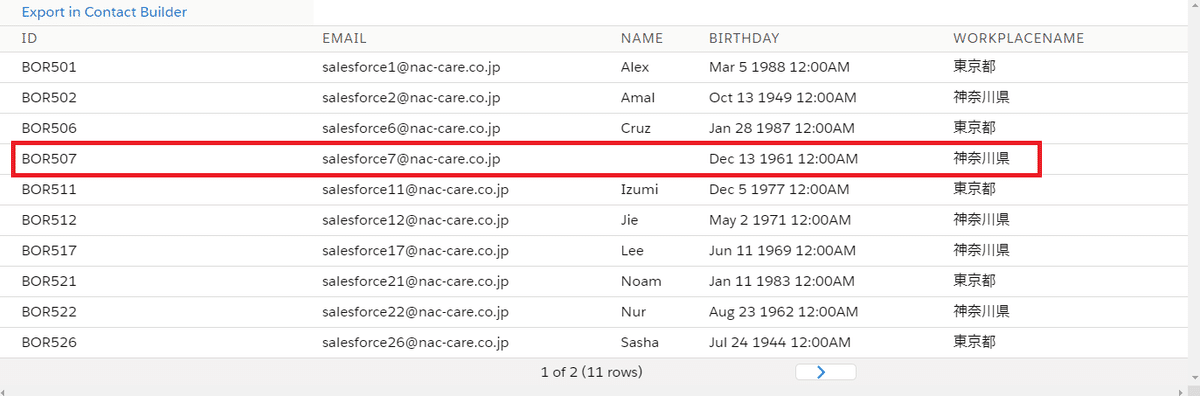
いかがでしたでしょうか。
これまでの全 4 回の記事で、Marketing Cloud SQL の超入門編は学習できたかと思います。次回以降は、中級編を学んでいきましょう。
今回は以上です。