
フロントエンドに完結したO/Rマッピングを考える

こんにちは、考える人です。
ナビタイムジャパンでWebツール開発を担当しています。
これまで地図、社内向けAPI基盤、乗換経路探索エンジンの研究開発に着手してきましたが、今年度からフロントエンド開発部門に異動しました。
開発中のWebツールはデータの編集を主な役割としています。
取り扱うデータはリレーショナルデータベース(RDB)と親和性のある形式であり、データ操作の簡単化のためにオブジェクトとRDBとの関連付けをする「O/Rマッピング」導入のモチベーションがありました。
その技術要素の検討や、導入後に実施したこと等を中心にお届けします!
登場する技術 : Vue (ver3) / Nuxt (ver3) / Pinia / Pinia ORM / Vitest
動機
冒頭で触れたように、私はデータ編集を主な役割とするWebツール開発をしています。今回は、編集操作単位で通信を発生させないことを要件としており、データの保持や操作がフロントエンドで完結できる事を重視しました。
データの保持に関しては、ストアと呼ばれる状態管理用のオブジェクトを用いることがあります。
Webページを構成している各パーツからストアにアクセスして値を利用したり、ストアの状態を更新します。
あらゆる部分から参照でき便利である一方で、多数のモデルデータを連携させるなど複雑なデータを取り扱う場合には、更新処理や取得処理も煩雑になります。これをうまく制御・活用できる事も重要です。
開発しているWebツールは、 VueをベースとしたNuxtを利用しています。そのため、 Nuxt と親和性のあるライブラリの選定も必要です。
以上のモチベーションから、Vueのストアライブラリである Pinia と、Pinia で取り扱うストアに対して ORM によるマッピングを可能にするプラグインである Pinia ORM を利用する案が出てきました。
導入によって出来ること
Pinia ORM を導入したことによって、データの取得や追加、更新、削除などの操作をスムーズに行うことができました。今回は2つのモデルを例として紹介していきます。
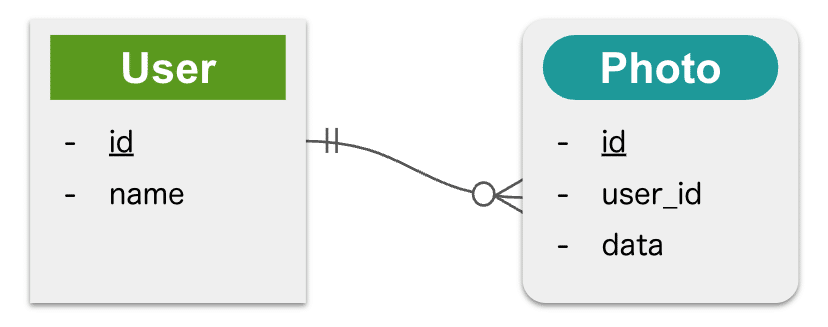
Pinia単体であらわす場合
Pinia においては以下の項目をストアとして定義します。
保持したいデータ(state)
データの取得方法(getters)
データの操作方法(actions)
上記のモデルを表現するために、ストアには User のリスト (users) と、Photo のリスト (photos) が保存されています。
データ操作として、ユーザIDが 1 であるデータを削除する場合は、users から id が 1 であるデータを探して削除したのち、 photos からも user_id が 1 であるデータを探して削除します。

これをせず、 users からのみデータを削除してしまうと、どの User にも紐づかない Photo データが永遠に残り続けてしまうなどの事象が生じて、サービス運用に支障が出るかもしれません。
このように、データの整合性を保つことに注意を払いながらデータ操作を行うプロダクトコードを作成することが要求されます。
それでは、 Pinia ORM を用いる場合、どのようになるか見ていきましょう。
手順1:モデル作成
User と Photo のモデルを作成します。 User は複数の Photo を持ちます。
User から Photo に対して、 HasMany のリレーションを貼り、削除時の挙動として OnDelete('cascade') を指定します。
// ~/models/User.ts
// Photo のモデル定義
export class Photo extends Model {
static entity = 'photo'
@Uid() declare id: number
@Attr() declare user_id: string
@Attr(null) declare data: string | null
}
// User のモデル定義
export class User extends Model {
static entity = 'user'
@Uid() declare id: number
@Attr("") declare name: string
@HasMany(() => Photo, 'user_id')
@OnDelete('cascade')
declare photos: Photo[]
}手順2:モデルへのアクセス部分
このモデルの (PiniaORMにおける) Repository オブジェクトに対してクエリを実行する処理を書きます。
今回は後続の手順で利用する削除処理と、もう一例としてデータ追加処理と記載します。
// ~/repositories/user.ts
// データ追加処理
export function addUser(id: number, name: string) {
// usePinaRemo(モデル)の指定で、PiniaORMにおけるRepositoryオブジェクトを取得できる
return usePinaRepo(User).save({ id, name })
}
// データ削除処理
export function deleteUser(id: number) {
return usePinaRepo(User).destroy(id)
}手順3:データの利用・操作部分
今回はテストコードを介して削除操作の挙動を紹介します。
// ~/tests/user.spec.ts
describe('delete', () => {
it('指定したユーザIDに紐づくPhotoも一緒に削除できる', () => {
// テストデータの登録
usePinaRepo(User).save([
{ id: 1, name: 'taro' },
{ id: 2, name: 'jiro' },
])
usePinaRepo(Photo).save([
{ user_id: 1, data: 'BASE64_DATA_A' }, { user_id: 1, data: 'BASE64_DATA_B' },
{ user_id: 2, data: 'BASE64_DATA_X' }, { user_id: 2, data: 'BASE64_DATA_Y' },
])
// 削除前の確認
expect(usePinaRepo(User).all()).lengthOf(2) // taro, jiro の2つ
expect(usePinaRepo(Photo).all()).lengthOf(4) // A, B, X, Y の4つ
// 削除処理の実行
deleteUser(1)
// 削除後の確認
expect(usePinaRepo(User).all()).lengthOf(1) // jiro の1つ
expect(usePinaRepo(Photo).all()).lengthOf(2) // X, Y の4つ
})
})deleteUser(1) を実行する前には Photo は4件登録されていましたが、 実行後には User 1人分削除されるとともに、 Photo 2件が削除されています。
リレーションが正確に設定されているとき、簡単な削除操作によって削除したい対象とその対象に紐付けられたデータを、まとめて削除出来ている様子が確認できると思います。
Pinia ORM を用いない場合は、 User に対して削除処理を発行したのち、 Photo に対しても同様に削除処理をして整合性を取る必要がありましたが、それらを Pinia ORM が担ってくれています。
導入における重要なポイント3つ
Pinia ORM を導入して、実際にコードを記述していく中で、重要と感じたポイントを3点挙げます。
リポジトリパターンの導入
テストを記載すること
データ保持のケアをすること
実は提示した3点はいずれも、通常の開発時にも有効な方法です。 Pinia ORM を取り扱う上でどのように働いたかも併せて紹介します。
その1:リポジトリパターンの導入
データの取得には、Pinia ORM から提供されているAPIを用います。
もちろん、コンポーネントから直接APIを叩いてデータを用意する方法を取ることも可能です。ただし、今回はデータ仕様が変更される場合のことを考慮して、コンポーネント層とモデル層が結合しないような設計が必要でした。
そこで、デザインパターンとしてリポジトリパターンを採用し、コンポーネント層とモデル層が直接結合しないようにしました。

