
公共交通データの更新頻度を1.5倍にするために取り組んだこと

はじめに
こんにちは、「Masaヤン」と「くるふと」です。ナビタイムジャパンで公共交通データの作成・運用改善の業務を担当しています。
私たちが日頃運用しているプロダクトの1つに「公共交通データ」というものがあります。
年間約150回程更新を行っていたのですが、様々な改善の取り組みにより、更新頻度を1.5倍にすることができました。
本記事では公共交通データの更新頻度を上げるために
チームとしてどのような取り組みを行ったかについてご紹介します。
1.公共交通データについての概要
まずは私たちのチームで運用している公共交通データについて簡単にご紹介します。
公共交通データとは、公共交通(鉄道/バス/空路/航路)の時刻表・経路案内に必要な情報です。具体的には、
駅/バス停名称
駅/バス停の位置情報
時刻表情報(便名/行先/時刻…etc)
運賃/料金情報
などの公共交通に関する様々な情報を含んだデータのことを指します。
公共交通データはナビタイムジャパンが提供している多くのサービスから参照される重要なデータであるため、
「公共交通データの品質が高い状態を維持する」ことが
日頃から運用を行っている私たちのチームの重要なミッションです。
2.なぜ更新頻度を上げようとしたのか
データの品質を上げたい
私たちのチームが達成すべきミッションの1つである「公共交通データの品質向上」において、更新頻度が高いということは重要な指標であると考えました。
ナビタイムジャパンがユーザの皆様から期待されていることの1つに「正しい情報をいつでも得られる」ことがあります。
具体的には「臨時ダイヤもちゃんと反映されているよね」「ダイヤ改正/運賃改定はちゃんと間に合っているよね」といった、移動の意思決定に関わる正しい情報をいつでも取得できることが期待されてます。
ところが現実世界では時々刻々と新しい臨時ダイヤ等の情報が発表されており、その1つ1つを期日までにユーザの皆様に届けるためには高頻度でのデータ更新が必要不可欠です。
公共交通データ更新頻度を増やす以前は、
「運行日直前に発表された臨時ダイヤに対応できない」
「せっかくリリースしても既に古い情報になってしまっている」
等データの品質に関わる課題を実際に抱えていました。
デプロイ頻度と品質の関係について、質の高いプロダクトを提供するチームはデプロイの頻度が高いことが統計的に言われています。
「State of DevOps 2021」でも以下のように言及されています。
Deployment frequency
Consistent with previous years, the elite group reported that it routinely deploys on-demand and performs multiple deployments per day. By comparison, low performers reported deploying fewer than one time per six months (less than two per year), which is again a decrease in performance when compared to 2019. The normalized annual deployment numbers range from 1,460 deploys per year (calculated as four deploys per day x 365 days) for the highest performers to 1.5 deploys per year for low performers (average of two deploys and one deploy). This analysis approximates that elite performers deploy code 973 times more frequently than low performers.
要約しますと、「ハイパフォーマンスなチームは1日の間に複数回デプロイを行っており、年間当たりのデプロイ回数がローパフォーマンスのグループと比較すると973倍であったと報告されている」と言及されています。
従って私たちのチームでは、世の中の変化(臨時ダイヤ・ダイヤ改正・運賃改定等)に追従し、可能な限り素早く(高頻度で)ユーザのみなさまに正しい情報を届けることで「公共交通データの品質向上」は達成できると考えました。
3.現状の可視化
更新回数を増やすにあたり、まずは現状の更新フローを振り返り更新回数を増やす妨げとなっている箇所は無いか可視化するところから始めました。
バリューストリームマッピング(VSM)
