
判例の個人情報の自動マスキング コンペ振り返り

こんにちは。Nishika CTOの松田です。
先日終了した「判例の個人情報の自動マスキング」コンペについて、振り返りたいと思います。
今回の振り返りでは少し趣向を変えて、コンペ開催に至る背景や上位ソリューションのご紹介とともに、他にあまり例がないと思われる
個人情報に関する固有表現抽出のデータセット作り
の過程についてもご紹介します。
尚、本コンペは、述べ228名の方にご参加いただきました。
改めて感謝申し上げます。
本記事の要点
- 裁判の判例文中にある個人情報(人名、組織名、地名など)を、
自動で抽出する機械学習モデルを構築するコンペティション
- 約200の判例文に30000弱の個人情報へのラベルが付られたデータセットを作成し、教師データとした
- 1位のソリューションは91.4%の精度で抽出可能。
特に人名は94.5%、組織名・施設名は81.4%の高精度で抽出可能なモデルが構築できた ※評価指標はF1値のマイクロ平均
コンペ開催の背景
本コンペの着想は、フランスの法律系出版社が、判例の匿名化を機械学習で行う技術を開発している、という情報を入手したことがきっかけでした。
- フランスの法律系出版社が、判例の匿名化を機械学習で行う技術を開発している
- 出版物では判例から個人名を除くことが義務となっているが、このプロセスを自動化したいというのが最初のモチベーション
- 抽出対象の表現はnatural person name, lawyer name, judge_clerk name, address, organization, bar, court, date
- lawyer nameやjudge_clerk nameを抽出しているのは、他の名前と違って匿名化する必要がないことを判定するため
- 副産物的な成果もあり、例えばorganizationを抽出できることで、組織名のリストの出力や検索などもできるようになる
- フランスでは、3年前にすべての訴訟事件をオープンデータ化する法律が投票で可決されており、市民、訴訟当事者、弁護士など誰もが誰にもお金を払わずに自由にアクセスできるようになっている
- 以前に控訴審判決の匿名化をやっていて、今回は商業裁判所の判決の匿名化に取り組んでいる
- 商業裁判所の方が難易度が高い。高い文体の多様性、紙のスキャンノイズ、OCRエラーのため
翻って日本の状況はというと、フランスのように全件オープンという形にはなっていないようです。
それでも一部判例について裁判所職員らが匿名化作業を行っているのは事実で、判例文の匿名化作業の効率化の現場ニーズは強い、とのことでした(現役裁判官のヒアリングより)。
また、実際に判例文の匿名化作業を担うことの多い、法律系データベースを作られている株式会社TKC様と会話させていただいたところ、
現状でもある程度の精度は達成しているが、機械学習を使ってどの程度の水準まで達するかは検証の余地があるというお話もいただきました。
一方の我々は法律に特化した事業を営んでいるわけではありませんが、個人情報のマスキングは判例文に限らず様々な分野でニーズがあり、社会的意義の高いテーマだと考えておりました。
そのような経緯を経て、TKC様にご後援をいただき、コンペを開催する運びとなりました。
タスク設定
本コンペのタスクは、
判例文の中で、個人情報に相当する文言を、人名・組織名・地名などの種類別に抽出すること
と設定しました。
というのも、実際の判例文のマスキングでは、人名はA, B, C... 地名はα, β, γ…などと、表現の種類ごとにマスキングのルールが一定決まっています。
つまり、判例文の自動マスキングを実現するには、
マスクすべき箇所の抽出
マスクすべき箇所がどの種類の表現なのか特定
の2点が必要でした。
公開されているマスク済み判例文の例をいくつか示します。
最もマスク箇所が多いのは、人名です。

