
AWS EC2上でのパフォーマンス測定

こんにちは、フジクジラ🐋です。ナビタイムジャパンで乗換検索のアルゴリズム開発を担当しています。
今回は、開発したプログラムをAWS EC2上でパフォーマンス計測しようとした際に直面した、パフォーマンスの測定値がばらつくという問題についてお話したいと思います。
背景
日々の開発業務におけるパフォーマンス測定
私の所属しているチームでは、日々、乗換検索の使い勝手を向上するための開発を行っております。たとえば、新しい機能の追加や、今まで出せていなかったより良い経路を出すための改善などです。
改修の中には、乗換検索のパフォーマンス(乗換経路が見つかるまでにかかる時間)に影響を与えるものもあります。たとえば、以下のようなケースがあります:
新しい機能を追加するにあたって共通部分のロジックに手を入れたら、既存の機能のパフォーマンスが悪化してしまった。
ユーザビリティ向上のためにパフォーマンスの改善をしている。
こういったときに、「リリースしてみたらパフォーマンスが大幅に悪化してしまった」「改善したつもりがリリースしてみたらほとんど改善効果がなかった(あるいは、むしろ逆効果だった)」となっては困ります。そこで、基本的にはリリースするよりも前に、開発したプログラムを対象として、どの程度のパフォーマンスが出るか測定を行っています。
パフォーマンス測定の手順と環境
私たちのチームでは、以下のような手順で乗換検索のパフォーマンスを測定しています:
AWS EC2のインスタンスを起動し、その上で乗換検索を行うためのサーバープログラムを起動
別のマシンからそのインスタンスにリクエストを投げて、レスポンスタイム等を計測
昔は、同様の測定をオンプレ環境上でやっていましたが、近年はクラウド環境での測定に移行しました。クラウド環境上でパフォーマンス計測を行うメリットとしては、以下のようなものが考えられます:
実際のサービスとより近い環境でパフォーマンスの計測ができる。
実際のサービスのほとんどはクラウド環境上で運用されているため。
パフォーマンス測定専用の環境を使い捨てですぐ作れる。
パフォーマンス測定中は、測定値に影響を与えないように、できるだけ同一マシン上で他の無関係なプログラムが動いていないことが望ましい。
オンプレ環境上でパフォーマンス測定専用のマシンを用意するのはコストがかかる。
一方で、クラウド環境(AWS EC2)上でのパフォーマンス測定をある程度の期間続けてみたところ、問題になってきたのが、パフォーマンスの測定値にばらつきがあることでした。
具体的には、乗換検索のアルゴリズムを全く変更していなくても、測定した日によって、あるいは測定するインスタンスによって5%前後のパフォーマンス差がある、といった状況でした。
どの程度のばらつきまで許容できるかは難しい問題です。たとえばパフォーマンスの改善について言えば、2~3%程度の小さな改善を何個も積み重ねて大きな改善を達成する、ということも多いです。そうしたとき、そういった小さな改善に本当に効果があるのか、逆効果でないのか、ということを正しく測定することを考えると、5%の誤差は少々厄介でした。
そこで、こういった測定値のばらつきの原因がどこにあるのかについて、調べた内容と、いくつか参考にした文献についてご紹介していきたいと思います。
注意点
パフォーマンスに影響を与える要因は、測定対象の性質(CPUやI/Oなどのどこがボトルネックなのか)や、使用するEC2のインスタンスタイプなどに大きく依存します。また、許容できるばらつきの大きさも状況によって全く異なります。
あくまで「こういうこともある」という一例として参考にしていただければと思います。
EC2上でのパフォーマンスに影響を与える要因
CPUの違いによるパフォーマンスのばらつき
調査を開始して最初に分かったことは、同じインスタンスタイプでもインスタンスによってCPUが異なり得ることでした。
AWSのインスタンスタイプについてのドキュメントを見ると、各インスタンスタイプで使用するCPUが記載されています。よく見ると、いくつかのインスタンスタイプで、複数のCPUが列挙されていることに気付きます。
たとえば、
M5, R5
Skylake 8175M または Cascade Lake 8259CL
C5
12xlarge、24xlarge、metal
Cascade Lake 8275CL
それ以外
Cascade Lake 8223CL または Skylake 8124M
ただし、C5について、8275CLは12xlarge以上のインスタンスでのみ使用されると書かれていますが、実際には12xlarge未満のインスタンスタイプでも8275CLが使われているようです。
以下、実際にc5.largeのインスタンスを起動して、CPUを確認してみます。CPUを確認する方法はいくつかありますが、ここではlscpuコマンドを使います。
