
財務・非財務情報を活用した株主価値予測 コンペ振り返り

こんにちは。Nishika CTOの松田です。
先日終了した「財務・非財務情報を活用した株主価値予測」コンペについて、コンペ開催に至る背景や上位ソリューションのご紹介をしながら、振り返りたいと思います。
本コンペは、述べ260名の方にご参加いただきました。改めて感謝申し上げます。
本コンペの概要
本コンペは、TIS株式会社にて作成・公開いただいているCoARiJデータセットを活用し、会計年度2014-2017年の各企業の財務・非財務情報から、会計年度2018年の期末時価総額を予測するモデルを構築する、というものでした。
ただし目的変数は、各企業の会計年度2018年の期末時価総額そのものではなく、各企業の会計年度2017年の期末時価総額を1として指数化された値です。
目的変数の変換を行っているのは、期末時価総額の大きな企業をよく予測できれば良いというのではなく、期末時価総額の多寡によらずよく予測できるモデルを高く評価したい、という意図があったためです。
予測精度の評価指標は、RMSEに設定しました。
本コンペの目的
早速ですが、実は本コンペには、精度の高いモデルを作りたいということの他に裏の目的がありました。
それは、一般に企業価値評価における活用が難しいとされてきた非財務情報について、その活用方法を見出すことです。
少し話が横道にそれますが、企業価値とは、簡単に言えば会社の価格のことです。
分かりやすい用途として、M&Aの際に、売り手企業がいくらで会社を売ることができるか、買い手企業がいくらの値で買うのが妥当か、を決める上で参考とされるもので、非常に重要な値です。
ただしその算定は難しく、特に難しいのが「その企業が中長期に渡ってどの程度成長してくれるのか」の予測です。
将来の予測となるので明確な正解はなく、個別の考え方が現れます。
投資家は、この企業が「こういう取り組みをしているということは将来業績が上がる目がありそうだ」「今になってこういうメッセージを出すということは将来業績が落ち込みそうだ」などと将来の成長に対する見立てをたてて投資を行うので、結果株価や時価総額が上下するわけです。
近年、企業の長期的な成長のためには企業が果たすべき社会的責任(環境問題や社会課題、ガバナンス等)に対する取組も重要だと考えられています。このような取組については、多くの企業が統合報告書やCSR報告書などを通して取組内容を公表しており、その内容が業績や企業の価値に与える影響も増しています。
従来から、多くのステークホルダーに対して自社の業績や活動内容を報告するために公開されてきた“有価証券報告書”と併せて、
企業の長期的な成長の評価に対して、これら非財務情報の果たす役割を何らか見出したい、という背景がありました。
近年の自然言語処理の発展(特にELMo/BERT)により、新しい活用の仕方が見出せる素地が整ってきているのではないかとの考えもあり、コンペの開催に至りました。
スコアの推移
コンペの結果、1st solutionのRMSEはPublic LBで0.287232、Private LBで0.269588という結果でした。
全て1と予測(前年の時価総額と同じ)すると0.3程度ですので、当然ながらそれよりも良いスコアとなっています。
コンペ期間中のスコアの推移は以下の通りでした。

参考までに、前回の「「Brandearオークション!」 レコメンドエンジン開発」コンペのスコア推移は以下の通りでした。

最後までギリギリとスコアが上昇していた前回コンペに比べると、今回のコンペはスコアを上げること自体が難しかった、と言えます。
上位ソリューションの概要
ここからは上位ソリューションの概要について紹介していきます。
まずは前処理についてです。
与えられたデータの中には一部ターゲットの値が異常に大きくなっているものがありました。
これは、データ元である決算短信の記載の慣習によるもので、会計期末の直後に株式分割を行った企業についてのみ、期末発行済株式総数が期末時点でなく株式分割後の値で決算短信上に記載されており、時価総額の値が実際の値と異なるものになっていることに因る異常値でした。
詳細はディスカッションにも記載しています。
1st solutionのminguinさんの解法では、何の前処理も行わないと予測結果がこの異常値に引っ張られていたために、market_cap_indexedが90%tile値以上となるレコードを90%tile値で置換する、という処理を行われていました。
次に特徴量エンジニアリングについてです。
教師データセットの作成方法にも複数の考え方がありますが、上位ソリューションで主に採用されていたのは以下のようなデータセットの作成方法でした。
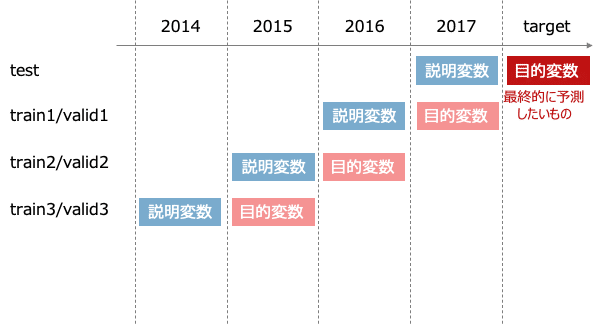
これに対して様々な特徴量を生成していくことになりますが、2nd solutionのu++さんの解法では、6047もの特徴量を生成されています。テーブルデータからの特徴量生成は、考えられるものはほぼやり尽くされているのでは、と思えるほどです。