組織名や施設名、人物の役職名も多くマスクされています。

住所などの地名もマスクされることがあります。

日付も、事件・事故の発生日や誕生日といった個人の特定に繋がり得るものはマスクされています。

その他、サービス名や商品名がマスクされることもあります。

今回は、実際の判例文のマスキングルールにある程度則り、以下5種類について抽出するタスクと設定しました。
人名: PERSON
組織名・施設名・役職名: ORGFACPOS
地名: LOCATION
時間: TIMEX
その他: MISC
実現したいゴールのイメージは以下の通りです。

データ作成
先にご紹介した判例文はマスク済みのものであり、機械学習の教師データとしてはマスクされる前のデータが必要です。
しかし、当然ながらマスクされる前の個人情報付きデータを入手することはできず、仮に入手できたとしてもコンペティションのデータとして配布することは不可能です。
さらに言えば、固有表現抽出(自然言語処理で、事前に定義されたカテゴリの表現を抽出するタスクのこと)で、一般に利用できる日本語データセット自体が希少である中で、個人情報抽出にあたるものに限定すると、当方が調べた限り一般に公開されているものはないという状況でした。
従って、データセットをほぼゼロの状態から作成する必要がありました。
今回とったアプローチは、先にご紹介したマスク済み判例文のデータについてマスクされた箇所をダミーデータで置換しマスク前の状態に「復元」するという方法でした。
地味なプロセスではありますが、データセット作りのご参考になればと思い、以下具体的な手順を説明します。
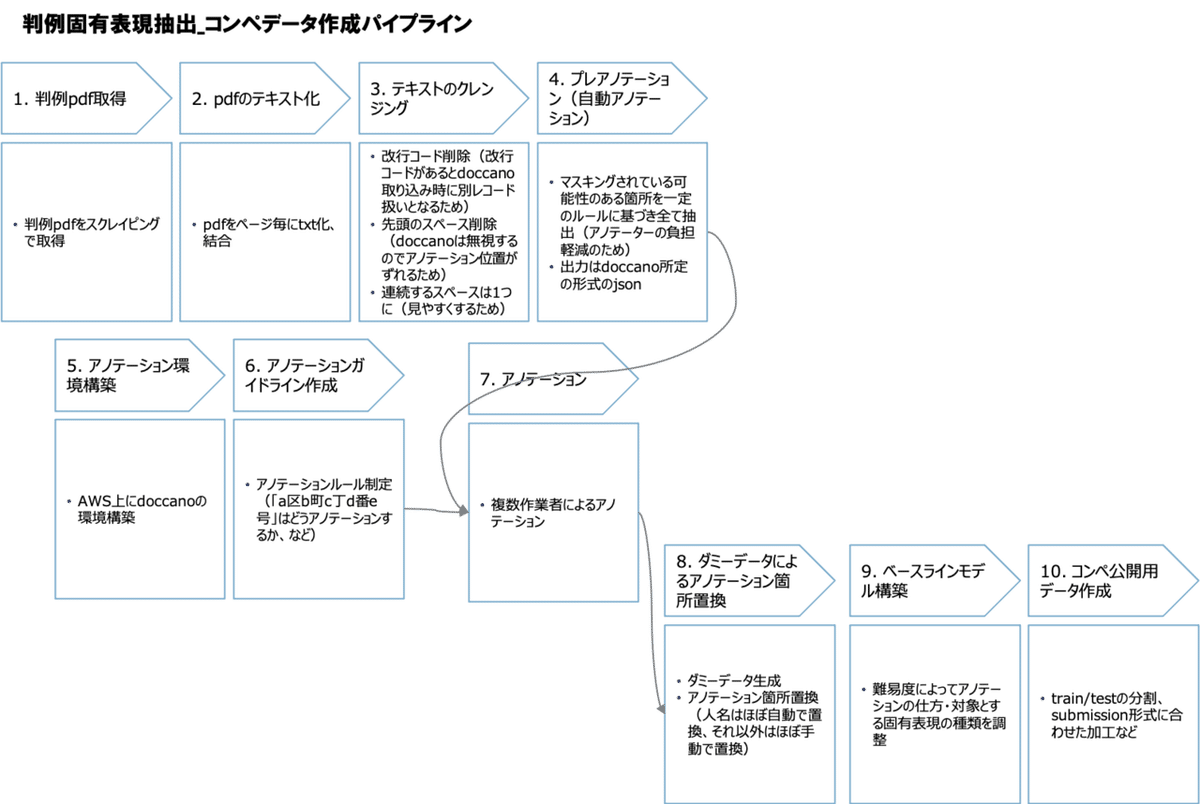
1. 判例pdf取得
まず、判例pdfを最高裁判所HPの判例検索から取得します。
2. pdfのテキスト化
pdfをページごとにテキスト化し、結合します。
pdfのページごとの分割にはPyPDF2、pdfのテキスト化にはpdfminerを利用しました(PyPDF2は日本語の抽出に対応していないため)。
3. テキストのクレンジング
テキストファイルをクレンジングします。
後に出てくる、テキストアノテーション用のツールdoccanoの仕様に合わせたクレンジングもここで行います。
- 文中に入り込むページ番号・行番号を削除
- 改行コードを削除(改行コードがあると、doccano取り込み時に別レコード扱いとなってしまう)
- 文書の先頭にある空白を削除(doccanoは文書の先頭にある空白を無視するので、自動アノテーションをしたときの位置がズレる)
- 連続する空白を1つにまとめる(見栄えを改善)
正規表現を使い一括処理できるものも多いですが、pdfをテキスト化した際に文中に入り込んでしまったページ番号・行番号の削除はある程度手動で行う必要もありました。
4. プレアノテーション(自動アノテーション)
実際にアノテーションをやってみると分かりますが、アノテーションにおいて、見落としがないように気をつけながら、正しいラベルを振っていく作業はなかなか忍耐が要ります。
そこで、アノテーションに入る前に、少しでもアノテーターの負担を軽減しておくことを考えます。
判例データのマスキングはある程度決まった記号によって行われていることを利用し、それらの記号が出現したら「マスキングされている=ラベル付の必要がある可能性がある」と判定し、適当なラベルでアノテーションしておきます。
具体的には、以下の記号を検索し、アノテーションします。
- 'ABC...Zabc....z'
- '▲●'
- 'αβγδεζηθικλμνξοπρστυφχψω'
- 'ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩ'
- 'ⒶⒷⒸⒹⒺⒻⒼⒽⒾⒿⓀⓁⓂⓃⓄⓅⓆⓇⓈⓉⓊⓋⓌⓍⓎⓏ'