$ lscpu複数台起動して試したところ、以下の2種類の結果が得られました。
1種類目:

2種類目:
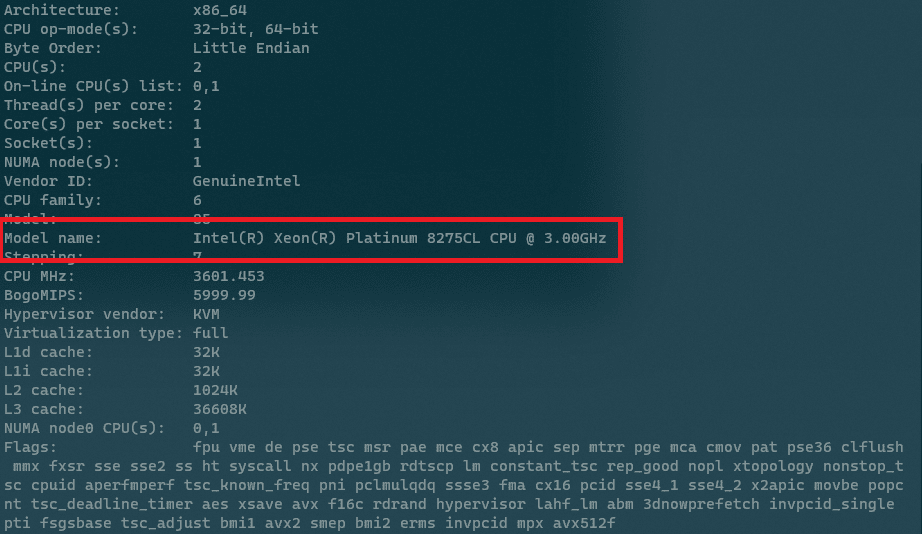
たくさん項目が出ていますが、赤枠で囲った"Model name"に着目すると、1つ目が8124M、2つ目が8275CLになっていることが分かります。L3キャッシュのサイズなどに違いがあることも分かります。
(公式ドキュメントでは、c5系にはもう一つ、「Cascade Lake 8223CL」というCPUも使われると記載されています。実際に自分もこのCPUが使われたインスタンスを見たことはあるのですが、他の二つに比べると圧倒的に少ない印象です。今後のことや他のリージョンのことは分かりませんが、少なくとも2022/8時点の東京リージョンでは比較的レアなCPUなのかもしれません。)
実際に、8124Mと8275CLの二つのCPUで、どの程度パフォーマンスに違いがあるのでしょうか。
試しに、sysbench(https://github.com/akopytov/sysbench)というツールを使用して、ベンチマークを実行してみました。
sysbenchのインストール方法は上記のリンク先に記載されています。今回はAmazon Linux 2を使用していたので、以下のコマンドでインストールできました:
$ curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash
$ sudo yum -y install sysbenchその後、以下のコマンドでCPUに対するベンチマークを実行できます:
$ sysbench cpu run以下は結果の一例です:

いくつか値が出ていますが、赤枠で囲った"events per second" の値に着目してみます。値が大きいほど速いです。
CPUとパフォーマンスの相関を調べるために、合計20台のc5.largeのインスタンスを起動し、それぞれのインスタンスで20回ずつsysbenchを実行しました。インスタンス毎の平均値を図示したのが下記のグラフになります。左側の10個(#00~#09)が8124M、右側の10個(#10~#19)が8275CLのインスタンスでの結果です。

グラフから明らかなように、CPUとsysbenchのスコアにはっきりと相関があります。大体6%くらい、8275CLのほうが8124Mよりもスコアが良いようです。
ベンチマークの中身はこちらから確認できます。単純な素数の数え上げのようです。
乗換検索の中で素数の数え上げを行っているわけではないので、上記の6%という値はあくまで参考として、実際に自分たちが開発しているプログラムのパフォーマンスに、CPUの違いがどの程度効いてくるかは計測するしかありません。私たちの乗換検索のエンジンの場合は、CPUの違いによるパフォーマンス差分は5%前後でした。
注意点として、CPUはインスタンスを再起動すると変わり得ます。逆に言えば、インスタンスを再起動するだけでCPUを別のものにできるので、希望のCPUになるまで何度か再起動を繰り返す、といったことも可能です。
同じCPUのインスタンス間でのパフォーマンスのばらつき
CPUだけでインスタンス間のパフォーマンス差を説明できれば良かったのですが、実際に乗換検索のパフォーマンス測定結果を分析してみると、CPUが同じインスタンス間でもパフォーマンスが僅かに異なることが分かりました(大きさとしてはCPUによる影響よりは小さく、最大で2%前後)。一方で、上記のsysbenchの結果は同一CPUのインスタンス間ではほぼ一定ですので、ここはsysbenchと乗換検索との違いになります。
こちらについては、調査したもののはっきりした原因はつかめていませんが、次の項で紹介する論文でも同じような事象が確認されています。そちらの論文では、他のクラウドユーザーとのリソース競合(resource contention)によるものだと推測されています。
文献紹介
EC2環境でのパフォーマンスのばらつきについて調べていく中で、いくつか同じようなモチベーションで調査している文献があり、大変参考になったので、その中から2つほど、簡単に紹介させていただきたいと思います。
An Investigation on Public Cloud Performance Variation for an RNA Sequencing Workflow
一つ目は、RNA Sequencingを行うプログラムを題材に、クラウド上でのパフォーマンスの変動について調査した論文です。
EC2のc5.2xlargeとc5a.2xlargeのインスタンスについて、プレイスメントグループや専有ホスト(Dedicated Host)がパフォーマンスに与える影響などを調査しています。