上位入賞者からは、実際に有効だった特徴量として以下が挙げられていました。
・時価総額の対前年比率
・営業利益の対前年比率
・同一企業の年度を跨いで最大の時価総額に対する当年の時価総額の比率
・同一企業の年度を跨いで平均の時価総額に対する当年の時価総額の比率
最後に後処理についてです。
モデル構築を終え、Cross Validationの結果を見ながらよりCVの結果が良いものを提出していくと、Leaderboardのスコアが必ずしもよくならない(むしろ悪くなることも多い)、つまりCVとLBの結果が相関しない、ということがわかります。
これは、2017年以前のデータでターゲットを精度よく予測できるモデルと、2018年のターゲットを精度よく予測できるモデルとの間に乖離があることを意味します。
そこで、LBの上位に行くためには、後処理が重要となってきます。
1st solutionでは、
・前処理を行ってもなお、予測値に上振れ傾向が見られたので、public scoreを見ながら全体を調整
・前年のmarket_cap_indexedが異様に高い企業は、当年下がる傾向がEDAにより確認されたので、調整(異様に高いと判断するための閾値と、どれくらい下がる傾向があるのか)
という調整がなされていました。
2nd solutionでは、
手元のCVスコアが信用できず、かつ評価指標が平均二乗誤差の場合に採用できる、全て0で提出した場合のpublic LBのスコアを使って優れたアンサンブルの重みを算出するnetflix blendingという手法が使われていました。
詳しくはこちらの解説記事をご覧ください。
非財務情報の活用
弊社で受領させていただいた上位3位までの入賞ソリューションでは、非財務情報が活用されたものはありませんでした。
実際に入賞者にヒアリングさせていただいたところ、非財務情報の活用はトライしたが、明らかに効果があると言えるほどのスコア上昇は認められなかったため採用しなかった、という声が聞かれました。
試された特徴量は、
・文章量(増えているか減っているか)
・有価証券報告書のテキスト情報をtf-idfでベクトル化
・有価証券報告書のテキスト情報に対するLDAで生成した特徴量
・企業名をsentencepieceにより分割してtf-idfでベクトル化
などでした。
直感的に有用だと感じたのは、企業名をsentencepieceにより分割してtf-idfでベクトル化する方法でした。
sentencepieceは生文からサブワードへの分割を学習する手法です。これにより、何の処理もしなければ「三菱自動車」「三菱重工業」などは全く別のレコードとして認識されていたものが、三菱という単語を含めば1、そうでなければ0といった新たなカラムが生成されることで、「三菱xxx」「三井xxx」などとグループ関係を考慮した特徴量を生成することができます。
以下、sentencepieceを使ったコードの例を示しておきます。
import os
from collections import Counter
import pandas as pd
import sentencepiece as spm
from scipy.sparse import lil_matrix, vstack
df = pd.read_csv('../input/data/2017/documents.csv')
df['filer_name'] = df['filer_name'].apply(lambda x: x.replace(' ', '').replace('株式会社', ''))
with open(f'../processed/filer_names_sample.txt', 'w') as f:
for filer in df['filer_name'].values:
f.write(filer + '\n')
def train_sentencepiece(input_file, output_file, vocab_size=8000):
spm.SentencePieceTrainer.Train(
'--input={input} --model_prefix={model} --vocab_size={vocab}'.format(
input=input_file, model=output_file+'_{}'.format(vocab_size), vocab=vocab_size))
class Tokenizer(spm.SentencePieceProcessor):
def __init__(self, model_path):
super().__init__()
self.Load(model_path)
def to_ids(self, text):
return self.EncodeAsIds(text)
def to_pieces(self, text):
return self.EncodeAsPieces(text)
def to_tf(self, text):
ids = self.to_ids(text)
n_vocab = self.GetPieceSize()
tf_dict = Counter(ids)
lil = lil_matrix((1, n_vocab), dtype=float)
for k, v in tf_dict.items():
lil[0, k] = v
return lil
vocab_size = 1000
model_path = f'../processed/sentence_{vocab_size}.model'
if not os.path.exists(model_path):
train_sentencepiece(
input_file = '../processed/filer_names.txt',
output_file = '../processed/sentence',
vocab_size = vocab_size
)
t = Tokenizer(model_path)
df['tf'] = df['filer_name'].apply(lambda x: t.to_tf(x))
tf = vstack(df.tf.tolist(), format='lil')さて、これらの効果のほどですが、手元のモデルで以下2つの手法を検証したところ、
・有価証券報告書のtf-idf
・企業名にsentecepieceをかけた上でのtf-idf
ともにprivate LBは約0.01ずつのスコアの上昇が見られた一方で、public LBは逆に下降した、という結果でした。
0.01の差は2位が1位にランクアップする程のものですので、順位に影響は与える処理であったと言えるものの、本質的に予測に寄与する特徴が得られたか?という問いにはYesと答えづらい、とも言えます。
おわりに
今回の問題設定には、いろいろとご指摘をいただきました。
一番の課題は、CVの結果とLBのスコアが相関しないこと、特徴量とターゲットに1年間のラグがあり予測自体が難しいことから、そもそも機械学習のタスクにはあまり向かない問題だったのではないか、というご指摘でした。
ご指摘の通りで、コンペ開催前にいくつかモデル構築を行ってはいたものの、期間中にデータセットの差し替えがあり、差し替え後はかなり難しいタスクとなってしまった予測があったのは確かです。
ただ、少なくとも財務情報については、時価総額の予測というタスクにおける活用方法は探索し尽くされたのではないかと考えています。
非財務情報を中心にさらなる特徴量探索を進める上で、今回構築いただいたモデルは(相当ハイレベルではありますが)ベースラインとして価値があるものになっている、と考えています。
今回の経験も糧に、より意義のあるコンペ開催に努めていきたいと思います。
改めまして、本コンペにご参加いただいた皆様、誠にありがとうございました!