このようにすることで、いわゆるRecallが100%となり、アノテーターは自分のアノテーションに見落としがないか気をつける必要がなくなりました。
5. アノテーション環境構築
アノテーションはそれ専業で請け負う業者がいるような工程ですが、今回はdoccanoというテキストアノテーション用のOSSツールを活用することで、ほぼコストをかけずに作業環境を構築できました。
https://github.com/doccano/doccano
正直、本コンペはdoccanoの存在なくしては成らなかった、と言えるほど、助かりました。
しかも、AWSなどのクラウド上に1-clickで環境構築できる手順まで掲載いただいています(CloudFormationのテンプレートがある)。
1人で作業をするのであればローカルに環境構築できれば十分ですが、多くの場合、複数人で作業しアノテーションの質量を担保することが推奨されると思います。
Web上にアノテーション環境を高速で構築するのは必須とも言え、その手順のガイドがあるのは非常に助かりました。
6. アノテーションガイドライン作成
アノテーション作業で大変なのは、ガイドラインを決めるところです。
ガイドラインというのは、例えば「a区b町c丁d番e号」を別々にアノテーションすべきか、まとめてアノテーションすべきかといった点について作業者共通の判断基準をもっておくことです。
これが言うは易し行うは難しで、初めに完璧なルールを決めアノテーションを悩みなく遂行するのは100%不可能と言ってよく、都度ルールを追加・修正しながらアノテーションを進めていく必要があります。
具体的な雰囲気については、実際のアノテーション作業時のやりとりをご覧いただいた方が良いかもしれません。
アノテーション初期のやりとりを一部掲載します。
この頃は混沌の一言です。。