この論文では、CPUの違いやクラウド上の他ユーザーとのリソース競合(resource contention)などがインスタンス間のパフォーマンスのばらつきの要因だとしています。
特にTable 3にあるように、専有ホストを使って他ユーザーとのリソース競合をなくすことで、通常と比べて平均で8.6%もパフォーマンスが速くなったとしています。
また、Figure 6にあるように、同じインスタンスでパフォーマンス測定を24時間繰り返したとき、時間的にパフォーマンスが変動していたというのも興味深いです。
Reducing Variability in Performance Tests on EC2: Setup and Key Results
二つ目は、MongoDBのパフォーマンスチームによる記事です。
日々のパフォーマンステストにおいて、結果のランダムなばらつきがあったので、それをどう抑えたかという記事です。
(乗換検索のプログラムとは異なり)IOの占める割合が多いパフォーマンステストのようです。
その点では、この記事に書かれていることがそのまま参考になるわけではありませんでしたが、"Assume nothing. Measure everything."を信条として、全ての仮説や前提について測定結果から確認していく姿勢は見習いたいと思い、紹介させていただきました。
結論の詳細は、さらに以下3つの記事に分割してまとめられています。(詳細は割愛します):
3つのうちの1つ目の記事にもある通り、MongoDBのパフォーマンステストにおいてはインスタンスによるパフォーマンスの違いはなかったとのことでした。ただし、ハードウェア専有インスタンス(dedicated instance)を使用しているとのことで、リソース競合がなかった可能性もあります。筆者自身、以下のように述べています:
Note that it is completely possible that this result is specific to our system. For example, we use (and pay extra for) dedicated instances to reduce sources of noise in our benchmarks. It's quite possible that the issue with noisy neighbours is real, and doesn't happen to us because we don't have neighbours. The point is: measure your own systems; don't blindly believe stuff you read on the internet.
EC2上でのパフォーマンス測定値のばらつきを抑えるために
以上を踏まえて、EC2上でのパフォーマンス測定での測定値のばらつきを抑えるためには、以下のような方法が考えられます:
多数のインスタンスで測定して平均する。
身も蓋もないですが、ある程度多数のインスタンスで測定して結果を平均することでばらつきはある程度、ならされると思われます。
測定に使うインスタンスのCPUを揃える。
c5など一部のインスタンスタイプでは、インスタンスによりCPUが異なり、それがばらつきの原因になり得ます。
インスタンスを再起動することでCPUが変わりうるので、目的のCPUになるまでインスタンスの再起動を繰り返す、といったことが可能です。
同一CPUでも多少のパフォーマンス差分がありますが、CPUによる差分よりはかなり小さいです。
一つのインスタンス上で繰り返し測定する。
別々の日に(別インスタンスでor同一インスタンスを再起動して)測定した結果同士を比べる場合には使えませんが、単発で複数の対象のパフォーマンスを測定して比較したい場合は、同一インスタンス上で連続で測定することで、インスタンス間のパフォーマンス差分の影響を気にせず測定が可能です。
ただし、上で紹介した論文でも触れられているように、同じインスタンスでもパフォーマンスに時間的な変動がありうることには注意が必要です。
以下は、紹介した文献に記載されていた内容で、こちらでは試していないので効果の保証はできませんが、
専有ホスト(Dedicated Host)を使用する。
EBSを使用する。(IOがボトルネックになっている場合)
一部のCPUオプションを無効化する。
終わりに
EC2上でのパフォーマンス測定時の結果のばらつきについて調査したことをまとめました。
繰り返しになりますが、何が効くかは測定対象の性質にも大きく依存しますし、使用しているインスタンスタイプなどによっても変わり得ます。
(上で引用したMongoDBのブログにも記載がある通り)最終的にはそれぞれのシステムで何がばらつきの要因になっているか計測することをお勧めいたしますが、ここで書いたことが計測や要因調査の参考になれば幸いです。