VSMというフレームワークによって1回の更新作業の中でのボトルネックの箇所を特定しました。
VSMについての詳細は本記事では割愛しますがイメージについて簡単にご紹介します。
以下の画像のように更新作業中の各ステップの要素を洗い出します。
作業者を含む関係者の人数
実際に手を動かしているプロセスタイム(PT)
PTに待ち時間を加えた全体のリードタイム(LT)
LT = PT + 待ち時間
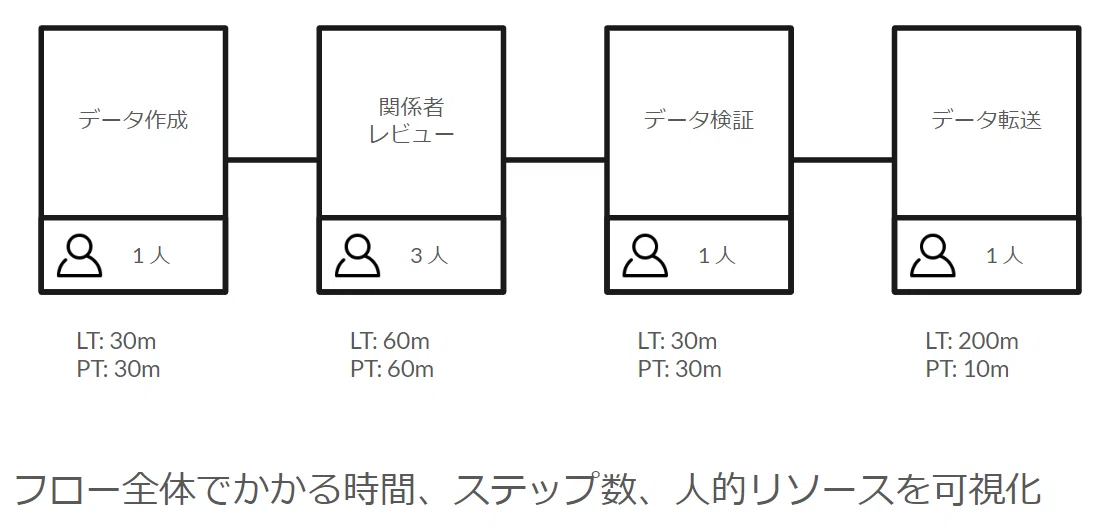
※画像はイメージ図のため実際のものとは異なります
こちらを作業の順番通りに繋いだ時に全体としてどれだけの時間がかかっており、またどのステップがボトルネックとなっているのかを特定するワークがいわゆるVSMです。
VSMについて詳しく知りたい方は以下の記事が分かりやすく解説されていますので併せてご参照ください。
VSMを行った結果私たちのチームでは以下の3点が更新回数を増やすために解決すべき課題であることが特定できました。
特定した課題
複数のチームを跨るフローを改善する際の対応コスト
異なるチームが管理しているシステム間連携の仕様の決定に時間がかかる
連携するシステム間の改修自体にも対応コストがかかる(ものによっては同時に改修する必要があるため)
上記を行う上でのチーム間のコミュニケーションコスト
チーム毎に普段使用している技術/ノウハウにギャップがあるため
ノウハウの浸透に時間がかかる
データ転送フローの処理時間
容量の大きいデータを転送する処理の時間
複数のサービスから参照されるデータであるため、データを配置する環境の数が多い
人による手動のオペレーションが多い
扱うデータが複雑である故に人による判断/手作業が必要であった
異なる種類やフォーマットを持つデータの扱いが難しく、変換/転送処理の自動化が難しかった
4.ボトルネック解消のため行ったこと
VSMで特定したボトルネックに対して、それぞれどのように解決のアプローチを行ったのか記載します。
複数チーム間でのコミュニケーションコスト
【改善特化チームの誕生】
公共交通データと一言に言いましても鉄道/バス/海外の交通データ等交通機関によって別のチームがそれぞれの担当箇所のデータを作成し、最終的に1つのデータとして世に送り出しているため、
更新フローのような横断的な改善の取り組みを進める上でコミュニケーションコストがかかってしまうという課題がありました。
コミュニケーションコストの低減を図るため、普段運用を行っている各チームから数人ずつ出し合い「更新フローの改善を行う」という共通の目的を持ったチーム(リリース改善T)を結成することになりました。
【週次の振り返り・FB】
上記で結成されたリリース改善Tでは毎週定例を行い、
更新作業中に感じた改善できそうな箇所、その時に率直に感じたことの相互FBを行いました。
負担を感じる人が多い作業箇所や作業中にエラーが発生する頻度が高いポイントの特定ができ、次の改善アクションに繋げることがスピーディーにできるようになりました。
筆者(Masaヤン)もリリース改善Tのメンバーなのですが、チームが結成される前と比べて各更新作業のステップに対する理解や運用改善のノウハウを習得でき大きく成長できたなと感じております。
データ転送フローの処理時間短縮
【冗長な転送フロー/手順の自動化】
先述したVSMにより、実は並列実行可能な作業が存在していたり、自動化できるが人手で行っていた作業を可視化することができたため、そういった改善可能なポイントをタスクとして起こし、徹底して自動化/最適化を図りました。
不要な転送経路の削除
いくつかのサーバを経由して転送を行っていたフローの経由サーバを無くす
複数の転送処理の並列化
データの圧縮アルゴリズムを用いたデータ転送への切り替え
お試しで更新頻度を増やしてみる
いくつか改善施策を実施後、
以下の効果を期待して2週間程度の期間限定で更新頻度を上げてみるという取り組みを行いました。
実施した改善施策の効果測定
実はまだ気付いていない新たな課題が発見する
課題だと思っていたが実際にやってみたらそれほど気にならないことを明らかにする
お試し期間の振り返りの中で改善施策の追加・優先度の見直しを行い、
チームとして真に解決すべき課題を認識を合わせながら改善に取り組み、改善が完了したら再び効果測定、
といった具合にチームとして改善に取り組むリズムを作ることができました。
5.更新頻度を1.5倍にできました!!
ここまで記載してきた取り組みを通して改善を継続したことで、重大なインシデントや作業者の負担を増やすことなく、
公共交通データの更新頻度を正式に1.5倍に増やすことができました!

本記事で紹介した取り組みはあくまで一例ですが
日々業務の改善に取り組む読者の皆様の少しでもお役に立てたならば嬉しいです、最後までお読み頂きありがとうございました。