もちろん、ガイドライン制定にあたっての指針は必要です。
判例中のマスキングされている箇所がどの固有表現の種類にあたるかは、関根の拡張固有表現階層を参考に判断することとしていました。
7. アノテーション
ここまで来てようやくアノテーションに着手します。
記事の構成上、手順を順序立てて進めていったように見せていますが、実際にはアノテーターからの意見を受けてガイドラインを見直したり、プレアノテーションをやり直したり、クレンジングをやり直したりしており、行きつ戻りつのプロセスでした。
8. ダミーデータによるアノテーション箇所置換
アノテーションが完了したら、マスキングされている箇所を実際にありそうな表現に置き換え、教師データ化していきます。
AおよびBの代表取締役であるCは・・・
という文章があったら
田中太郎およびNishika株式会社の代表取締役である佐藤二郎は・・・
などと置き換えていきます。
人名についてはダミーデータを生成してくれるツールがいくつか公開されておりましたので(テストデータ・ジェネレータなど)、そちらを活用することである程度自動で置換することができました。
しかし、組織名や地名については自動で置換することが難しく、ほぼ手動で置き換えていきました。
9. ベースラインモデル構築
ベースラインモデルを構築し、難易度を見積もります。
難易度があまりに高い固有表現の種類があった場合、抽出対象クラスの調整を試みる予定もありましたが、
今回はマイクロ平均のF1値を評価指標としたため、データ数が少ないクラスにスコアがあまり引っ張られないこと、
また実用を考えると難易度が高いとはいえ抽出対象を大きく変更するわけにはいかないことから、
この段階での変更はほぼ行いませんでした。
10. コンペ公開用データ作成
最後に、他コンペでも同様ですが、コンペ公開用データを作成します。
train/testの分割、submission形式に合わせた加工などを行います。
最終的に作成したデータの概要は以下の通りです。
判例数
194
裁判種別ごとの判例数
下級裁裁判例 108
行政事件裁判例 46
知的財産裁判例 27
最高裁判例 10
高裁判例 2
労働事件裁判例 1
判例中のラベル数
PERSON 22759
ORGFACPOS 3928
LOCATION 611
TIMEX 214
MISC 174
固有表現別基本統計量