Pinia ORM においては、リポジトリ層にすべての取得クエリや更新クエリが記述されることになります。
クエリの記述にはある程度の学習量を要求されますが、切り分けられていることによって、開発タスクの内容によって学習量を調節できます。リポジトリ層を含まない単純なコンポーネント開発タスクを、新規参入メンバに振りやすくなるなどの効果がありました。
また、コードが整理されて再利用しやすくなり、テストもしやすくなります。
その2:テストを記載すること
ストアを利用するうえで、データ取得や更新処理の成功を確認したり、ストアの状態を確認したりする事は大切です。しかし、実際の画面を通して確認を行うのは狂気の沙汰でございましたので、テストコードに頼ることにします。
幸い、上述の通りリポジトリパターンの導入により、テスト対象がリポジトリ層にまとまっているので、これを対象にテストコードを記述できます。
ORM を扱う上で、モデルのリレーションを正しく定義することは(学習レベルの向上により解決できる事項ではありますが)障壁になりやすく、 Pinia ORM においても同様でした。
テストを書きながらモデルの定義をしていく事で、トライアンドエラーを細かく繰り返しながら効率良く学習を進めることができました。
また、テストを書いていて良かった点として、返却物の細かい挙動差分に気づけた点が挙げられます。
以下に、2つのデータ取得処理があります。一方は返却物を書き換えた際、その変更がストアにも反映されますが、もう一方は返却物を書き換えても何も起こりません。
// 単純に User のデータを返す
export function getUser(id: number) {
// この返却物は、変更を加えると副作用を及ぼす
return usePinaRepo(User).where('id', id).first()
}
// User データの photos に Photo データが格納されたデータを返す
export function getUserWithPhoto(id: number) {
// この返却物は、変更しても副作用がない
return usePinaRepo(User).with('photos').where('id', id).first()
}テストの導入に至っては、 Nuxt からは AutoImport設定 で参照できていた Pinia ORM が、 Vitest 経由で参照できないなどの障壁もありました。
これについては、以下のように unplugin-auto-import を用いて解消できました。
// vitest.config.ts
import AutoImport from 'unplugin-auto-import/vite'
export default defineConfig({
plugins: [
AutoImport({
imports: [
// presets
'vue', 'vue-router', 'pinia',
// ここで、 Pinia ORM の useRepo を利用できるようにする
{
'pinia-orm': [
['useRepo', 'usePinaRepo'] // import { useRepo as usePinaRepo } from 'pinia-orm'
]
}
],
})
],
});その3:データ保持のケアをすること
Webツール上でO/Rマッピング処理を使うということは、ページを閉じたり、リロードしたりするときに、ストアのデータが消去されてしまいます。
操作ミスなど不慮の事故で作業データが消えないようにするために、データをどのように保持するかの戦略を考える必要があります。
Pinia には、データの永続化のためのプラグイン (pinia-plugin-persistedstate) があります。これを使うことによって、ページリロードの際にストアを維持するなどの仕組みを利用できます。Pinia ORM でも、モデル毎に永続化設定を定義することが可能です。
ここで注意しなければならないのは、永続化のためにローカルストレージを用いる場合、容量上限が決まっている (例えば 5MB など。ブラウザ依存) ことです。
O/Rマッピングを要するデータにおいては、そのデータ容量も相応に大きくなる可能性が考えられます。格納するデータ量の上限を定めることが出来ない場合には、永続化ではなく dirty フラグを用いた離脱制御などを考えたほうが良いかもしれません。
まとめ
Webツールの開発において、Pinia ORM を用いてフロント側でO/Rマッピングをする様子を記述してきました。
便利な一方で、参考になる文献の量が少ない分野でもあります。そのため、利用する上で最も気をつけるべきポイントは、テストを整備して挙動を整理しながら利用することだと感じます。
たくさんの好評をいただけましたら、また Pinia ORM についての記事を書いてみたいなと思いますので、もっと知りたい方はぜひスキのボタンを押してお帰りください!