上位ソリューションの概要
コンペティションの結果、最終ランキングは以下の結果でした。
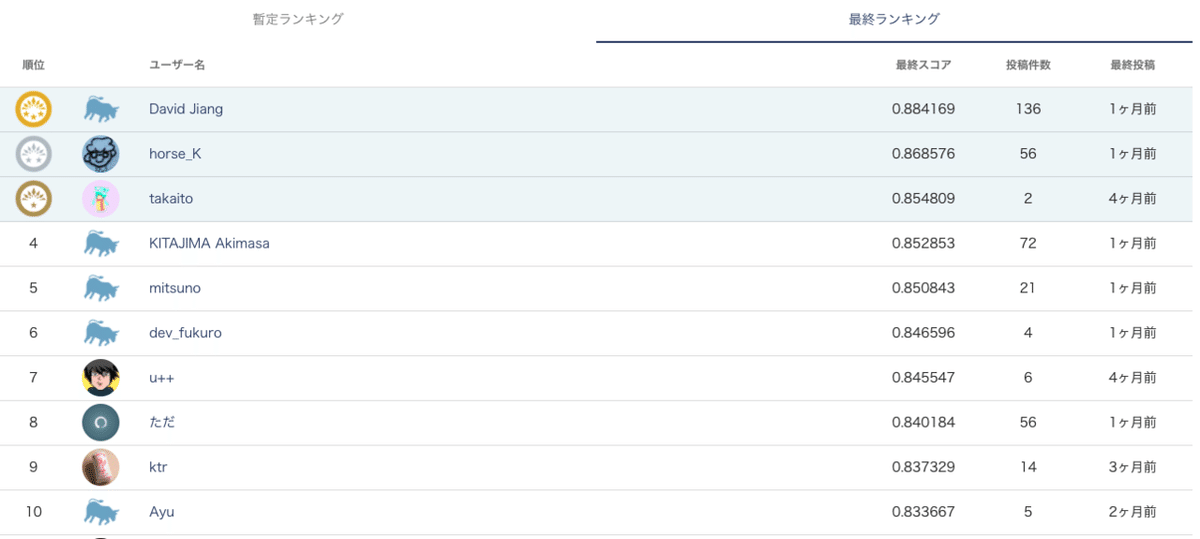
1位のDavid Jiangさんは暫定ランキングでも1位、いずれのランキングでも2位以降に2ポイント程度の差をつけての優勝となりました。
上位ソリューションのモデルは、BERTを使ったモデル and/or flairを使ったモデルが占める結果となりました。
BERTが単語ベースの言語モデルを使って単語の分散表現を獲得するのに対して、flairは文字ベースの言語モデルを使った単語の分散表現を獲得し、それを使ってラベルを予測するという違いがあります。
今回は見事優勝されたDavid Jiangさんのソリューションが、BERTモデルとflairモデルの両方を作成、stackingするものでしたので、こちらを中心に紹介します。
ソリューション詳細を確認されたい方は、以下を参照ください(Nishika会員登録→コンペ参加が必要です)。
1位: David Jiangさんソリューション
2位: horse_Kさんソリューション
3位: takaitoさんソリューション
1. Augmentation
まず、固有表現抽出タスクでよく行われる手法である、固有表現を他の名前で置換し、Data Augmentationを行います。
具体的には、人名・企業名をaugmentationの対象とし、人名18678件、企業名3030件を収集・生成し、置換しています。
本来は1つの判例の中では同じ名前で置換すべきですが、多様性を考慮し敢えてそのような制約は設けなかったとのことでした。
ただ、今回のタスクではAugmentationによるスコア上昇の効果はさほど大きくなかった(+0.01程度)ようです。
逆に2位のhorse_Kさんは、ラベルの含まれていないセンテンスを学習データからバッサリ削除し学習の効率化を図ったが、覚悟していたスコアの悪化はなく、むしろ若干改善した、とのことでした。
運用面を考えると、特に本タスク・本データセットにおいては学習の効率化はとても重要ですので、参考になる試みでした。
2. Modeling
各モデルで、11のラベルを予測していきます(11: 'mask', 'O', 'B-TIMEX', 'I-TIMEX', 'B-PERSON', 'I-PERSON', 'B-ORGFACPOS', 'I-ORGFACPOS', 'B-LOCATION', 'I-LOCATION', 'B-MISC', 'I-MISC')。
まず、以下6つのBERT学習済みモデルによる予測を行います。
Hugging Faceが提供した4つのモデル
• cl-tohoku/bert-base-Japanese
• cl-tohoku/bert-base-japanese-whole-word-masking
• cl-tohoku/bert-base-japanese-char
• cl-tohoku/bert-base-japanese-char-whole-word-masking
情報通信研究機構が公開した2つのモデル
• NICT_BERT-base_JapaneseWikipedia_100K
• NICT_BERT-base_JapaneseWikipedia_32K_BPE
一方で、flairによる文字列ベースのembeddingで4096次元の分散表現を獲得しておきます。
これを、以下のような形でStackingし、最終的な予測結果を獲得しています。

このようなStackingを選んだ背景として、kaggleのTweet Sentiment Extractionコンペ1位解法で10数個のBERTモデルのstackingを行っていたこと、また過去のNLPコンペで文字列ベースのembeddingを追加することで精度向上に成功していた解法があったことから、flairの採用に至ったとのことでした。
また細かいところでは、Multi-Sample Dropout(dropoutを変えて損失を計算し、最終的な損失は平均をとる)も採用されていました。
尚、今回のデータでは、pdfをテキスト化する処理の過程で必ずしも形態素解析が適切に行えないデータができていた(例:裁判官の名前がpdf上で「山 田 太 郎」と表記されていると、形態素解析の結果['山', '田', '太', '郎']となる)こともあり、文字ベースのembeddingを行うflairを採用していた方が多かったようです。
また、実験の結果効果が出なかった試みの1つとして、提供されたデータ以外のマスク済み判例を教師データとして、BERTモデルを追加学習した場合、スコアが下がったとのことでした。
これは、追加したデータがマスク済みだったため、抽出したい個人情報が含まれておらず、逆効果だったのではないかと推察されています。
3. PostProcess
今回はBIOタグの形式でラベリングしているので、予測の結果Iタグから始まってはいけないという制約があります。これを後処理にて対応しています。

尚、別の入賞者から、後処理についてはもっと色々できたかもしれない、という意見もありました。
BIOタグに関する補正でも、上記以外に、B-PERSON, B-PERSONと予測した結果をB-PERSON, I-PERSONに補正することが考えられますし、
ラベル付した結果を抽出しPERSONとして「佐藤」という名前が抽出されていたら、ラベル付しなかった箇所に「佐藤」が含まれていないか再確認する、というアイデアもありました。
4. Evaluation
単独モデルも含め、各モデルのCV、暫定スコア、最終スコアは以下の通りです。NICT-100KのBERT事前学習モデルなど単一でもスコアの高いモデルがあり、最終サブミットの選択は悩まれたようです。

最後に、最終サブミットについて、全てのテストデータに対する予測結果を固有表現の種類別に見てみると、以下の通りとなりました。

PERSON(人名)、ORGFACPOS(組織名・施設名・役職名)の抽出精度は8~9割と非常に高く、LOCATION, TIMEX, MISCの3種類は低くなっています。地名や時間については教師データも少なく、各語が個人の特定につながる情報なのかの判断ができるに至らなかったと考えられます。
おわりに
まず、個人情報の抽出モデルとして、非常に精度の高いソリューションを構築いただけたと考えております。
後処理のテクニックも含め、精度向上の余地が十分残されている点も可能性を感じる結果となりました。
一方で、コンペ開催側の悩みとしては、共通の評価指標の元で競っていただくにあたり、spacy, ginzaにより事前にtokenizeしたtokenごとの予測結果を出していただくよう投稿データのフォーマットを規定している点が、予測結果提出における制約となっている点が申し訳なく、一方で解決策が思いつかない点でした(もしより良い案があればご教示いただけると大変嬉しいです)。
ともあれ、ある程度リソースをかけて作成したデータセットを200名強の方に触っていただき、またモデル構築に取り組んでいただいた点、非常に嬉しく思っております。
また、今回のソリューションはそもそも実用価値が高いものと考えておりますので、法曹界に対して実用可能性についても働きかけていきたいと考えています。
改めまして、コンペにご参加いただいた皆様、ありがとうございました!
【新コンペのご案内】
現在Nishikaでは、中古マンション価格予測というコンペを開催しています。
実際の日本全国の中古マンションの売買取引データをもとに、将来取引されるマンションがどの程度の価格となるのかを予測するというものです。
本記事執筆時点の2/28時点で、既に500名弱の方にご参加いただき、活発な上位争いが行われています。
一方で、データおよびタスクは非常に平易で、かつ内容的にも皆様の多くに馴染み深いタスクとなっているかと思います。
奮ってご参加いただければと思います!

この記事が気に入ったらサポートをしてみませんか?